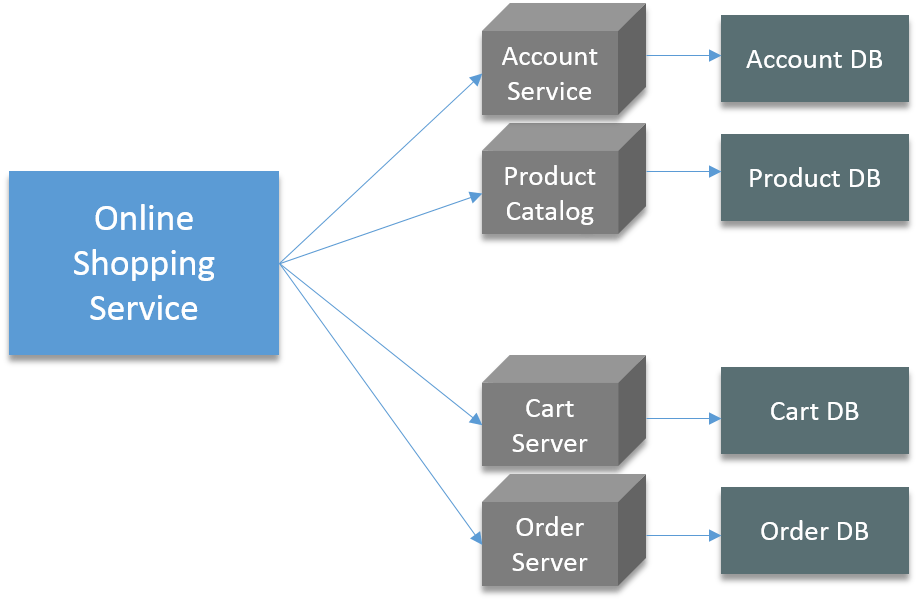
Wie führe ich Hive-Skripte aus?
Dies ist ein Tutorial zum Ausführen von Hive-Skripten. Durch Ausführen dieses Skripts wird der Zeit- und Arbeitsaufwand für das manuelle Schreiben und Ausführen jedes Befehls verringert.

Dies ist ein Tutorial zum Ausführen von Hive-Skripten. Durch Ausführen dieses Skripts wird der Zeit- und Arbeitsaufwand für das manuelle Schreiben und Ausführen jedes Befehls verringert.
Lesen Sie diesen Blog-Beitrag, um Ihr erstes Apache Pig-Skript zu erstellen. Apache Pig-Skripte werden verwendet, um eine Reihe von Apache Pig-Befehlen gemeinsam auszuführen.
Pig-Programmierung: Apache Pig-Skript mit UDF im HDFS-Modus. Hier ist ein Blog-Beitrag zum Ausführen des Apache Pig-Skripts mit UDF im HDFS-Modus ...
Dieser Beitrag beschreibt Hadoop Map Seite Join Vs. beitreten. Erfahren Sie auch, was Map Reduce, Join Table, Join Side und die Vorteile der Verwendung von Map Side Join-Operationen in Hive sind
Wissen Sie, wie Sie Knoten in einem Hadoop-Cluster hinzufügen oder entfernen? Hier ist ein Blog-Beitrag, den Sie ausführen können - Inbetriebnahme und Außerbetriebnahme von Knoten in einem Hadoop-Cluster.
Dieser Blog beschreibt alle hilfreichen Hadoop Shell-Befehle. Neben den Hadoop Shell-Befehlen enthält es auch Screenshots, um das Lernen zu vereinfachen. Weiter lesen!
Big Data und Hadoop werden voraussichtlich die Zukunft des Datenmanagementsystems sein. Big Data ist für Leute gedacht, die von Mainframe zu Big Data Hadoop wechseln.
Dieser Beitrag beschreibt Operatoren in Apache Pig. Schauen Sie sich diesen Beitrag für Operatoren in Apache Pig an: Teil 1 - Relationale Operatoren.
Dieser Beitrag beschreibt HBase und Einblicke in die HBase-Architektur. Außerdem werden Hbase-Komponenten wie Master, Regionsserver und Zoo Keeper sowie deren Verwendung erläutert.
Dieser Beitrag beschreibt Apache Pig UDF - Auswertungs-, Aggregat- und Filterfunktionen. Schauen Sie sich die Eval-, Aggregate- und Filterfunktionen an.
Dieser Beitrag beschreibt Apache Pig UDF - Ladefunktionen. (Apache Pig UDF: Teil 2). Schauen Sie sich die Ladefunktionen von Apache Pig UDF an.
Dieser Beitrag beschreibt die Apache Pig UDF - Store-Funktionen. (Apache Pig UDF: Teil 3). Schauen Sie sich die Store-Funktionen von Apache Pig UDF an.
In diesem Blog erfahren Sie mehr über die Installation von Apache Hive unter Ubuntu und über Konzepte rund um Hadoop Hive, Hive SQL, Hive-Datenbank, Hive-Server und Hive-Installation.
In diesem Beitrag wird beschrieben, wie Big Data verwendet wird, um die Marketingfähigkeiten in der Telekommunikationsbranche zu verbessern. Lesen Sie weiter, um mehr über die Big Data- und Telekommunikationsbranche zu erfahren.
Finden Sie heraus, warum ein Software-Testingenieur Big Data und Hadoop lernen muss und wie Big Data-Schulungen und Hadoop-Zertifizierungen ihm helfen können, Top-Big Data-Jobs zu erledigen.
In diesem Beitrag wird ein Beispiel für einen Proof of Concept für HBase erläutert. Sie finden eine klare Erklärung des Konzepts, um Ihr Verständnis von HBase zu verbessern.
Oracle zu HDFS mit Sqoop - Lesen Sie die Schritte für Oracle zu HDFS mit Sqoop.
Big Data kann Probleme lösen, mit denen große Unternehmen konfrontiert sind. Im Folgenden werden hochwertige Big Data-Anwendungsfälle aufgeführt, mit denen die Probleme behoben werden, mit denen sie konfrontiert sind
Apache Storm ist wegen seiner Echtzeitverarbeitungsfunktionen beliebt und wurde aus diesem Grund implementiert. Hier sind einige Anwendungsfälle für Apache Storm.
Hadoop-Administratoren werden dringend benötigt, da Unternehmen Hadoop schnell einsetzen und jeder Cluster mit mehr als 20 bis 30 Knoten einen Vollzeitadministrator benötigt.