
HBase-Architektur
In meinem vorherigen Blog auf HBase Tutorial Ich erklärte, was HBase und seine Funktionen sind. Ich habe auch die Fallstudie von Facebook Messenger erwähnt, um Ihnen zu helfen, eine bessere Verbindung herzustellen. Jetzt weiter vorankommen in unserem Ich erkläre Ihnen das Datenmodell von HBase und HBase Architecture.Bevor Sie fortfahren, sollten Sie auch wissen, dass HBase ein wichtiges Konzept ist, das einen integralen Bestandteil des für die Big Data Hadoop-Zertifizierung.
Die wichtigen Themen, durch die ich Sie in diesem HBase-Architektur-Blog führen werde, sind:
- HBase-Datenmodell
- HBase-Architektur und ihre Komponenten
- HBase-Schreibmechanismus
- HBase-Lesemechanismus
- HBase-Leistungsoptimierungsmechanismen
Lassen Sie uns zunächst das Datenmodell von HBase verstehen. Es hilft HBase beim schnelleren Lesen / Schreiben und Suchen.
HBase-Architektur: HBase-Datenmodell
Wie wir wissen, ist HBase eine spaltenorientierte NoSQL-Datenbank. Es ähnelt zwar einer relationalen Datenbank, die Zeilen und Spalten enthält, ist aber keine relationale Datenbank. Relationale Datenbanken sind zeilenorientiert, während HBase spaltenorientiert ist. Lassen Sie uns zunächst den Unterschied zwischen spaltenorientierten und zeilenorientierten Datenbanken verstehen:
Zeilenorientierte oder spaltenorientierte Datenbanken:
- Zeilenorientierte Datenbanken speichern Tabellendatensätze in einer Folge von Zeilen. Während spaltenorientierte DatenbankenSpeichern von Tabellendatensätzen in einer Folge von Spalten, d. h. die Einträge in einer Spalte werden an zusammenhängenden Stellen auf Datenträgern gespeichert.
Um es besser zu verstehen, nehmen wir ein Beispiel und betrachten die folgende Tabelle.
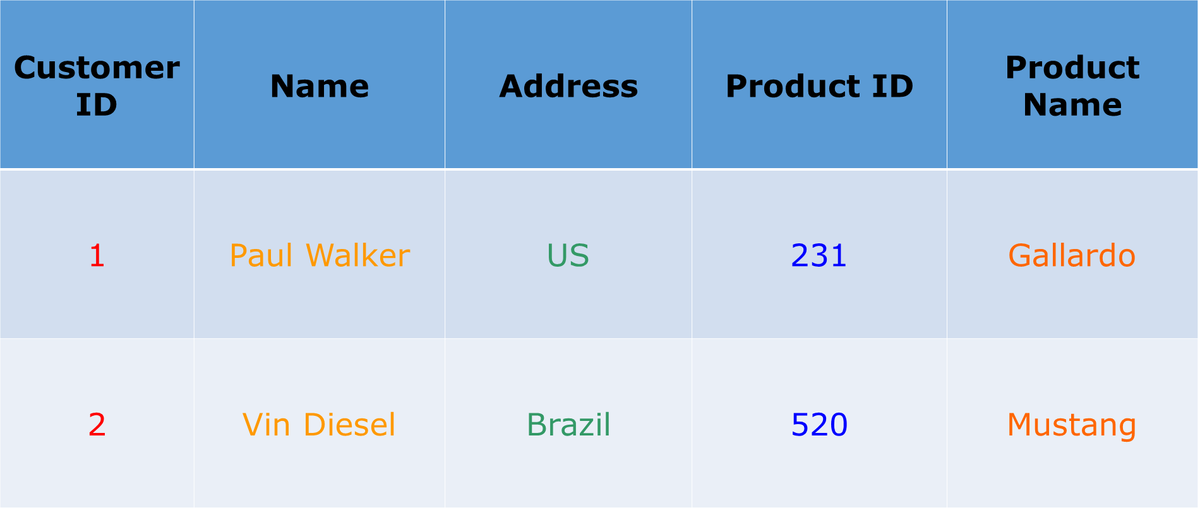
Wenn diese Tabelle in einer zeilenorientierten Datenbank gespeichert ist. Die Datensätze werden wie folgt gespeichert:
ein,Paul Walker,UNS,231,Galant,
2, Vin Diesel,Brasilien,520,Mustang
In zeilenorientierten Datenbanken werden Daten auf der Basis von Zeilen oder Tupeln gespeichert, wie Sie oben sehen können.
