
Wie wir in unserem erwähnt haben Blog, HBase ist ein wesentlicher Bestandteil unseres Hadoop-Ökosystems. Nun möchte ich Sie durch das HBase-Tutorial führen, in dem ich Ihnen Apache HBase vorstellen werde, und dann werden wir die Facebook Messenger-Fallstudie durchgehen. In diesem HBase-Tutorial-Blog werden wir folgende Themen behandeln:
- Geschichte der Apache HBase
- Einführung von Apache HBase
- NoSQL-Datenbanken und ihre Typen
- HBase gegen Cassandra
- Apache HBase-Funktionen
- HBase gegen HDFS
- Facebook Messenger Fallstudie
Apache HBase Tutorial: Geschichte
Beginnen wir mit der Geschichte von HBase und wissen, wie sich HBase im Laufe der Zeit entwickelt hat.
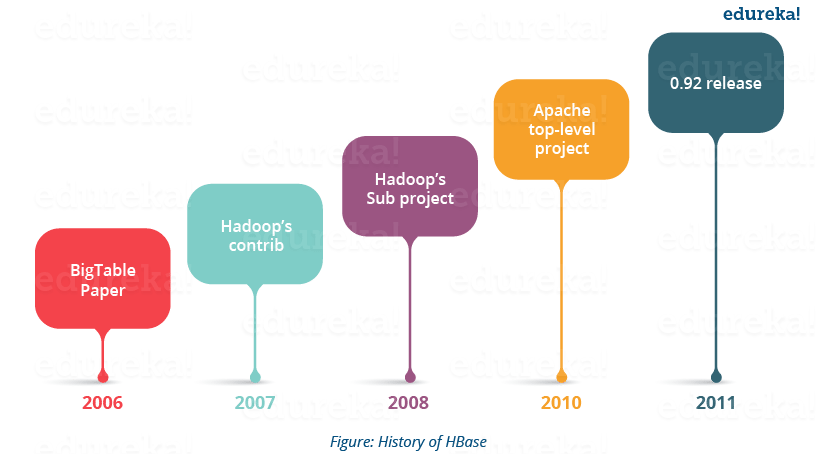
- Apache HBase ist dem BigTable von Google nachempfunden, mit dem Daten gesammelt und Anfragen für verschiedene Google-Dienste wie Karten, Finanzen, Erde usw. bearbeitet werden.
- Apache HBase begann als Projekt der Firma Powerset for Natural Language Search, die massive und spärliche Datensätze verarbeitete.
- Apache HBase wurde erstmals im Februar 2007 veröffentlicht. Später im Januar 2008 wurde HBase ein Teilprojekt von Apache Hadoop.
- Im Jahr 2010 wurde HBase zum Top-Level-Projekt von Apache.
HBase Tutorial | NoSQL-Datenbanken | Edureka
Nachdem Sie die Geschichte von Apache HBase kennengelernt haben, sind Sie gespannt, was Apache HBase ist. Gehen wir weiter und schauen wir uns das an.
Apache HBase Tutorial: Einführung in HBase
HBase ist ein Open Source, mehrdimensional, verteilt, skalierbar und a NoSQL-Datenbank geschrieben in Java. HBase läuft auf HDFS (Hadoop Distributed File System) und bietet BigTable-ähnliche Funktionen für Hadoop. Es bietet eine fehlertolerante Möglichkeit zum Speichern einer großen Sammlung von Datensätzen mit geringer Dichte.
Seitdem erzielt HBase einen hohen Durchsatz und eine geringe Latenz, indem es einen schnelleren Lese- / Schreibzugriff auf große Datenmengen bietet. Daher ist HBase die Wahl für Anwendungen, die einen schnellen und zufälligen Zugriff auf große Datenmengen erfordern.
Es bietet Komprimierung, speicherinterne Operationen und Bloom-Filter (Datenstruktur, die angibt, ob ein Wert in einem Satz vorhanden ist oder nicht), um die Anforderung schneller und zufälliger Lese- und Schreibvorgänge zu erfüllen.
