
Relationale Datenbanken reichten lange Zeit aus, um kleine oder mittlere Datensätze zu verarbeiten. Die enorme Wachstumsrate der Daten macht den herkömmlichen Ansatz zum Speichern und Abrufen von Daten jedoch nicht durchführbar. Dieses Problem wird durch neuere Technologien gelöst, die Big Data verarbeiten können. Hadoop, Hive und Hbase sind die beliebten Plattformen für den Betrieb dieser Art großer Datenmengen. NoSQL oder nicht nur SQL-Datenbanken wie MongoDB bieten einen Mechanismus zum Speichern und Abrufen von Daten im Verlierer-Konsistenzmodell mit folgenden Vorteilen:
- Horizontale Skalierung
- Höhere Verfügbarkeit
- Schnellerer Zugang
Das MongoDB-Entwicklungsteam hat kürzlich den MongoDB Connector für Hadoop aktualisiert, um eine bessere Integration zu erzielen. Dies erleichtert Hadoop-Benutzern Folgendes:
- Integrieren Sie Echtzeitdaten von MongoDB in Hadoop für umfassende Offline-Analysen.
- Der Connector macht die analytische Leistung von Hadoops MapReduce für Live-Anwendungsdaten aus MongoDB verfügbar und steigert den Wert von Big Data schneller und effizienter.
- Der Connector präsentiert MongoDB als ein Hadoop-kompatibles Dateisystem, mit dem ein MapReduce-Job direkt aus MongoDB gelesen werden kann, ohne ihn zuvor in HDFS (Hadoop-Dateisystem) zu kopieren, sodass keine Terabytes an Daten mehr über das Netzwerk verschoben werden müssen.
- MapReduce-Jobs können Abfragen als Filter übergeben, sodass nicht ganze Sammlungen gescannt werden müssen, und sie können auch die umfangreichen Indizierungsfunktionen von MongoDB nutzen, einschließlich georäumlicher, Textsuch-, Array-, zusammengesetzter und spärlicher Indizes.
- Aus MongoDB können die Ergebnisse von Hadoop-Jobs auch in MongoDB zurückgeschrieben werden, um betriebliche Prozesse in Echtzeit und Ad-hoc-Abfragen zu unterstützen.
Anwendungsfälle für Hadoop und MongoDB:
Schauen wir uns eine allgemeine Beschreibung an, wie MongoDB und Hadoop in einem typischen Big Data-Stack zusammenpassen können. In erster Linie haben wir:
Sortieren eines Arrays im C ++ - Programm
- MongoDB als Echtzeit-Datenspeicher „betriebsbereit“
- Hadoop für Offline-Batch-Datenverarbeitung und -analyse
Lesen Sie weiter, um zu erfahren, warum und wie MongoDB von Unternehmen und Organisationen wie Aadhar, Shutterfly, Metlife und eBay verwendet wurde .
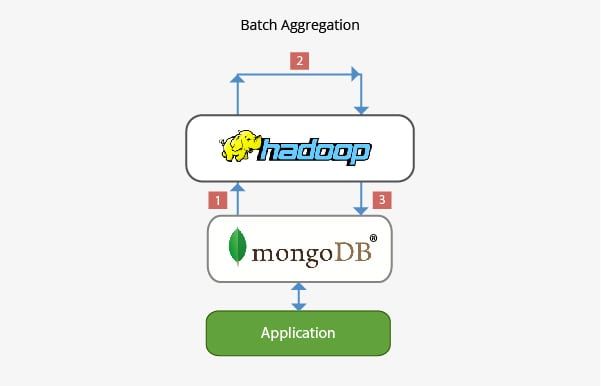
Anwendung von MongoDB mit Hadoop in der Stapelaggregation:
In den meisten Szenarien reicht die integrierte Aggregationsfunktionalität von MongoDB für die Analyse von Daten aus. In bestimmten Fällen kann jedoch eine wesentlich komplexere Datenaggregation erforderlich sein. Hier kann Hadoop ein leistungsstarkes Framework für komplexe Analysen bereitstellen.
In diesem Szenario:
- Daten werden aus MongoDB abgerufen und in Hadoop über einen oder mehrere MapReduce-Jobs verarbeitet. Daten können auch von anderen Stellen innerhalb dieser MapReduce-Jobs bezogen werden, um eine Lösung mit mehreren Datenquellen zu entwickeln.
- Die Ausgabe dieser MapReduce-Jobs kann dann zur späteren Abfrage und für jede Analyse auf Ad-hoc-Basis in MongoDB zurückgeschrieben werden.
- Anwendungen, die auf MongoDB basieren, können daher die Informationen aus der Stapelanalyse verwenden, um sie dem Endclient zu präsentieren oder andere nachgelagerte Funktionen zu aktivieren.
Anwendung im Data Warehousing:
In einem typischen Produktionsaufbau befinden sich die Daten der Anwendung möglicherweise in mehreren Datenspeichern mit jeweils eigener Abfragesprache und -funktionalität. Um die Komplexität in diesen Szenarien zu verringern, kann Hadoop als Data Warehouse verwendet werden und als zentrales Repository für Daten aus den verschiedenen Quellen fungieren.
In dieser Art von Szenario:
- Periodische MapReduce-Jobs laden Daten aus MongoDB in Hadoop.
- Sobald die Daten aus MongoDB und anderen Quellen in Hadoop verfügbar sind, kann der größere Datensatz abgefragt werden.
- Datenanalysten haben jetzt die Möglichkeit, entweder MapReduce oder Pig zu verwenden, um Jobs zu erstellen, die die größeren Datasets abfragen, die Daten aus MongoDB enthalten.
Unterschied zwischen Override und Overload
Das Team, das hinter MongoDB arbeitet, hat sichergestellt, dass es durch seine umfassende Integration in Big Data-Technologien wie Hadoop gut in den Big Data Stack integriert werden kann und bei der Lösung einiger komplexer Architekturprobleme beim Speichern, Abrufen, Verarbeiten, Aggregieren und Lagern von Daten hilft . Seien Sie gespannt auf unseren bevorstehenden Beitrag über Karriereaussichten für diejenigen, die Hadoop bei MongoDB aufnehmen. Wenn Sie bereits mit Hadoop arbeiten oder nur MongoDB abholen, lesen Sie die Kurse, die wir für MongoDB anbieten