Während die spaltenorientierten Datenbanken diese Daten speichern als:
ein,2, Paul Walker,Vin Diesel, UNS,Brasilien, 231,520, Galant,Mustang
In einer spaltenorientierten Datenbank werden alle Spaltenwerte zusammen gespeichert, so wie die ersten Spaltenwerte zusammen gespeichert werden, dann werden die zweiten Spaltenwerte zusammen gespeichert und Daten in anderen Spalten werden auf ähnliche Weise gespeichert.
- Wenn die Datenmenge sehr groß ist, beispielsweise in Bezug auf Petabyte oder Exabyte, verwenden wir einen spaltenorientierten Ansatz, da die Daten einer einzelnen Spalte zusammen gespeichert werden und schneller zugegriffen werden kann.
- Während der zeilenorientierte Ansatz vergleichsweise weniger Zeilen und Spalten effizient verarbeitet, ist die zeilenorientierte Datenbank, in der Daten gespeichert werden, ein strukturiertes Format.
- Wenn wir einen großen Satz halbstrukturierter oder unstrukturierter Daten verarbeiten und analysieren müssen, verwenden wir einen spaltenorientierten Ansatz. Wie Anwendungen, die sich mit Online-Analyseverarbeitung wie Data Mining, Data Warehousing, Anwendungen einschließlich Analysen usw.
- Wohingegen, Online-Transaktionsverarbeitung B. Bank- und Finanzdomänen, die strukturierte Daten verarbeiten und Transaktionseigenschaften (ACID-Eigenschaften) erfordern, verwenden einen zeilenorientierten Ansatz.
HBase-Tabellen bestehen aus folgenden Komponenten (siehe Abbildung unten):
- Tabellen : Daten werden in HBase in einem Tabellenformat gespeichert. Hier sind Tabellen jedoch spaltenorientiert.
- Reihe Schlüssel : Zeilenschlüssel werden verwendet, um Datensätze zu durchsuchen, die die Suche beschleunigen. Sie wären neugierig wie? Ich werde es im Architekturteil erklären, der in diesem Blog weitergeht.
- Säule Familien : Verschiedene Spalten werden in einer Spaltenfamilie zusammengefasst. Diese Spaltenfamilien werden zusammen gespeichert, was den Suchvorgang beschleunigt, da auf Daten derselben Spaltenfamilie in einer einzigen Suche zusammen zugegriffen werden kann.
- Säule Qualifikanten : Der Name jeder Spalte wird als Spaltenqualifizierer bezeichnet.
- Zelle : Daten werden in Zellen gespeichert. Die Daten werden in Zellen gespeichert, die speziell durch Zeilenschlüssel- und Spaltenqualifizierer identifiziert werden.
- Zeitstempel : Der Zeitstempel ist eine Kombination aus Datum und Uhrzeit. Wann immer Daten gespeichert werden, werden sie mit ihrem Zeitstempel gespeichert. Dies erleichtert die Suche nach einer bestimmten Version von Daten.
Einfacher und verständlicher können wir sagen, dass HBase besteht aus:
- Satz von Tabellen
- Jede Tabelle mit Spaltenfamilien und Zeilen
- Der Zeilenschlüssel fungiert in HBase als Primärschlüssel.
- Jeder Zugriff auf HBase-Tabellen verwendet diesen Primärschlüssel
- Jedes in HBase vorhandene Spaltenqualifikationsmerkmal bezeichnet ein Attribut, das dem Objekt entspricht, das sich in der Zelle befindet.
Nachdem Sie nun das HBase-Datenmodell kennen, lassen Sie uns sehen, wie dieses Datenmodell mit der HBase-Architektur übereinstimmt und es für großen Speicher und schnellere Verarbeitung geeignet macht.