Lassen Sie es uns anhand eines Beispiels verstehen: Ein Strahltriebwerk erzeugt verschiedene Arten von Daten von verschiedenen Sensoren wie Drucksensor, Temperatursensor, Geschwindigkeitssensor usw., die den Zustand des Triebwerks anzeigen. Dies ist sehr nützlich, um die Probleme und den Status des Fluges zu verstehen. Der kontinuierliche Triebwerksbetrieb generiert 500 GB Daten pro Flug und es gibt ungefähr 300.000 Flüge pro Tag. Mit Engine Analytics, das nahezu in Echtzeit auf solche Daten angewendet wird, können Probleme proaktiv diagnostiziert und ungeplante Ausfallzeiten reduziert werden. Dies erfordert eine verteilte Umgebung, in der große Datenmengen gespeichert werden können schnelles zufälliges Lesen und Schreiben für die Echtzeitverarbeitung. Hier kommt HBase zur Rettung. Ich werde in meinem nächsten Blog auf ausführlich über HBase Read and Write sprechen HBase-Architektur .
Wie wir wissen, ist HBase eine NoSQL-Datenbank. Bevor Sie mehr über HBase erfahren, sollten Sie zunächst die NoSQL-Datenbanken und ihre Typen erläutern.
Unterschied zwischen Java und Klasse
Apache HBase Tutorial: NoSQL-Datenbanken
NoSQL bedeutet Nicht nur SQL . NoSQL-Datenbanken sind so modelliert, dass sie andere Daten als Tabellenformate darstellen können, unkile relationale Datenbanken. Es werden unterschiedliche Formate zur Darstellung von Daten in Datenbanken verwendet. Daher gibt es je nach Darstellungsformat unterschiedliche Arten von NoSQL-Datenbanken. Die meisten NoSQL-Datenbanken nutzen Verfügbarkeit und Geschwindigkeit gegenüber Konsistenz. Lassen Sie uns nun die verschiedenen Arten von NoSQL-Datenbanken und ihre Darstellungsformate verstehen.
Schlüsselwertspeicher:
Es ist eine schemalose Datenbank, die Schlüssel und Werte enthält. Jeder Schlüssel, der auf einen Wert zeigt, der ein Array von Bytes ist, kann eine Zeichenfolge, ein BLOB, XML usw. sein, z. Lamborghini ist ein Schlüssel und kann auf einen Wert hinweisen, den Gallardo, Aventador, Murciélago, Reventón, Diablo, Huracán, Veneno, Centenario usw. haben.
Key-Value speichert Datenbanken: Aerospike, Couchbase, Dynamo, FairCom c-treeACE, FoundationDB, HyperDex, MemcacheDB, MUMPS, Oracle NoSQL-Datenbank, OrientDB, Redis, Riak, Berkeley DB.
Anwendungsfall
Schlüsselwertspeicher verarbeiten die Größe gut und können einen konstanten Strom von Lese- / Schreibvorgängen mit geringer Latenz verarbeiten. Das macht sie perfekt fürBenutzerpräferenz- und Profilspeicher,Produktempfehlungen Neueste Artikel, die auf einer Händler-Website angezeigt werden, um zukünftige Produktempfehlungen für Kunden voranzutreiben.Die Einkaufsgewohnheiten der Kundenbetreuung führen zu benutzerdefinierten Anzeigen, Gutscheinen usw. für jeden Kunden in Echtzeit.
Dokumentorientiert ::
Es folgt demselben Schlüsselwertpaar, ist jedoch halbstrukturiert wie XML, JSON, BSON. Diese Strukturen gelten als Dokumente.
Dokumentbasierte Datenbanken: Apache CouchDB, Clusterpoint, Couchbase, DocumentDB, HyperDex, IBM Domino, MarkLogic, MongoDB, OrientDB, Qizx, RethinkDB.
Anwendungsfall
Da das Dokument ein flexibles Schema unterstützt, eignet es sich durch schnelles Lesen, Schreiben und Partitionieren zum Erstellen von Benutzerdatenbanken in verschiedenen Diensten wie Twitter, E-Commerce-Websites usw.
