
In diesem Blog werden wir über ein Beispiel für einen Proof of Concept für HBase diskutieren.
Hier haben wir einen Datensatz wie im folgenden Bild.
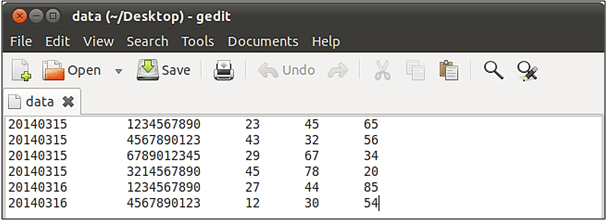
Dieser Datensatz enthält die Details zur Dauer der gesamten eingehenden, ausgehenden Anrufe und der Nachrichten, die von einer bestimmten Mobiltelefonnummer an einem bestimmten Datum gesendet wurden.
Das erste Feld repräsentiert das Datum, das zweite Feld repräsentiert die Handynummer, das dritte Feld repräsentiert die Gesamtdauer eingehender Anrufe, das vierte Feld repräsentiert die Gesamtdauer ausgehender Anrufe und das fünfte Feld repräsentiert die Gesamtzahl der gesendeten Nachrichten.
Jetzt besteht unsere Aufgabe darin, die Informationen über die Dauer eingehender und ausgehender Anrufe und gesendeter Nachrichten von einer Telefonnummer an einem bestimmten Datum abzurufen.
In diesem Anwendungsfall versuche ich, die Datensätze von 15 zu filternthMärz 2014. Hier ist ein HBase-Programm, um dies zu erreichen.
Unten finden Sie den vollständigen Code.
Öffentlichkeit Klasse Stichprobe{
Was ist die beste Idee für Java
Privat statisch Aufbau conf
statisch HTable Tabelle
Öffentlichkeit Beispiel (String tableName, String colFams) wirft IOException {
conf = HBaseConfiguration. erstellen ()
createTable (tableName, colFams)
Tabelle = Neu HTable ( conf , Tabellenname)
}}
Leere createTable (String tableName, String colFams) wirft IOException {
HBaseAdmin hbase = Neu HBaseAdmin ( conf )
HTableDescriptor desc = Neu HTableDescriptor (tableName)
HColumnDescriptor meta = Neu HColumnDescriptor (colFams.getBytes ())
desc.addFamily (meta)
hbase.createTable (desc)
}}
Öffentlichkeit statisch Leere addColumnEntry (String tableName, String row,
String colFamilyName, String colName, String-Werte)
wirft IOException {
Byte [] rowKey = Bytes. toBytes (Reihe)
Put putdata = Neu Put (rowKey)
putdata.add (Bytes. toBytes (colFamilyName), Bytes. toBytes (colName),
Bytes. toBytes (Werte))
Tabelle .put (putdata)
}}
Öffentlichkeit statisch Leere getAllRecord (String tableName, String startPartialKey,
String endPartialKey) wirft IOException {
Versuchen {
Scannen s
wenn (startPartialKey == Null || endPartialKey == Null )
s = Neu Scan()
sonst
s = Neu Scannen (Bytes. toBytes (startPartialKey),
Bytes. toBytes (endPartialKey))
ResultScanner ss = Tabelle .getScanner (s)
HashMap
String imsi = ''
zum (Ergebnis r: ss) {
HashMap keyVal = Neu HashMap ()
zum (KeyValue kv: r.raw ()) {
imsi = Neu String (kv.getRow ()). Teilzeichenfolge (10)
keyVal.put ( Neu String (kv.getQualifier ()),
Neu String (kv.getValue ()))
outputRec.put (imsi, keyVal)
wenn (keyVal.size () == 3)
System. aus .println (nimm + ”” + “Eingehende Minuten:”
+ keyVal.get ('c1') + 'Ausgehende Minuten:'
+ keyVal.get ('c2') + 'Nachrichten:'
+ keyVal.get ('c3'))
}}
}}
}} schließlich {
}}
}}
Öffentlichkeit statisch Leere main (String [] args) wirft IOException {
String tableName = 'Datenaufzeichnungen'
String colFamilyNames = 'i'
Probentest = Neu Beispiel (tableName, colFamilyNames)
String fileName = '/ home / cloudera / Desktop / data'
// Dies verweist jeweils auf eine Zeile
String line = Null
Versuchen {
// FileReader liest Textdateien in der Standardcodierung.
FileReader fileReader = Neu FileReader (Dateiname)
// DateiReader immer in BufferedReader einschließen.
BufferedReader bufferedReader = Neu BufferedReader (fileReader)
während ((line = bufferedReader.readLine ())! = Null ) {
String [] values = line.split (”“)
addColumnEntry (Tabellenname, Werte [0] + '-' + Werte [1],
colFamilyNames, 'c1', Werte [2])
addColumnEntry (Tabellenname, Werte [0] + '-' + Werte [1],
colFamilyNames, 'c2', Werte [3])
addColumnEntry (Tabellenname, Werte [0] + '-' + Werte [1],
colFamilyNames, 'c3', Werte [4])
}}
bufferedReader.close ()
}} Fang (FileNotFoundException ex) {
System. aus .println ('Datei kann nicht geöffnet werden' + Dateiname + '')
}} Fang (IOException ex) {
System. aus .println ('Fehler beim Lesen der Datei' + Dateiname + ')'
// Oder wir könnten einfach das machen:
// ex.printStackTrace ()
}}
getAllRecord (tableName, '20140315', '20140316')
}}
}}
Hier haben wir ein Objekt der Konfiguration, der HTable-Klasse und der Hbase-Tabelle mit dem Namen erstellt: Datenaufzeichnungen und die Spaltenfamilie: ich .
In diesem Anwendungsfall verwenden wir die durch '-' getrennte Kombination aus Datum und Handynummer als Zeilenschlüssel für diese Hbase-Tabelle und die Dauer eingehender, ausgehender Anrufe ', die Anzahl der als Spalten' c1 'gesendeten Nachrichten.' c2 ',' c3 'für die Spaltenfamilie' i '.
Wir haben die Eingabedaten im lokalen Dateisystem von Cloudera gespeichert. Wir müssen also Java Logic schreiben, das die Daten aus der Datei liest.
Unten ist die Java-Logik.
Bei dieser Methode speichern wir die Daten in der Tabelle für jede Spalte der Spaltenfamilie.
Mit dem Befehl scan können wir die in der Hbase-Tabelle 'Datenaufzeichnungen' gespeicherten Daten überprüfen.
Sie erhalten die Daten wie im Bild unten.
Jetzt haben wir die Daten erfolgreich in die HBase-Tabelle eingefügt.
Lassen Sie uns die Datensätze abrufen, die in der Tabelle eines bestimmten Datums gespeichert sind.
In diesem Anwendungsfall versuchen wir, die Datensätze des Datums abzurufen: 15thMarz 2014
Um die Datensätze abzurufen, haben wir eine Methode erstellt
getAllRecord (String tableName, String startPartialKey, String endPartialKey)
Der erste Parameter repräsentiert den Tabellennamen, der zweite das Startdatum, ab dem die Daten abgerufen werden müssen, und der dritte das nächste Datum des Startdatums.
Z.B:
getAllRecord (tableName, '20140315', '20140316')
Lassen Sie uns nun das verstehen Logik dieser Methode.
Wir versuchen, die Hbase-Tabelle mithilfe der HBase-API mithilfe von startPartialKey und endPartialKey zu scannen.
Da StartPartialKey und endPartialkey nicht null sind, werden die Datensätze mit dem Wert startPartialKey blockiert und gescannt.
Hadoop Entwickler Rollen und Verantwortlichkeiten
Wir haben ein Objekt des Ergebnisscanners erstellt, in dem die gescannten Datensätze der Hbase-Tabelle und eine HashMap gespeichert werden, um die Ausgabe zu speichern, die das Ergebnis sein wird.
Wir erstellen ein Ergebnisobjekt, um den Datenspeicher im Ergebnisscanner abzurufen und eine for-Schleife auszuführen.
imsi ist die Zeichenfolge, die zum Speichern der Mobiltelefonnummer definiert ist, und keyVal ist eine Hash-Map, in der die aus der Spalte eines bestimmten Telefons abgerufene Ausgabe gespeichert wird.
Wir haben gegeben 20140315-1234567890 als die Rowkey zur Hbase-Tabelle. In diesem 20140315 steht das Datum und 1234567890 steht für die Handynummer.
Da wir nur die Handynummer benötigen, verwenden wir die Teilstring-Methode, um sie abzurufen.
Wir rufen die Daten von r.raw () ab und speichern sie mit Put in der HashMap.
Schließlich versuchen wir, sie auf der Konsole zu drucken.
Die Ausgabe erfolgt wie im folgenden Bild.
Wir haben die Aufzeichnungen des Datums: 15 erfolgreich abgerufenthMarz 2014.