HBase-Architektur: Komponenten der HBase-Architektur
HBase hat drei Hauptkomponenten, d.h. HMaster Server , HBase Region Server, Regionen und Tierpfleger .
Die folgende Abbildung erläutert die Hierarchie der HBase-Architektur. Wir werden über jeden von ihnen einzeln sprechen.
wie man Strom in Java benutzt
Bevor wir zum HMaster gehen, werden wir Regionen verstehen, da alle diese Server (HMaster, Region Server, Zookeeper) platziert sind, um Regionen zu koordinieren und zu verwalten und verschiedene Operationen innerhalb der Regionen auszuführen. Sie wären also gespannt, was Regionen sind und warum sie so wichtig sind?
HBase-Architektur: Region
Eine Region enthält alle Zeilen zwischen dem Startschlüssel und dem dieser Region zugewiesenen Endschlüssel. HBase-Tabellen können so in mehrere Regionen unterteilt werden, dass alle Spalten einer Spaltenfamilie in einer Region gespeichert sind. Jede Region enthält die Zeilen in einer sortierten Reihenfolge.
Viele Regionen sind a zugeordnet Regionsserver , das für die Verarbeitung, Verwaltung und Ausführung von Lese- und Schreibvorgängen für diese Gruppe von Regionen verantwortlich ist.
Abschließend auf einfachere Weise:
- Eine Tabelle kann in mehrere Regionen unterteilt werden. Eine Region ist ein sortierter Bereich von Zeilen, in denen Daten zwischen einem Startschlüssel und einem Endschlüssel gespeichert werden.
- Eine Region hat eine Standardgröße von 256 MB, die je nach Bedarf konfiguriert werden kann.
- Eine Gruppe von Regionen wird den Clients von einem Regionsserver bereitgestellt.
- Ein Regionsserver kann dem Client ungefähr 1000 Regionen bereitstellen.
Ausgehend von der Spitze der Hierarchie möchte ich Ihnen zunächst den HMaster Server erläutern, der in ähnlicher Weise als NameNode fungiert HDFS . Wenn ich mich dann in der Hierarchie nach unten bewege, werde ich Sie durch ZooKeeper und Region Server führen.
HBase-Architektur: HMaster
Wie in der folgenden Abbildung sehen Sie, dass der HMaster eine Sammlung von Region Server verwaltet, die sich auf DataNode befindet. Lassen Sie uns verstehen, wie HMaster das macht.
- HBase HMaster führt DDL-Vorgänge aus (Erstellen und Löschen von Tabellen) und weist den Regionsservern Regionen zu, wie Sie im obigen Bild sehen können.
- Es koordiniert und verwaltet den Region Server (ähnlich wie NameNode DataNode in HDFS verwaltet).
- Es weist den Regionsservern beim Start Regionen zu und weist den Regionsservern während der Wiederherstellung und des Lastausgleichs Regionen neu zu.
- Es überwacht alle Instanzen des Region Servers im Cluster (mithilfe von Zookeeper) und führt Wiederherstellungsaktivitäten durch, wenn ein Region Server ausfällt.
- Es bietet eine Schnittstelle zum Erstellen, Löschen und Aktualisieren von Tabellen.
HBase verfügt über eine verteilte und riesige Umgebung, in der HMaster allein nicht ausreicht, um alles zu verwalten. Sie fragen sich also, was HMaster bei der Verwaltung dieser riesigen Umgebung hilft? Hier kommt ZooKeeper ins Spiel. Nachdem wir verstanden haben, wie HMaster die HBase-Umgebung verwaltet, werden wir verstehen, wie Zookeeper HMaster bei der Verwaltung der Umgebung unterstützt.
HBase-Architektur: ZooKeeper - Der Koordinator
Das folgende Bild erklärt den Koordinierungsmechanismus des ZooKeeper.
- Zookeeper fungiert als Koordinator in einer verteilten HBase-Umgebung. Es hilft bei der Aufrechterhaltung des Serverstatus innerhalb des Clusters, indem es über Sitzungen kommuniziert.
- Jeder Region Server sendet zusammen mit HMaster Server in regelmäßigen Abständen einen kontinuierlichen Heartbeat an Zookeeper und überprüft, welcher Server aktiv und verfügbar ist, wie im obigen Bild erwähnt. Außerdem werden Serverausfallbenachrichtigungen bereitgestellt, damit Wiederherstellungsmaßnahmen ausgeführt werden können.
- Aus dem obigen Bild geht hervor, dass es einen inaktiven Server gibt, der als Backup für den aktiven Server dient. Wenn der aktive Server ausfällt, dient er zur Rettung.
- Der aktive HMaster sendet Herzschläge an den Zookeeper, während der inaktive HMaster auf die vom aktiven HMaster gesendete Benachrichtigung wartet. Wenn der aktive HMaster keinen Heartbeat sendet, wird die Sitzung gelöscht und der inaktive HMaster wird aktiv.
- Wenn ein Region Server keinen Heartbeat sendet, ist die Sitzung abgelaufen und alle Listener werden darüber benachrichtigt. Dann führt HMaster geeignete Wiederherstellungsaktionen durch, die wir später in diesem Blog diskutieren werden.
- Zookeeper verwaltet auch den Pfad des .META-Servers, der jedem Client bei der Suche nach einer Region hilft. Der Client muss zuerst mit .META Server prüfen, zu welchem Region Server eine Region gehört, und erhält den Pfad dieses Region Servers.
Wenn ich über .META Server gesprochen habe, möchte ich Ihnen zunächst erklären, was .META Server ist. So können Sie die Arbeit von ZooKeeper und .META Server problemlos miteinander verknüpfen. Wenn ich Ihnen später in diesem Blog den HBase-Suchmechanismus erläutere, erkläre ich, wie diese beiden zusammenarbeiten.
HBase-Architektur: Metatabelle
- Die META-Tabelle ist eine spezielle HBase-Katalogtabelle. Es wird eine Liste aller Regions-Server geführt im HBase-Speichersystem, wie Sie im obigen Bild sehen können.
- Wenn Sie sich die Figur ansehen, die Sie sehen können, .META Datei verwaltet die Tabelle in Form von Schlüsseln und Werten. Schlüssel stellt den Startschlüssel der Region und ihre ID dar, während der Wert den Pfad des Regionsservers enthält.
Wie ich bereits besprochen habe, Regionsserver und seine Funktionen, während ich Ihnen Regionen erklärte, bewegen wir uns jetzt in der Hierarchie nach unten und ich werde mich auf die Komponente des Regionsservers und ihre Funktionen konzentrieren. Später werde ich den Mechanismus des Suchens, Lesens, Schreibens und Verstehens der Zusammenarbeit all dieser Komponenten diskutieren.
HBase-Architektur: Komponenten von Region Server
Das folgende Bild zeigt die Komponenten eines Region Servers. Jetzt werde ich sie separat diskutieren.
Ein Regionsserver verwaltet verschiedene Regionen, die oben auf ausgeführt werden . Komponenten eines Regionsservers sind:
- WAL: Wie Sie dem obigen Bild entnehmen können, ist Write Ahead Log (WAL) eine Datei, die an jeden Region Server in der verteilten Umgebung angehängt ist. Die WAL speichert die neuen Daten, die nicht gespeichert oder in den permanenten Speicher übernommen wurden. Es wird verwendet, wenn die Datensätze nicht wiederhergestellt werden können.
- Cache blockieren: Aus dem obigen Bild ist deutlich ersichtlich, dass sich der Block-Cache oben auf dem Region Server befindet. Es speichert die häufig gelesenen Daten im Speicher. Wenn die Daten in BlockCache zuletzt verwendet wurden, werden diese Daten aus BlockCache entfernt.
- MemStore: Es ist der Schreibcache. Es speichert alle eingehenden Daten, bevor sie auf die Festplatte oder den permanenten Speicher übertragen werden. Für jede Spaltenfamilie in einer Region gibt es einen MemStore. Wie Sie im Bild sehen können, gibt es mehrere MemStores für eine Region, da jede Region mehrere Spaltenfamilien enthält. Die Daten werden in lexikografischer Reihenfolge sortiert, bevor sie auf die Festplatte übertragen werden.
- HFile: Aus der obigen Abbildung können Sie ersehen, dass HFile auf HDFS gespeichert ist. Somit werden die tatsächlichen Zellen auf der Festplatte gespeichert. MemStore schreibt die Daten an HFile, wenn die Größe von MemStore überschritten wird.
Nachdem wir nun die Haupt- und Nebenkomponenten der HBase-Architektur kennen, werde ich den Mechanismus und ihre Zusammenarbeit in diesem Zusammenhang erläutern. Ob es sich um Lesen oder Schreiben handelt, zuerst müssen wir suchen, wo wir lesen oder wo wir eine Datei schreiben sollen. Lassen Sie uns diesen Suchprozess verstehen, da dies einer der Mechanismen ist, die HBase sehr beliebt machen.
HBase-Architektur: Wie wird die Suche in HBase initialisiert?
Wie Sie wissen, speichert Zookeeper den Speicherort der META-Tabelle. Immer wenn sich ein Client mit Lese- oder Schreibanforderungen an HBase nähert, tritt folgende Operation auf:
- Der Client ruft den Speicherort der META-Tabelle vom ZooKeeper ab.
- Der Client fordert dann den Speicherort des Region-Servers des entsprechenden Zeilenschlüssels aus der META-Tabelle an, um darauf zuzugreifen. Der Client speichert diese Informationen mit dem Speicherort der META-Tabelle zwischen.
- Anschließend wird der Zeilenstandort durch Anfordern vom entsprechenden Regionsserver abgerufen.
Für zukünftige Verweise verwendet der Client seinen Cache, um den Speicherort der META-Tabelle abzurufen und zuvor den Region Server des Zeilenschlüssels zu lesen. Dann verweist der Client erst dann auf die META-Tabelle, wenn ein Fehler vorliegt, weil die Region verschoben oder verschoben wurde. Anschließend wird erneut eine Anfrage an den META-Server gestellt und der Cache aktualisiert.
Wie jedes Mal verschwenden Clients keine Zeit damit, den Standort von Region Server von META Server abzurufen. Dies spart Zeit und beschleunigt den Suchvorgang. Lassen Sie mich Ihnen jetzt sagen, wie das Schreiben in HBase stattfindet. Welche Komponenten sind daran beteiligt und wie sind sie beteiligt?
Beispiel für Sortier-C ++ zusammenführen
HBase-Architektur: HBase Write Mechanismus
Das folgende Bild erklärt den Schreibmechanismus in HBase.
Der Schreibmechanismus durchläuft nacheinander den folgenden Vorgang (siehe obiges Bild):
Schritt 1: Immer wenn der Client eine Schreibanforderung hat, schreibt der Client die Daten in die WAL (Write Ahead Log).
- Die Änderungen werden dann am Ende der WAL-Datei angehängt.
- Diese WAL-Datei wird auf jedem Region Server verwaltet, und Region Server verwendet sie zum Wiederherstellen von Daten, die nicht auf der Festplatte festgeschrieben sind.
Schritt 2: Sobald Daten in die WAL geschrieben wurden, werden sie in den MemStore kopiert.
Schritt 3: Sobald die Daten im MemStore abgelegt sind, erhält der Client die Bestätigung.
Schritt 4: Wenn der MemStore den Schwellenwert erreicht, speichert er die Daten oder schreibt sie in eine HFile.
Lassen Sie uns nun einen tiefen Tauchgang machen und verstehen, wie MemStore zum Schreibprozess beiträgt und welche Funktionen es hat.
HBase Write Mechanismus- MemStore
- Der MemStore aktualisiert die darin gespeicherten Daten immer in einer lexikografischen Reihenfolge (nacheinander im Wörterbuch) als sortierte Schlüsselwerte. Es gibt einen MemStore für jede Spaltenfamilie, und daher werden die Aktualisierungen für jede Spaltenfamilie sortiert gespeichert.
- Wenn der MemStore den Schwellenwert erreicht, werden alle Daten sortiert in eine neue HF-Datei kopiert. Diese HFile wird in HDFS gespeichert. HBase enthält mehrere HFiles für jede Spaltenfamilie.
- Mit der Zeit wächst die Anzahl der HFile, wenn MemStore die Daten speichert.