Spaltenorientiert:
In dieser Datenbank werden Daten in Zellen gespeichert, die in Spalten und nicht in Zeilen gruppiert sind. Spalten werden logisch in Spaltenfamilien gruppiert, die entweder während der Schemadefinition oder zur Laufzeit erstellt werden können.
Diese Datenbanktypen speichern alle Zellen, die einer Spalte entsprechen, als fortlaufenden Festplatteneintrag, wodurch der Zugriff und die Suche erheblich beschleunigt werden.
Spaltenbasierte Datenbanken: HBase, Accumulo, Cassandra, Druid, Vertica.
Anwendungsfall
Es unterstützt den riesigen Speicher und ermöglicht einen schnelleren Lese- und Schreibzugriff. Dadurch eignen sich spaltenorientierte Datenbanken zum Speichern von Kundenverhalten auf E-Commerce-Websites, Finanzsystemen wie Google Finance und Börsendaten, Google Maps usw.
Grafikorientiert:
Es ist eine perfekte flexible grafische Darstellung, die im Gegensatz zu SQL verwendet wird. Diese Arten von Datenbanken lösen problemlos Probleme mit der Skalierbarkeit von Adressen, da sie Kanten und Knoten enthalten, die je nach den Anforderungen erweitert werden können.
Graphbasierte Datenbanken: AllegroGraph, ArangoDB, InfiniteGraph, Apache Giraph, MarkLogic, Neo4J, OrientDB, Virtuoso, Stardog.
Anwendungsfall
Dies wird im Wesentlichen in der Betrugserkennung, in Echtzeit-Empfehlungs-Engines (in den meisten Fällen im E-Commerce), im Stammdatenmanagement (MDM), im Netzwerk- und IT-Betrieb, im Identitäts- und Zugriffsmanagement (IAM) usw. verwendet.
HBase und Cassandra sind die beiden bekannten spaltenorientierten Datenbanken. Lassen Sie uns nun die architektonischen und funktionalen Unterschiede zwischen HBase und Cassandra vergleichen und verstehen.
HBase-Tutorial: HBase VS Cassandra
- HBase basiert auf BigTable (Google), während Cassandra auf DynamoDB (Amazon) basiert, das ursprünglich von Facebook entwickelt wurde.
- HBase nutzt die Hadoop-Infrastruktur (HDFS, ZooKeeper), während Cassandra separat entwickelt wurde. Sie können Hadoop und Cassandra jedoch nach Ihren Wünschen kombinieren.
- HBase besteht aus mehreren Komponenten, die miteinander kommunizieren, z. B. HBase HMaster, ZooKeeper, NameNode und Region Severs. Während Cassandra ein einzelner Knotentyp ist, bei dem alle Knoten gleich sind und alle Funktionen ausführen. Jeder Knoten kann der Koordinator sein, der Single Point of Failure entfernt.
- HBase ist für das Lesen optimiert und unterstützt einzelne Schreibvorgänge, was zu einer strengen Konsistenz führt. HBase unterstützt bereichsbasierte Scans, wodurch der Scanvorgang beschleunigt wird. Während Cassandra das Lesen einzelner Zeilen unterstützt, bleibt die Konsistenz erhalten.
- Cassandra unterstützt keine bereichsbasierten Zeilenscans, was den Scanvorgang im Vergleich zu HBase verlangsamt.
- HBase unterstützt die geordnete Partitionierung, bei der Zeilen einer Spaltenfamilie in RowKey-Reihenfolge gespeichert werden, während die geordnete Partitionierung in Casandra eine Herausforderung darstellt. Aufgrund der RowKey-Partitionierung ist der Scanvorgang in HBase im Vergleich zu Cassandra schneller.
- HBase unterstützt keinen Leselastenausgleich, ein Regionsserver bedient die Leseanforderung und die Replikate werden nur im Fehlerfall verwendet. Während Cassandra den Lese-Lastausgleich unterstützt und dieselben Daten von verschiedenen Knoten lesen kann. Dies kann die Konsistenz beeinträchtigen.
- Im CAP-Satz (Konsistenz, Verfügbarkeit und Partitionstoleranz) behält HBase die Konsistenz und Verfügbarkeit bei, während Cassandra sich auf Verfügbarkeit und Partitionstoleranz konzentriert.
Lassen Sie uns nun einen tiefen Einblick in die Funktionen von Apache HBase geben, die es so beliebt machen.
Apache HBase Tutorial: Funktionen von HBase
- Atomic lesen und schreiben: Auf Zeilenebene bietet HBase atomares Lesen und Schreiben. Es kann erklärt werden, dass während eines Lese- oder Schreibprozesses alle anderen Prozesse daran gehindert werden, Lese- oder Schreibvorgänge auszuführen.
- Konsistentes Lesen und Schreiben: HBase bietet aufgrund der oben genannten Funktion konsistente Lese- und Schreibvorgänge.
- Lineare und modulare Skalierbarkeit: Da Datensätze über HDFS verteilt sind, sind sie sowohl linear über verschiedene Knoten als auch modular skalierbar, da sie über verschiedene Knoten verteilt sind.
- Automatisches und konfigurierbares Sharding von Tabellen: HBase-Tabellen sind über Cluster verteilt und diese Cluster sind über Regionen verteilt. Diese Regionen und Cluster teilen sich und werden neu verteilt, wenn die Daten wachsen.
- Einfach zu verwendende Java-API für den Clientzugriff: Es bietet eine benutzerfreundliche Java-API für den programmgesteuerten Zugriff.
- Thrift Gateway und ein REST-voller Webdienst: Es unterstützt auch die Thrift- und REST-API für Nicht-Java-Frontends.
- Block-Cache- und Bloom-Filter: HBase unterstützt einen Block-Cache und Bloom-Filter für die Optimierung von Abfragen mit hohem Volumen.
- Automatische Fehlerunterstützung: HBase mit HDFS bietet WAL (Write Ahead Log) über Cluster hinweg und bietet automatische Fehlerunterstützung.
- Sortierte Rowkeys: Da die Suche nach Zeilenbereichen durchgeführt wird, speichert HBase die Zeilenschlüssel in einer lexikografischen Reihenfolge. Mit diesen sortierten Zeilenschlüsseln und dem Zeitstempel können wir eine optimierte Anforderung erstellen.
Lassen Sie mich nun in diesem HBase-Tutorial erläutern, in welchen Anwendungsfällen und Szenarien HBase verwendet werden kann. Anschließend werde ich HDFS und HBase vergleichen.
Ich möchte Ihre Aufmerksamkeit auf die Szenarien lenken, in die die HBase am besten passt.
HBase Tutorial: Wo können wir HBase verwenden?
- Wir sollten HBase verwenden, wenn wir große Datenmengen haben (Millionen oder Milliarden oder Zeilen und Spalten) und schnellen, zufälligen und Echtzeit-Lese- und Schreibzugriff auf die Daten benötigen.
- Die Datensätze sind auf verschiedene Cluster verteilt und wir benötigen eine hohe Skalierbarkeit, um Daten verarbeiten zu können.
- Die Daten stammen aus verschiedenen Datenquellen und sind entweder halbstrukturierte oder unstrukturierte Daten oder eine Kombination aus allen. Es könnte leicht mit HBase gehandhabt werden.
- Sie möchten spaltenorientierte Daten speichern.
- Sie haben viele Versionen der Datensätze und müssen alle speichern.
Bevor ich zur Facebook Messenger-Fallstudie springe,Lassen Sie mich Ihnen sagen, was die Unterschiede zwischen HBase und HDFS sind.
HBase-Tutorial: HBase VS HDFS
HDFS ist ein Java-basiertes verteiltes Dateisystem, mit dem Sie große Datenmengen auf mehreren Knoten in einem Hadoop-Cluster speichern können. HDFS ist also ein zugrunde liegendes Speichersystem zum Speichern der Daten in der verteilten Umgebung. HDFS ist ein Dateisystem, während HBase eine Datenbank ist (ähnlich wie NTFS und MySQL).
Da sowohl HDFS als auch HBase jede Art von Daten (d. H. Strukturiert, halbstrukturiert und unstrukturiert) in einer verteilten Umgebung speichern, können Sie die Unterschiede zwischen dem HDFS-Dateisystem und HBase, einer NoSQL-Datenbank, untersuchen.
