
Apache Hive ist ein Data Warehousing-Paket, das auf Hadoop basiert und für die Datenanalyse verwendet wird. Hive richtet sich an Benutzer, die mit SQL vertraut sind. Es ähnelt SQL und heißt HiveQL und wird zum Verwalten und Abfragen strukturierter Daten verwendet. Apache Hive wird verwendet, um die Komplexität von Hadoop zu abstrahieren. Diese Sprache ermöglicht es herkömmlichen Map / Reduce-Programmierern auch, ihre benutzerdefinierten Mapper und Reduzierer anzuschließen. Das beliebte Feature von Hive ist, dass Sie Java nicht lernen müssen.
Hive, ein auf Hadoop basierendes Open-Source-Framework für die Datumslagerung im Peta-Byte-Maßstab, wurde vom Data Infrastructure Team auf Facebook entwickelt. Hive ist auch eine der Technologien, mit denen die Anforderungen bei Facebook erfüllt werden. Hive ist bei allen Benutzern bei Facebook sehr beliebt und wird verwendet, um Tausende von Jobs im Cluster mit Hunderten von Benutzern für eine Vielzahl von Anwendungen auszuführen. Der Hive-Hadoop-Cluster bei Facebook speichert mehr als 2PB Rohdaten und lädt regelmäßig täglich 15 TB Daten.
Schauen wir uns einige seiner Funktionen an, die es beliebt und benutzerfreundlich machen:
- Ermöglicht Programmierern das Einstecken von benutzerdefinierten Mappern und Reduzierern.
- Hat Data Warehouse-Infrastruktur.
- Bietet Tools zum Aktivieren der einfachen Daten-ETL.
- Definiert eine SQL-ähnliche Abfragesprache namens QL.
Anwendungsfall Apache Hive - Facebook:
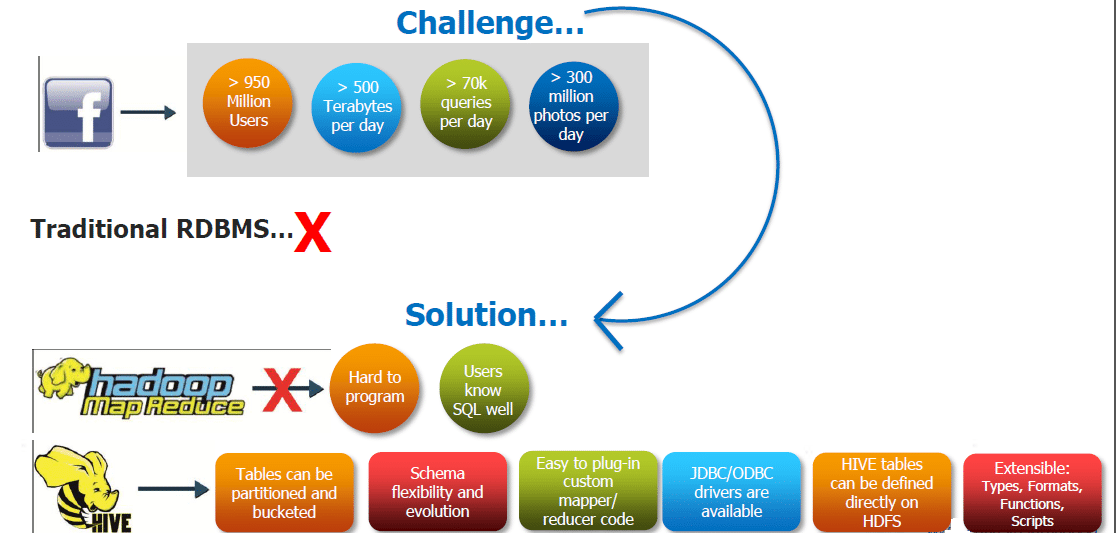
Vor der Implementierung von Hive war Facebook mit vielen Herausforderungen konfrontiert, da die Größe der generierten Daten zunahm oder eher explodierte, was es wirklich schwierig machte, mit ihnen umzugehen. Das traditionelle RDBMS konnte mit dem Druck nicht umgehen und Facebook suchte daher nach besseren Optionen. Um dieses bevorstehende Problem zu lösen, versuchte Facebook zunächst, Hadoop MapReduce zu verwenden, machte es jedoch mit Schwierigkeiten bei der Programmierung und obligatorischen SQL-Kenntnissen zu einer unpraktischen Lösung. Hive erlaubte ihnen, die Herausforderungen zu meistern, denen sie gegenüberstanden.
Mit Hive können sie nun Folgendes ausführen:
- Tische können portioniert und mit Eimern versehen werden
- Flexibilität und Entwicklung des Schemas
- JDBC / ODBC-Treiber sind verfügbar
- Hive-Tabellen können direkt im HDFS definiert werden
- Erweiterbar - Typen, Formate, Funktionen und Skripte
Hive-Anwendungsfall im Gesundheitswesen:
Wo kann man Hive verwenden?
Apache Hive kann an folgenden Stellen verwendet werden:
- Data Mining
- Protokollverarbeitung
- Dokumentindizierung
- Business Intelligence für Kunden
- Vorausschauende Modellierung
- Hypothesentest
Hive-Architektur:
Generieren Sie eine zufällige Zeichenfolge in Java
Hive besteht aus folgenden Hauptkomponenten:
- Metastore - Zum Speichern der Metadaten.
- JDBC / ODBC - Query Compiler und Execution Engine zum Konvertieren von SQL-Abfragen in eine Folge von MapReduce.
- SerDe und ObjectInspectors - Für Datenformate und -typen.
- UDF / UDAF - Für benutzerdefinierte Funktionen.
- Clients - Ähnlich der MySQL-Befehlszeile und einer Web-Benutzeroberfläche.
Komponenten von Hive:
Metastore:
Der Metastore speichert die Informationen zu den Tabellen, Partitionen und Spalten in den Tabellen. Es gibt drei Möglichkeiten zum Speichern in Metastore: Embedded Metastore, Local Metastore und Remote Metastore. Meistens wird Remote Metastore im Produktionsmodus verwendet.
Einschränkungen von Hive:
Hive hat die folgenden Einschränkungen und kann unter solchen Umständen nicht verwendet werden:
- Nicht für die Online-Transaktionsverarbeitung konzipiert.
- Bietet eine akzeptable Latenz für das interaktive Durchsuchen von Daten.
- Bietet keine Echtzeitabfragen und Aktualisierungen auf Zeilenebene.
- Die Latenz für Hive-Abfragen ist im Allgemeinen sehr hoch.
Hast du eine Frage an uns? Erwähnen Sie sie im Kommentarbereich und wir werden uns bei Ihnen melden.
Zusammenhängende Posts: