
In diesem Blog werden wir Scikit Learn in Python diskutieren. Bevor man über Scikit-Lernen spricht, muss man das Konzept des maschinellen Lernens verstehenund muss wissen, wie man es benutzt . Beim maschinellen Lernen müssen Sie Ihre Erkenntnisse nicht manuell sammeln. Sie brauchen nur einen Algorithmus und die Maschine erledigt den Rest für Sie! Ist das nicht aufregend? Scikit-Lernen ist eine der Attraktionen, bei denen wir maschinelles Lernen mit Python implementieren können. Esist eine kostenlose Bibliothek für maschinelles Lernen, die einfache und effiziente Tools für Datenanalyse- und Miningzwecke enthält.Ich werde Sie durch die folgenden Themen führen, die als Grundlagen für die kommenden Blogs dienen:
Was ist maschinelles Lernen?
Maschinelles Lernen ist eine Art künstlicher Intelligenz, mit der Softwareanwendungen aus den Daten lernen und die Ergebnisse ohne menschliches Eingreifen genauer vorhersagen können. Aber wie passiert das? Dazu muss die Maschine auf einige Daten trainiert werden und auf dieser Grundlage erkennt sie ein Muster, um ein Modell zu erstellen.Bei diesem Prozess, Wissen aus den Daten zu gewinnen und aussagekräftige Erkenntnisse zu liefern, dreht sich alles um maschinelles Lernen. Sehen Sie sich das folgende Bild an, um ein besseres Verständnis der Funktionsweise zu erhalten:
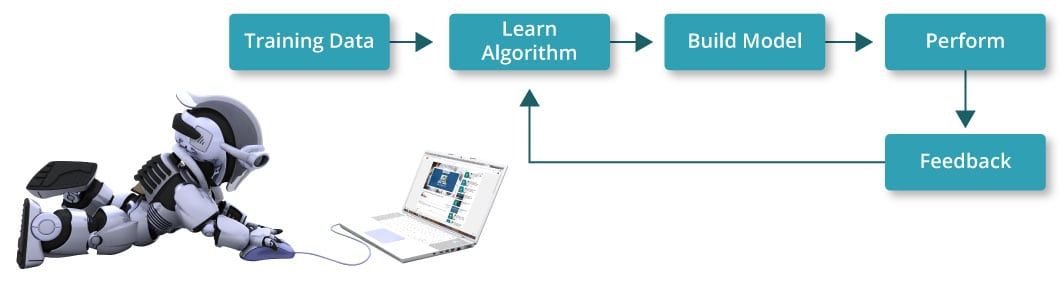
Anhand der Daten lernt das System einen Algorithmus und erstellt daraus ein Vorhersagemodell. Später passen wir das Modell an oder verbessern die Genauigkeit des Modells mithilfe der Feedback-Daten. Mit diesen Feedback-Daten optimieren wir das Modell und sagen die Aktion für den neuen Datensatz voraus. Wir werdendiskutieren a Anwendungsfall eines der Algorithmus-Ansätze, bei denen wir die Daten trainieren und testen, um Ihnen ein besseres Gefühl dafür zu geben, ob sie für Ihr spezielles Problem gut geeignet sind oder nicht.
Als nächstes gibt es drei Arten des maschinellen Lernens:
- Überwachtes Lernen : Dies ist ein Prozess eines Algorithmus, der aus dem Trainingsdatensatz lernt. Beim überwachten Lernen generieren Sie eine Zuordnungsfunktion zwischen der Eingabevariablen (X) und einer Ausgabevariablen (Y) und verwenden einen Algorithmus, um eine Funktion zwischen ihnen zu generieren. Es ist auch als Vorhersagemodellierung bekannt, die sich auf einen Prozess bezieht, bei dem Vorhersagen unter Verwendung der Daten getroffen werden. Einige der Algorithmen umfassen lineare Regression, logistische Regression, Entscheidungsbaum, Zufallswald und Naive Bayes-Klassifikator. Wir werden einen Anwendungsfall des überwachten Lernens weiter diskutieren, bei dem wir die Maschine mit trainieren logistische Regression .