- HBase bietet Zugriff auf kleine Datenmengen in großen Datenmengen mit geringer Latenz, während HDFS Operationen mit hoher Latenz bietet.
- HBase unterstützt zufälliges Lesen und Schreiben, während HDFS WORM unterstützt (einmal schreiben, mehrmals lesen oder mehrmals).
- Auf HDFS wird grundsätzlich oder hauptsächlich über MapReduce-Jobs zugegriffen, während auf HBase über Shell-Befehle, Java-API, REST, Avro oder Thrift-API zugegriffen wird.
HDFS speichert große Datenmengen in einer verteilten Umgebung und nutzt die Stapelverarbeitung für diese Daten. Z.B. Dies würde einer E-Commerce-Website helfen, Millionen von Kundendaten in einer verteilten Umgebung zu speichern, die über einen langen Zeitraum (möglicherweise 4 bis 5 Jahre oder länger) gewachsen ist. Anschließend wird die Stapelverarbeitung für diese Daten genutzt und das Verhalten, Muster und die Anforderungen der Kunden analysiert. Dann konnte das Unternehmen herausfinden, welche Art von Produkt, Kundeneinkauf in welchen Monaten. Es hilft, archivierte Daten zu speichern und die Stapelverarbeitung darüber auszuführen.
Während HBase Daten spaltenorientiert speichert, wobei jede Spalte zusammen gespeichert wird, wird das Lesen mithilfe der Echtzeitverarbeitung schneller. Z.B. In einer ähnlichen E-Commerce-Umgebung werden Millionen von Produktdaten gespeichert. Wenn Sie also unter Millionen von Produkten nach einem Produkt suchen, wird der Anforderungs- und Suchprozess optimiert und das Ergebnis sofort erstellt (oder Sie können es in Echtzeit sagen). Das detaillierte HBase Architekturerklärung Ich werde in meinem nächsten Blog darüber berichten.
Da wir wissen, dass HBase über HDFS verteilt ist, bietet uns eine Kombination aus beiden die großartige Möglichkeit, die Vorteile beider in einer maßgeschneiderten Lösung zu nutzen, wie wir in der folgenden Facebook Messenger-Fallstudie sehen werden.
HBase-Tutorial: Facebook Messenger-Fallstudie
Facebook Messaging-Plattform wechselte im November 2010 von Apache Cassandra zu HBase.
Facebook Messenger kombiniert Nachrichten, E-Mail, Chat und SMS zu einem Echtzeit-Gespräch. Facebook versuchte, eine skalierbare und robuste Infrastruktur für diese Dienste aufzubauen.
Zu diesem Zeitpunkt wurden in der Nachrichteninfrastruktur über 350 Millionen Benutzer verarbeitet, die monatlich über 15 Milliarden Nachrichten von Person zu Person sendeten. Der Chat-Dienst unterstützt über 300 Millionen Benutzer, die monatlich über 120 Milliarden Nachrichten senden.
Bei der Überwachung der Nutzung stellten sie fest, dass zwei allgemeine Datenmuster auftraten:
ec2 Instanz aus Snapshot erstellen
- Ein kurzer Satz zeitlicher Daten, die tendenziell flüchtig sind
- Ein ständig wachsender Datensatz, auf den nur selten zugegriffen wird
Facebook wollte eine Speicherlösung für diese beiden Nutzungsmuster finden und suchte nach einem Ersatz für die vorhandene Nachrichteninfrastruktur.
Anfang 2008 verwendeten sie eine Open-Source-Datenbank, d. H. Cassandra, einen Schlüsselwertspeicher mit eventueller Konsistenz, der bereits in Produktion war und den Datenverkehr für die Posteingangssuche bediente. Ihre Teams verfügten über große Kenntnisse in der Verwendung und Verwaltung einer MySQL-Datenbank, sodass die Umstellung auf eine der beiden Technologien ein ernstes Problem für sie darstellte.