- MemStore speichert auch die zuletzt geschriebene Sequenznummer, sodass Master Server und MemStore beide wissen, was bisher festgeschrieben wurde und wo sie anfangen sollen. Wenn die Region gestartet wird, wird die letzte Sequenznummer gelesen, und von dieser Nummer aus beginnen neue Änderungen.
Wie ich bereits mehrfach besprochen habe, ist HFile der wichtigste persistente Speicher in einer HBase-Architektur. Schließlich werden alle Daten an HFile übergeben, das die permanente Speicherung von HBase darstellt. Schauen wir uns daher die Eigenschaften von HFile an, die die Suche beim Lesen und Schreiben beschleunigen.
HBase-Architektur: HBase Write Mechanismus- HFile
- Die Schreibvorgänge werden nacheinander auf der Festplatte abgelegt. Daher ist die Bewegung des Lese- / Schreibkopfs der Festplatte sehr gering. Dies macht den Schreib- und Suchmechanismus sehr schnell.
- Die HFile-Indizes werden bei jedem Öffnen einer HFile in den Speicher geladen. Dies hilft beim Auffinden eines Datensatzes in einer einzelnen Suche.
- Der Trailer ist ein Zeiger, der auf den Meta-Block der HFile zeigt. Es wird am Ende der festgeschriebenen Datei geschrieben. Es enthält Informationen zu Zeitstempel- und Bloom-Filtern.
- Bloom Filter hilft bei der Suche nach Schlüsselwertpaaren. Es überspringt die Datei, die nicht den erforderlichen Zeilenschlüssel enthält. Der Zeitstempel hilft auch beim Durchsuchen einer Version der Datei und beim Überspringen der Daten.
Nachdem Sie den Schreibmechanismus und die Rolle verschiedener Komponenten kennen, um das Schreiben und Suchen zu beschleunigen. Ich werde Ihnen erklären, wie der Lesemechanismus in einer HBase-Architektur funktioniert. Dann werden wir zu den Mechanismen übergehen, die die HBase-Leistung wie Verdichtung, Regionsaufteilung und Wiederherstellung erhöhen.
HBase-Architektur: Mechanismus lesen
Wie in unserem Suchmechanismus erläutert, ruft der Client zuerst den Speicherort des Region-Servers von .META Server ab, wenn der Client ihn nicht im Cache-Speicher hat. Dann werden die folgenden Schritte wie folgt ausgeführt:
- Zum Lesen der Daten sucht der Scanner zuerst nach der Zeilenzelle im Blockcache. Hier werden alle kürzlich gelesenen Schlüsselwertpaare gespeichert.
- Wenn der Scanner das erforderliche Ergebnis nicht findet, wird er in den MemStore verschoben, da dies der Schreibcache-Speicher ist. Dort wird nach den zuletzt geschriebenen Dateien gesucht, die noch nicht in HFile gespeichert wurden.
- Zuletzt werden Bloom-Filter und Block-Cache verwendet, um die Daten von HFile zu laden.
Bisher habe ich den Such-, Lese- und Schreibmechanismus von HBase besprochen. Jetzt schauen wir uns den HBase-Mechanismus an, mit dem in HBase schnell gesucht, gelesen und geschrieben werden kann. Zuerst werden wir verstehen Verdichtung , das ist einer dieser Mechanismen.
HBase-Architektur: Verdichtung
HBase kombiniert HFiles, um den Speicherplatz und die Anzahl der für einen Lesevorgang erforderlichen Festplattensuchen zu verringern. Dieser Vorgang wird aufgerufen Verdichtung . Durch die Verdichtung werden einige HFiles aus einer Region ausgewählt und kombiniert. Es gibt zwei Arten der Verdichtung, wie Sie im obigen Bild sehen können.
- Geringe Verdichtung : HBase wählt automatisch kleinere HFiles aus und setzt sie erneut für größere HFiles ein, wie im obigen Bild gezeigt. Dies wird als geringfügige Verdichtung bezeichnet. Es führt eine Zusammenführungssortierung durch, um kleinere HFiles an größere HFiles zu übergeben. Dies hilft bei der Speicherplatzoptimierung.
