
Lassen Sie uns im heutigen Beitrag über die HBase-Architektur diskutieren. Lassen Sie uns unsere Grundlagen von HBase auffrischen, bevor wir uns eingehender mit der HBase-Architektur befassen.
HBase - Die Grundlagen:
HBase ist ein Open-Source-NoSQL-verteilter, nicht relationaler, versionierter, mehrdimensionaler, spaltenorientierter Speicher, der nach dem Vorbild von Google BigTable erstellt wurde, das auf HDFS ausgeführt wird. '' NoSQL '' ist ein weit gefasster Begriff, der bedeutet, dass die Datenbank kein RDBMS ist, das SQL als primäre Zugriffssprache unterstützt. Es gibt jedoch viele Arten von NoSQL-Datenbanken, und Berkeley DB ist ein gutes Beispiel für eine lokale NoSQL-Datenbank, während HBase dies ist sehr viel eine verteilte Datenbank.
HBase bietet alle Funktionen von Google BigTable. Es begann als Projekt von Powerset, riesige Datenmengen für die Suche in natürlicher Sprache zu verarbeiten. Es wurde im Rahmen des Hadoop-Projekts von Apache entwickelt und läuft auf HDFS (Hadoop Distributed File System). Es bietet fehlertolerante Möglichkeiten zum Speichern großer Mengen spärlicher Daten. HBase ist eher ein „Datenspeicher“ als eine „Datenbank“, da viele der in RDBMS verfügbaren Funktionen fehlen, z. B. typisierte Spalten, Sekundärindizes, Trigger und erweiterte Abfragesprachen usw.
In den spaltenorientierten Datenbanken wird die Datentabelle als Abschnitt von Datenspalten und nicht als Datenzeilen gespeichert. Das Datenmodell einer spaltenorientierten Datenbank besteht aus Tabellenname, Zeilenschlüssel, Spaltenfamilie, Spalten und Zeitstempel. Beim Erstellen von Tabellen in HBase werden die Zeilen mithilfe von Zeilenschlüsseln und Zeitstempel eindeutig identifiziert. In diesem Datenmodell sind die Spaltenfamilien statisch, während Spalten dynamisch sind. Lassen Sie uns nun einen Blick auf die HBase-Architektur werfen.
Wann sollte man sich für HBase entscheiden?
HBase ist nur dann eine gute Option, wenn Hunderte von Millionen oder Milliarden Zeilen vorhanden sind. HBase kann auch an Orten verwendet werden, an denen ein Wechsel von einem RDBMS zu HBase als komplettes Redesign im Gegensatz zu einem Port in Betracht gezogen wird. Mit anderen Worten, HBase ist nicht für klassische Transaktionsanwendungen oder sogar relationale Analysen optimiert. Es ist auch kein vollständiger Ersatz für HDFS, wenn MapReduce in großen Mengen ausgeführt wird. Warum sollten Sie sich dann für HBase entscheiden? Wenn Ihre Anwendung ein variables Schema hat, bei dem jede Zeile etwas anders ist, sollten Sie sich HBase ansehen.
Java Classpath Windows einstellen 7
HBase-Architektur:
Die folgende Abbildung erläutert die HBase-Architektur deutlich.
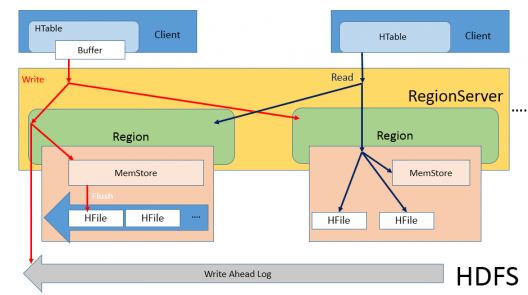
In HBase gibt es drei Hauptkomponenten: Master, Region Server und Zoo Keeper . Die anderen Komponenten sind Memstore, HFile und WAL.
Da HBase auf HDFS ausgeführt wird, wird die Master-Slave-Architektur verwendet, bei der der HMaster der Masterknoten und die Region Server die Slaveknoten sind. Wenn der Client eine Schreibanforderung sendet, erhält HMaster diese Anforderung und leitet sie an den jeweiligen Regionsserver weiter.
Regionsserver:
Es ist ein System, das sich ähnlich wie ein Datenknoten verhält. Wenn der Regionsserver (RS) eine Schreibanforderung empfängt, leitet er die Anforderung an eine bestimmte Region weiter. Jede Region speichert eine Reihe von Zeilen. Zeilendaten können in mehrere Spaltenfamilien (CFs) getrennt werden. Daten bestimmter CF werden in HStore gespeichert, das aus Memstore und einer Reihe von HFiles besteht.
Was macht Memstore?