Sie haben einige Wochen damit verbracht, verschiedene Frameworks zu testen, um die Cluster von MySQL, Apache Cassandra, Apache HBase und anderen Systemen zu evaluieren. Sie wählten schließlich HBase.
Da MySQL die großen Datenmengen nicht effizient handhaben konnte und die Indizes und Datenmengen größer wurden, litt die Leistung darunter. Sie fanden, dass Cassandra nicht in der Lage war, mit schwierigen Mustern umzugehen, um ihre neue Nachrichteninfrastruktur in Einklang zu bringen.
Die Hauptprobleme waren:
- Speichern der großen Mengen kontinuierlich wachsender Daten von verschiedenen Facebook-Diensten.
- Benötigt eine Datenbank, die eine hohe Verarbeitung nutzen kann.
- Hohe Leistung erforderlich, um Millionen von Anfragen zu bedienen.
- Aufrechterhaltung der Konsistenz bei Speicherung und Leistung.
Abbildung: Herausforderungen für Facebook Messenger
Für all diese Probleme hat Facebook eine Lösung gefunden, d. H. HBase. Facebook hat HBase aufgrund seiner verschiedenen Funktionen für die Bereitstellung von Facebook Messenger, Chat, E-Mail usw. übernommen.
HBase bietet eine sehr gute Skalierbarkeit und Leistung für diese Workload mit einem einfacheren Konsistenzmodell als Cassandra. Während sie fanden, dass HBase hinsichtlich ihrer Anforderungen wie automatischer Lastausgleich und Failover, Komprimierungsunterstützung, mehrere Shards pro Server usw. am besten geeignet ist.
HDFS, das zugrunde liegende Dateisystem, das von HBase verwendet wird, stellte ihnen auch einige erforderliche Funktionen zur Verfügung, wie End-to-End-Prüfsummen, Replikation und automatischer Lastausgleich.
Abbildung: HBase als Lösung für Facebook Messenger
Als sie HBase einführten, konzentrierten sie sich auch darauf, die Ergebnisse an HBase selbst zurückzugeben, und begannen eng mit der Apache-Community zusammenzuarbeiten.
Da Nachrichten Daten aus verschiedenen Quellen wie SMS, Chats und E-Mails akzeptieren, haben sie einen Anwendungsserver geschrieben, um alle Entscheidungen für die Nachricht eines Benutzers zu treffen. Es ist mit einer Vielzahl anderer Dienste verbunden. Die Anhänge werden in einem Heuhaufen gespeichert (der auf HBase funktioniert). Sie haben auch einen Benutzererkennungsdienst über Apache ZooKeeper geschrieben, der mit anderen Infrastrukturdiensten über Freundschaftsbeziehungen, Überprüfung des E-Mail-Kontos, Zustellungsentscheidungen und Datenschutzentscheidungen spricht.
Das Facebook-Team hat viel Zeit damit verbracht, zu bestätigen, dass jeder dieser Dienste robust, zuverlässig und leistungsfähig ist, um ein Echtzeit-Messagingsystem zu handhaben.
Ich hoffe, dieser HBase-Tutorial-Blog ist informativ und hat Ihnen gefallen. In diesem Blog haben Sie die Grundlagen von HBase und seine Funktionen kennengelernt.In meinem nächsten Blog von Ich werde das erklären Architektur von HBase und die Arbeit von HBase, die es für schnelles und zufälliges Lesen / Schreiben beliebt macht.
Nachdem Sie die Grundlagen von HBase verstanden haben, lesen Sie die von Edureka, einem vertrauenswürdigen Online-Lernunternehmen mit einem Netzwerk von mehr als 250.000 zufriedenen Lernenden auf der ganzen Welt. Der Edureka Big Data Hadoop-Zertifizierungskurs hilft Lernenden, Experten für HDFS, Garn, MapReduce, Schwein, Bienenstock, HBase, Oozie, Flume und Sqoop zu werden. Dabei werden Anwendungsfälle in Echtzeit in den Bereichen Einzelhandel, soziale Medien, Luftfahrt, Tourismus und Finanzen verwendet.
Hast du eine Frage an uns? Bitte erwähnen Sie es in den Kommentaren und wir werden uns bei Ihnen melden.