- Hauptverdichtung: Wie im obigen Bild dargestellt, führt HBase bei der Hauptverdichtung die kleineren HFiles einer Region zu einem neuen HFile zusammen und setzt sie erneut fest. In diesem Prozess werden dieselben Spaltenfamilien in der neuen HFile zusammengefasst. Dabei werden gelöschte und abgelaufene Zellen gelöscht. Es erhöht die Leseleistung.
wie man Atom für Python benutzt
Während dieses Vorgangs können jedoch Eingabe-Ausgabe-Festplatten und Netzwerkverkehr überlastet werden. Dies ist bekannt als Schreibverstärkung . Daher ist es im Allgemeinen bei niedrigen Spitzenlastzeiten geplant.
Ein weiterer Prozess zur Leistungsoptimierung, den ich diskutieren werde, ist Region Split . Dies ist sehr wichtig für den Lastausgleich.
HBase-Architektur: Region Split
Die folgende Abbildung zeigt den Mechanismus zur Aufteilung der Region.
Wenn eine Region groß wird, wird sie in zwei untergeordnete Regionen unterteilt, wie in der obigen Abbildung gezeigt. Jede Region repräsentiert genau die Hälfte der übergeordneten Region. Diese Aufteilung wird dann dem HMaster gemeldet. Dies wird von demselben Regionsserver erledigt, bis der HMaster sie einem neuen Regionsserver zum Lastenausgleich zuweist.
Zu guter Letzt werde ich Ihnen erklären, wie HBase nach einem Fehler Daten wiederherstellt. Wie wir das wissen Fehlerbehebung ist ein sehr wichtiges Merkmal von HBase. Lassen Sie uns daher wissen, wie HBase Daten nach einem Fehler wiederherstellt.
HBase-Architektur: HBase-Absturz und Datenwiederherstellung
- Wenn ein Regionsserver ausfällt, benachrichtigt ZooKeeper den HMaster über den Fehler.
- Anschließend verteilt HMaster die Regionen des abgestürzten Region Servers und weist sie vielen aktiven Region Servern zu. Um die Daten des MemStore des ausgefallenen Region Servers wiederherzustellen, verteilt der HMaster die WAL an alle Region Server.
- Jeder Region Server führt die WAL erneut aus, um den MemStore für die Spaltenfamilie dieser ausgefallenen Region zu erstellen.
- Die Daten werden in chronologischer Reihenfolge (in zeitnaher Reihenfolge) in WAL geschrieben. Wenn Sie diese WAL erneut ausführen, müssen Sie daher alle Änderungen vornehmen, die in der MemStore-Datei vorgenommen und gespeichert wurden.
- Nachdem alle Region Server die WAL ausgeführt haben, werden die MemStore-Daten für alle Spaltenfamilien wiederhergestellt.
Ich hoffe, dieser Blog hätte Ihnen geholfen, das HBase-Datenmodell und die HBase-Architektur zu verstehen. Hoffe es hat euch gefallen. Jetzt können Sie sich auf die Funktionen von HBase beziehen (die ich in meinem vorherigen erklärt habe HBase Tutorial Blog) mit HBase Architecture und verstehen, wie es intern funktioniert. Nachdem Sie den theoretischen Teil von HBase kennen, sollten Sie zum praktischen Teil übergehen. Vor diesem Hintergrund unser nächster Blog von wird ein Beispiel erklären HBase POC .
Nachdem Sie die HBase-Architektur verstanden haben, lesen Sie die von Edureka, einem vertrauenswürdigen Online-Lernunternehmen mit einem Netzwerk von mehr als 250.000 zufriedenen Lernenden auf der ganzen Welt. Der Edureka Big Data Hadoop-Zertifizierungskurs hilft Lernenden, Experten für HDFS, Garn, MapReduce, Schwein, Bienenstock, HBase, Oozie, Flume und Sqoop zu werden. Dabei werden Anwendungsfälle in Echtzeit in den Bereichen Einzelhandel, soziale Medien, Luftfahrt, Tourismus und Finanzen verwendet.
Hast du eine Frage an uns? Bitte erwähnen Sie es in den Kommentaren und wir werden uns bei Ihnen melden.