- Unbeaufsichtigtes Lernen : Dies ist ein Prozess, bei dem ein Modell anhand von Informationen trainiert wird, die nicht gekennzeichnet sind. Dieser Prozess kann verwendet werden, um die Eingabedaten auf der Grundlage ihrer statistischen Eigenschaften in Klassen zu gruppieren. Unbeaufsichtigtes Lernen wird auch als c bezeichnetGlanzanalyse, dh die Gruppierung von Objekten basierend auf den Informationen in den Daten, die die Objekte oder ihre Beziehung beschreiben. Das Ziel ist, dass Objekte in einer Gruppe einander ähnlich sein sollten, sich jedoch von Objekten in einer anderen Gruppe unterscheiden. Einige der Algorithmen umfassen K-Mittel-Clustering, hierarchisches Clustering usw.
- Verstärkungslernen: Reinforcement Learning ist Lernen durch Interaktion mit einem Raum oder einer Umgebung.Ein RL-Agent lernt aus den Konsequenzen seiner Handlungen, anstatt explizit unterrichtet zu werden. Es wählt seine Handlungen auf der Grundlage seiner früheren Erfahrungen (Ausbeutung) und auch durch neue Entscheidungen (Erkundung) aus.
- Überwachtes Lernen : Dies ist ein Prozess eines Algorithmus, der aus dem Trainingsdatensatz lernt. Beim überwachten Lernen generieren Sie eine Zuordnungsfunktion zwischen der Eingabevariablen (X) und einer Ausgabevariablen (Y) und verwenden einen Algorithmus, um eine Funktion zwischen ihnen zu generieren. Es ist auch als Vorhersagemodellierung bekannt, die sich auf einen Prozess bezieht, bei dem Vorhersagen unter Verwendung der Daten getroffen werden. Einige der Algorithmen umfassen lineare Regression, logistische Regression, Entscheidungsbaum, Zufallswald und Naive Bayes-Klassifikator. Wir werden einen Anwendungsfall des überwachten Lernens weiter diskutieren, bei dem wir die Maschine mit trainieren logistische Regression .
Übersicht über Scikit Learn
Scikit Learn ist eine Bibliothek, mit der maschinelles Lernen in Python durchgeführt wird. Scikit learn ist eine Open-Source-Bibliothek, die unter BSD lizenziert ist und in verschiedenen Kontexten wiederverwendet werden kann, um die akademische und kommerzielle Nutzung zu fördern. Es bietet eine Reihe von überwachten und unbeaufsichtigten Lernalgorithmen in Python.Scikit Learn besteht aus gängigen Algorithmen und Bibliotheken. Abgesehen davon enthält es auch die folgenden Pakete:
Was ist Salesforce Service Cloud?
- NumPy
- Matplotlib
- SciPy (wissenschaftliches Python)
Um Scikit Learn zu implementieren, müssen wir zuerst die oben genannten Pakete importieren. Wenn Sie mit diesen Bibliotheken nicht vertraut sind, können Sie sich meine vorherigen Blogs ansehen und . Sie können diese beiden Pakete über die Befehlszeile oder bei Verwendung von P herunterladenY.Charm, Sie können es direkt installieren, indem Sie zu Ihrer Einstellung gehen, genauso wie Sie es für andere Pakete tun.
Als nächstes auf ähnliche Weisemüssen Sie Sklearn importieren.Scikit learn basiert auf SciPy (Scientific Python), das installiert werden muss, bevor Sie Scikit-learn verwenden können. Sie können sich darauf beziehen Webseite um das gleiche herunterzuladen. Installieren Sie auch Scipy und das Radpaket, falls es nicht vorhanden ist. Geben Sie den folgenden Befehl ein:
pip install scipyIch habe es bereits heruntergeladen und installiert. Weitere Informationen finden Sie im folgenden Screenshot.
Lassen Sie uns nach dem Importieren der oben genannten Bibliotheken genauer untersuchen, wie genau Scikit Learn verwendet wird.
Scikit Learn wird mit Beispieldatensätzen geliefert, z Iris und Ziffern . Sie können die Datensätze importieren und damit herumspielen. Danach müssen Sie SVM importieren, das für Support Vector Machine steht. SVM ist eine Form des maschinellen Lernens, mit der Daten analysiert werden.
Nehmen wir ein Beispiel, wohin wir gehen werden Ziffern Datensatz und es wird die Zahlen für uns kategorisieren, zum Beispiel- 0 1 2 3 4 5 6 7 8 9. Siehe den folgenden Code:
importiere matplotlib.pyplot als plt von sklearn importiere Datensätze von sklearn importiere svm digits = datasets.load_digits () print (digits.data)
Ausgabe -
[[0. 0. 5. ..., 0. 0. 0.] [0. 0. 0. ..., 10. 0. 0.] [0. 0. 0. ..., 16. 9. 0.] ..., [0. 0. 1. ..., 6. 0. 0.] [0. 0. 2. ..., 12. 0. 0.] [0. 0. 10. ..., 12. 1. 0.]]
Hier haben wir gerade die Bibliotheken, SVM, Datensätze importiert und die Daten gedruckt. Es handelt sich um eine lange Reihe von Ziffern, in denen die Daten gespeichert sind. Es gibt den Zugriff auf die Funktionen, die zur Klassifizierung der verwendet werden können Ziffern Proben. Als Nächstes können Sie auch einige andere Vorgänge wie Ziel, Bilder usw. ausprobieren. Betrachten Sie das folgende Beispiel:
importiere matplotlib.pyplot als plt von sklearn importiere Datensätze von sklearn importiere svm digits = datasets.load_digits () print (digits.target) print (digits.images [0])
Ausgabe - -
[0 1 2 ..., 8 9 8] // Ziel der Daten [[0. 0. 5. 13. 9. 1. 0. 0.] // Bild der Daten [0. 0. 13. 15. 10. 15. 5. 0.] [0. 3. 15. 2. 0. 11. 8. 0.] [0. 4. 12. 0. 0. 8. 8. 0.] [0. 5. 8. 0. 0. 9. 8. 0.] [0. 4. 11. 0. 1. 12. 7. 0.] [0. 2. 14. 5. 10. 12. 0. 0. ] [0. 0. 6. 13. 10. 0. 0. 0.]]
Wie Sie oben sehen können, werden die Zielziffern und das Bild der Ziffern gedruckt. digits.target gibt die Grundwahrheit für die Ziffer Datensatz, das ist die Nummer, die jedem Ziffernbild entspricht. Als nächstes sind Daten immer ein 2D-Array, das eine Form hat (n_samples, n_features), obwohl die ursprünglichen Daten möglicherweise eine andere Form hatten. Bei den Ziffern ist jedoch jedes Originalmuster ein Bild der Form (8,8) und kann mit verwendet werden Ziffern . Bild.
wie man sort in c ++ benutzt
Lernen und Vorhersagen
Als nächstes haben wir in Scikit learn einen Datensatz verwendet (Stichprobe von 10 möglichen Klassen, Ziffern von null bis neun) und müssen die Ziffern vorhersagen, wenn ein Bild gegeben wird. Um die Klasse vorherzusagen, brauchen wir eine Schätzer Dies hilft bei der Vorhersage der Klassen, zu denen unsichtbare Stichproben gehören. In Scikit Learn haben wir einen Schätzer für die Klassifizierung, bei dem es sich um ein Python-Objekt handelt, das die Methoden implementiert fit (x, y) und vorhersagen (T). Betrachten wir das folgende Beispiel:
importiere matplotlib.pyplot als plt von sklearn importiere Datensätze von sklearn importiere svm digits = datasets.load_digits () // Datensatz clf = svm.SVC (gamma = 0,001, C = 100) print (len (digits.data)) x, y = digits.data [: - 1], digits.target [: - 1] // trainiere die Daten clf.fit (x, y) print ('Vorhersage:', clf.predict (digits.data [-1]) ) // Vorhersage der Daten plt.imshow (digits.images [-1], cmap = plt.cm.gray_r, Interpolation = 'next') plt.show ()Ausgabe -
1796
Vorhersage: [8]
Im obigen Beispiel hatten wir zuerst die Länge gefunden und 1796 Beispiele geladen. Als nächstes haben wir diese Daten als Lerndaten verwendet, wo wir das letzte Element und das erste negative Element testen müssen. Außerdem müssen wir prüfen, ob die Maschine die richtigen Daten vorhergesagt hat oder nicht. Dafür hatten wir Matplotlib verwendet, wo wir das Bild der Ziffern angezeigt hatten.Abschließend haben Sie also Ziffern, Sie haben das Ziel, Sie passen es an und sagen es voraus, und daher können Sie loslegen! Es ist wirklich schnell und einfach, oder?
Sie können die Zielbeschriftungen auch mit einem Bild visualisieren. Lesen Sie dazu einfach den folgenden Code:
importiere matplotlib.pyplot als plt von sklearn importiere Datensätze von sklearn importiere svm digits = datasets.load_digits () # Füge die Bilder und Zielbezeichnungen in einer Liste zusammen images_and_labels = list (zip (digits.images, digits.target)) # für jedes Element in der Liste für den Index (Bild, Beschriftung) in Aufzählung (images_and_labels [: 8]): # Initialisiere eine Unterzeichnung von 2X4 an der i + 1-ten Position plt.subplot (2, 4, index + 1) # Zeige Bilder an in allen Unterplots plt.imshow (Bild, cmap = plt.cm.gray_r, Interpolation = 'am nächsten') # Fügen Sie jedem Unterplot einen Titel hinzu plt.title ('Training:' + str (label)) # Zeigen Sie den Plot plt. Show()Ausgabe- -
Wie Sie im obigen Code sehen können, haben wir die Funktion 'zip' verwendet, um die Bilder und Zielbeschriftungen in einer Liste zusammenzufügen und sie dann in einer Variablen zu speichern, z. B. images_and_labels. Danach haben wir die ersten acht Elemente in einem Raster von 2 mal 4 an jeder Position indiziert. Danach haben wir die Bilder mit Hilfe von Matplotlib angezeigt und den Titel als 'Training' hinzugefügt.
Anwendungsfall - - Vorhersage mit logistischer Regression
Problemstellung - - Eine Autofirma hat einen neuen SUV auf den Markt gebracht. Anhand der vorherigen Daten über den Verkauf ihrer SUVs möchten sie die Kategorie der Personen vorhersagen, die möglicherweise daran interessiert sind, diese zu kaufen.
Lassen Sie uns dazu einen Datensatz sehen, wo ich habe Benutzer-ID, Geschlecht, Alter, geschätztes Gehalt und gekauft als Spalten. Dies ist nur ein Beispieldatensatz, von dem Sie den gesamten Datensatz herunterladen können Hier . Sobald wir die Daten in pyCharm importiert haben, sieht es ungefähr so aus.
Lassen Sie uns nun diese Daten verstehen. Wie Sie im obigen Datensatz sehen können, haben wir Kategorien wie ID, Geschlecht, Alter usw. Basierend auf diesen Kategorien werden wir nun unsere Maschine trainieren und die Nr. Voraussagen. von Einkäufen. Also hier haben wir unabhängige Variablen als 'Alter', 'erwartetes Gehalt' und abhängige Variable als 'gekauft'. Jetzt werden wir überwachtes Lernen anwenden, d.h. logistischer Regressionsalgorithmus um die Anzahl der Käufe anhand der vorhandenen Daten herauszufinden.
Lassen Sie uns zunächst einen Überblick über die logistische Regression erhalten.
Logistische Regression - Die logistische Regression erzeugt Ergebnisse in einem Binärformat, mit dem das Ergebnis einer kategorial abhängigen Variablen vorhergesagt wird. Es wird am häufigsten verwendet, wenn die abhängige Variable binär ist, d. H. Die Anzahl der verfügbaren Kategorien beträgt zwei, z. B. sind die üblichen Ausgaben der logistischen Regression -
- Ja und nein
- Richtig und falsch
- Hoch und Tief
- Bestanden und nicht bestanden
Zunächst importieren wir diese Bibliotheken - Numpy, Matplotlib und Pandas. Es ist ziemlich einfach, Pandas in Pycharm zu importieren, indem Sie die folgenden Schritte ausführen:
Einstellungen -> Paket hinzufügen -> Pandas -> Installieren Danach importieren wir den Datensatz und trennen die abhängige Variable (gekauft) und die unabhängige Variable (Alter, Gehalt) nach:
MySQL Workbench Tutorial für Anfänger
Dataset = pd.read_csv ('Social_Network_Ads.csv') X = Dataset.iloc [:, [2, 3]]. Werte y = Dataset.iloc [:, 4] .Werte print (X) print (y)Der nächste Schritt wäre das Trainieren und Testen der Daten. Eine übliche Strategie besteht darin, alle gekennzeichneten Daten in Trainings- und Testuntergruppen aufzuteilen, die normalerweise mit einem Verhältnis von 70-80% für die Trainingsuntermenge und 20-30% für die Testuntermenge verwendet werden. Aus diesem Grund haben wir mithilfe von cross_validation Trainings- und Testsätze erstellt.
aus sklearn.cross_validation importiere train_test_split X_train, X_test, y_train, y_test = train_test_split (X, y, test_size = 0.25, random_state = 0)
Wir können die Eingabewerte auch für eine bessere Leistung mit StandarScaler skalieren, wie unten gezeigt:
aus sklearn.preprocessing importieren StandardScaler sc = StandardScaler () X_train = sc.fit_transform (X_train) X_test = sc.transform (X_test)
Jetzt erstellen wir unser logistisches Regressionsmodell.
aus sklearn.linear_model import LogisticRegression classifier = LogisticRegression (random_state = 0) classifier.fit (X_train, y_train)
Wir können dies nutzen und die Ergebnisse unseres Testsatzes vorhersagen.
y_pred = classifier.predict (X_test)
Jetzt können wir überprüfen, wie viele Vorhersagen genau waren und wie viele nicht verwendet wurden Verwirrung Matrix . Definieren wir Y als positive Instanzen und N als negative Instanzen. Die vier Ergebnisse sind in einer 2 * 2-Verwirrungsmatrix formuliert, wie unten dargestellt:
aus sklearn.metrics importieren verwirrung_matrix cm = verwirrungsmatrix (y_test, y_pred) print (cm)
Ausgabe- -
[[65 3] [8 24]]
Als nächstes können wir basierend auf unserer Verwirrungsmatrix die Genauigkeit berechnen. In unserem obigen Beispiel wäre die Genauigkeit also:
= TP + TN / FN + FP
= 65 + 24/65 +3+ 8 + 24
= 89%
Wir haben das manuell gemacht! Lassen Sie uns nun sehen, wie die Maschine dasselbe für uns berechnet. Dafür haben wir eine eingebaute Funktion 'Genauigkeit_Wert', die die Genauigkeit berechnet und druckt, wie unten gezeigt:
aus sklearn.metrics importiere Genauigkeit_score // importiere die Funktion Genauigkeit_score print (Genauigkeit_score (y_test, y_pred) * 100) // druckt die Genauigkeit
Ausgabe -
89,0
Hurra! Wir haben daher die logistische Regression mit Scikit Learn mit einer Genauigkeit von 89% erfolgreich implementiert.
Klick hier um die vollständige Quelle der obigen Vorhersage zu erhalten Verwenden der Python Scikit-Lernbibliothek.
Damit haben wir nur einen der vielen populären Algorithmen behandelt, die Python zu bieten hat.Wir haben alle Grundlagen von Scikit behandelt. Lernen Sie die Bibliothek.So können Sie jetzt mit dem Üben beginnen. Je mehr Sie üben, desto mehr werden Sie lernen. Freut euch auf weitere Python-Tutorial-Blogs!
Hast du eine Frage an uns? Bitte erwähne es im Kommentarbereich dieses 'Scikit learn' -Blogs und wir werden uns so schnell wie möglich bei dir melden. Sie können sich eingehend mit Python und seinen verschiedenen Anwendungen vertraut machen für Live-Online-Schulungen mit 24-Stunden-Support und lebenslangem Zugriff.