Memstore verfolgt alle Protokolle für die Lese- und Schreibvorgänge, die auf diesem bestimmten Regionsserver ausgeführt wurden. Daraus können wir schließen, dass es sich ähnlich wie ein Namensknoten in Hadoop verhält. Memstore ist ein speicherinterner Speicher, daher verwendet der Memstore den speicherinternen Speicher jedes Datenknotens zum Speichern der Protokolle. Wenn bestimmte Schwellenwerte erreicht sind, werden Memstore-Daten in HFile gespült.
Der Hauptzweck für die Verwendung von Memstore ist die Notwendigkeit, Daten in DFS zu speichern, die nach Zeilenschlüssel geordnet sind. Da HDFS für sequentielles Lesen / Schreiben ausgelegt ist und keine Dateimodifikationen zulässig sind, kann HBase Daten beim Empfang nicht effizient auf die Festplatte schreiben: Die geschriebenen Daten werden nicht sortiert (wenn die Eingabe nicht sortiert ist), was bedeutet, dass sie nicht für die Zukunft optimiert sind Abruf. Um dieses Problem zu lösen, puffert HBase die zuletzt empfangenen Daten im Speicher (im Memstore), sortiert sie vor dem Leeren und schreibt dann mit schnellen sequentiellen Schreibvorgängen in HDFS. Daher enthält HFile eine Liste sortierter Zeilen.
Jedes Mal, wenn eine Memstore-Spülung stattfindet, wird eine HFile für jede CF erstellt, und häufige Spülungen können Tonnen von HFiles erzeugen. Da HBase beim Lesen viele HFiles betrachten muss, kann die Lesegeschwindigkeit leiden. Um zu verhindern, dass zu viele HFiles geöffnet werden und die Leseleistung nicht beeinträchtigt wird, wird der HFiles-Verdichtungsprozess verwendet. HBase komprimiert regelmäßig (wenn bestimmte konfigurierbare Schwellenwerte erreicht werden) mehrere kleinere HFiles zu einer großen. Je mehr Dateien von Memstore gelöscht werden, desto mehr Arbeit (zusätzliche Last) für das System ist natürlich erforderlich. Während der Komprimierungsprozess normalerweise parallel zur Bearbeitung anderer Anforderungen ausgeführt wird und HBase mit der Komprimierung von HFiles nicht Schritt halten kann (ja, auch dafür gibt es konfigurierte Schwellenwerte), werden Schreibvorgänge auf RS erneut blockiert. Wie wir oben besprochen haben, ist dies höchst unerwünscht.
Was ist Instanzvariable in Java
Wir können nicht sicher sein, dass die Daten im gesamten Memstore dauerhaft vorhanden sind. Angenommen, ein bestimmter Datenknoten ist ausgefallen. Dann gehen die Daten verloren, die sich im Speicher dieses Datenknotens befinden.
Um dieses Problem zu lösen, wird die Anforderung, wenn sie vom Master kommt, auch an WAL geschrieben. WAL ist nichts anderes als Vorab-Protokolle schreiben welches sich auf dem HDFS befindet, einem permanenten Speicher. Jetzt können wir sicherstellen, dass die Daten auch dann nicht verloren gehen, wenn der Datenknoten ausgefallen ist. Wir haben die Kopie aller Aktionen, die Sie in der WAL ausführen sollen. Wenn der Datenknoten aktiv ist, werden alle Aktivitäten erneut ausgeführt. Sobald der Vorgang abgeschlossen ist, wird alles aus Memstore und WAL gelöscht und in HFile geschrieben, um sicherzustellen, dass uns nicht der Speicher ausgeht.
Nehmen wir ein einfaches Beispiel, dass ich Zeile 10 hinzufügen möchte, wenn diese Schreibanforderung eingeht. Sie besagt, dass alle Metadaten an Memstore und WAL übergeben werden. Sobald diese bestimmte Zeile in HFile geschrieben ist, wird alles in Memstore und WAL gelöscht.
Zoo Keeper:
HBase ist in den Zoo Keeper integriert. Wenn ich HBase starte, wird auch die Zoo Keeper-Instanz gestartet. Der Grund dafür ist, dass der Zoo Keeper uns dabei hilft, alle Regionsserver zu verfolgen, die für HBase verfügbar sind. Zoo Keeper verfolgt, wie viele Regionsserver vorhanden sind, welche Regionsserver von welchem Datenknoten zu welchem Datenknoten halten. Es verfolgt kleinere Datensätze, in denen Hadoop fehlt. Dies verringert den Overhead über Hadoop, wodurch die meisten Ihrer Metadaten erfasst werden. Daher erhält HMaster die Details der Regionsserver, indem er sich tatsächlich an den Zoo-Keeper wendet.
Hast du eine Frage an uns? Erwähnen Sie sie im Kommentarbereich und wir werden uns bei Ihnen melden.
PHP erstellen Array aus String
Zusammenhängende Posts: