
Im Konzeptlernen kann als „ ein Problem der Suche in einem vordefinierten Raum potenzieller Hypothesen nach der Hypothese, die am besten zu den Trainingsbeispielen passt “- Tom Mitchell. In diesem Artikel werden wir einen solchen Konzeptlernalgorithmus durchgehen, der als Find-S-Algorithmus bekannt ist. Die folgenden Themen werden in diesem Artikel behandelt.
- Was ist der Find-S-Algorithmus beim maschinellen Lernen?
- Wie funktioniert es?
- Einschränkungen des Find-S-Algorithmus
- Implementierung des Find-S-Algorithmus
- Anwendungsfall
Was ist der Find-S-Algorithmus beim maschinellen Lernen?
Um den Find-S-Algorithmus zu verstehen, müssen Sie auch eine grundlegende Vorstellung von den folgenden Konzepten haben:
- Konzept lernen
- Allgemeine Hypothese
- Spezifische Hypothese
1. Konzept lernen
Versuchen wir, das Konzeptlernen anhand eines Beispiels aus der Praxis zu verstehen. Der größte Teil des menschlichen Lernens basiert auf früheren Instanzen oder Erfahrungen. Zum Beispiel können wir jeden Fahrzeugtyp anhand eines bestimmten Satzes von Merkmalen wie Marke, Modell usw. identifizieren, die über einen großen Satz von Merkmalen definiert sind.
Diese Besonderheiten unterscheiden den Satz von Autos, Lastwagen usw. von dem größeren Satz von Fahrzeugen. Diese Funktionen, die den Satz von Autos, Lastwagen usw. definieren, werden als Konzepte bezeichnet.
Ähnlich können Maschinen auch aus Konzepten lernen, um festzustellen, ob ein Objekt zu einer bestimmten Kategorie gehört oder nicht. Irgendein Das Konzeptlernen unterstützt Folgendes:
- Trainingsdaten
- Zielkonzept
- Aktuelle Datenobjekte
2. Allgemeine Hypothese
Die Hypothese ist im Allgemeinen eine Erklärung für etwas. Die allgemeine Hypothese gibt grundsätzlich die allgemeine Beziehung zwischen den Hauptvariablen an. Eine allgemeine Hypothese für die Bestellung von Lebensmitteln wäre beispielsweise Ich will einen Burger.
G = {'?', '?', '?', ... '?'}
3. Spezifische Hypothese
Die spezifische Hypothese füllt alle wichtigen Details zu den in der allgemeinen Hypothese angegebenen Variablen aus. Die spezifischeren Details in dem oben angegebenen Beispiel wären Ich möchte einen Cheeseburger mit einer Hühnchen-Peperoni-Füllung mit viel Salat.
S = {'& Phi', '& Phi', '& Phi', ..., '& Phi'}
Lassen Sie uns nun über den Find-S-Algorithmus beim maschinellen Lernen sprechen.
wie man br in html benutzt
Der Find-S-Algorithmus folgt den folgenden Schritten:
- Initialisieren Sie 'h' mit der spezifischsten Hypothese.
- Der Find-S-Algorithmus berücksichtigt nur die positiven Beispiele und eliminiert negative Beispiele. Für jedes positive Beispiel prüft der Algorithmus jedes Attribut im Beispiel. Wenn der Attributwert mit dem Hypothesenwert übereinstimmt, wird der Algorithmus ohne Änderungen fortgesetzt. Wenn sich der Attributwert jedoch vom Hypothesenwert unterscheidet, ändert der Algorithmus ihn in '?'.
Nachdem wir mit der grundlegenden Erklärung des Find-S-Algorithmus fertig sind, schauen wir uns an, wie er funktioniert.
Wie funktioniert es?
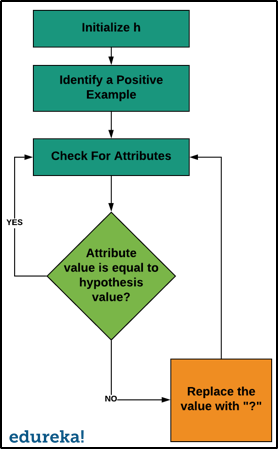
- Der Prozess beginnt mit der Initialisierung von 'h' mit der spezifischsten Hypothese. Im Allgemeinen ist dies das erste positive Beispiel im Datensatz.
- Wir prüfen jedes positive Beispiel. Wenn das Beispiel negativ ist, fahren wir mit dem nächsten Beispiel fort. Wenn es sich jedoch um ein positives Beispiel handelt, werden wir es für den nächsten Schritt berücksichtigen.
- Wir werden prüfen, ob jedes Attribut im Beispiel dem Hypothesenwert entspricht.
- Wenn der Wert übereinstimmt, werden keine Änderungen vorgenommen.
- Wenn der Wert nicht übereinstimmt, wird der Wert in '?' Geändert.
- Wir tun dies, bis wir das letzte positive Beispiel im Datensatz erreichen.
Einschränkungen des Find-S-Algorithmus
Es gibt einige Einschränkungen des unten aufgeführten Find-S-Algorithmus:
- Es gibt keine Möglichkeit festzustellen, ob die Hypothese in allen Daten konsistent ist.
- Inkonsistente Trainingssätze können den Find-S-Algorithmus tatsächlich irreführen, da die negativen Beispiele ignoriert werden.
- Der Find-S-Algorithmus bietet keine Backtracking-Technik, um die bestmöglichen Änderungen zu ermitteln, die zur Verbesserung der resultierenden Hypothese vorgenommen werden könnten.
Nachdem wir uns der Einschränkungen des Find-S-Algorithmus bewusst sind, werfen wir einen Blick auf eine praktische Implementierung des Find-S-Algorithmus.
Implementierung des Find-S-Algorithmus
Um die Implementierung zu verstehen, versuchen wir, sie in einen kleineren Datensatz mit einer Reihe von Beispielen zu implementieren, um zu entscheiden, ob eine Person spazieren gehen möchte.
Wie erstelle ich ein Array von Objekten in Java?
Das Konzept dieses speziellen Problems wird sein, an welchen Tagen eine Person gerne spazieren geht.
| Zeit | Wetter | Temperatur | Unternehmen | Feuchtigkeit | Wind | Geht |
| Morgen | Sonnig | Warm | Ja | Leicht | Stark | Ja |
| Abend | Regnerisch | Kalt | Nein | Leicht | Normal | Nein |
| Morgen | Sonnig | Mäßig | Ja | Normal | Normal | Ja |
| Abend | Sonnig | Kalt | Ja | Hoch | Stark | Ja |
Wenn wir uns den Datensatz ansehen, haben wir sechs Attribute und ein letztes Attribut, das das positive oder negative Beispiel definiert. In diesem Fall ist ja ein positives Beispiel, was bedeutet, dass die Person spazieren gehen wird.
Die allgemeine Hypothese lautet nun:
h0= {'Morgen', 'Sonnig', 'Warm', 'Ja', 'Mild', 'Stark'}
Dies ist unsere allgemeine Hypothese, und jetzt werden wir jedes Beispiel einzeln betrachten, aber nur die positiven Beispiele.
hein= {'Morgen', 'Sonnig', '?', 'Ja', '?', '?'}
h2= {'?', 'Sonnig', '?', 'Ja', '?', '?'}
Wir haben alle unterschiedlichen Werte in der allgemeinen Hypothese ersetzt, um eine resultierende Hypothese zu erhalten. Nachdem wir nun wissen, wie der Find-S-Algorithmus funktioniert, werfen wir einen Blick auf eine Implementierung mit Python .
Anwendungsfall
Versuchen wir, das obige Beispiel mit zu implementieren . Der Code zum Implementieren des Find-S-Algorithmus unter Verwendung der obigen Daten ist unten angegeben.
Pandas als pd importieren numpy als np importieren # um die Daten in der CSV-Datei zu lesen data = pd.read_csv ('data.csv') print (data, 'n') # ein Array aller Attribute d = np.array erstellen (Daten) [:,: - 1] print ('n Die Attribute sind:', d) #segragieren des Ziels mit positiven und negativen Beispielen target = np.array (Daten) [:, - 1] print ('n Das Ziel ist: ', Ziel) # Trainingsfunktion zum Implementieren des Suchalgorithmus def train (c, t): für i, val in enumerate (t): wenn val ==' Ja ': spezifische_hypothese = c [i]. copy () break für i, val in enumerate (c): wenn t [i] == 'Yes': für x in range (len (spezifische_hypothese)): wenn val [x]! = spezifische_hypothese [x]: spezifische_hypothese [ x] = '?' sonst: pass return different_hypothesis #Erhalten des endgültigen Hypothesentrucks ('n Die endgültige Hypothese lautet:', train (d, target))Ausgabe:
Dies bringt uns zum Ende dieses Artikels, wo wir den Find-S-Algorithmus in Mach gelernt habenine Lernen mit seiner Implementierung und Anwendungsfall. Ich hoffe, Sie sind mit allem klar, was Ihnen in diesem Tutorial mitgeteilt wurde.
Wenn Sie diesen Artikel zum Thema „Find-S-Algorithmus beim maschinellen Lernen“ relevant fanden, lesen Sie die Ein vertrauenswürdiges Online-Lernunternehmen mit einem Netzwerk von mehr als 250.000 zufriedenen Lernenden auf der ganzen Welt.
Wir sind hier, um Ihnen bei jedem Schritt auf Ihrer Reise zu helfen und einen Lehrplan zu erstellen, der für Studenten und Fachleute konzipiert ist, die eine sein möchten . Der Kurs soll Ihnen einen Vorsprung in die Python-Programmierung verschaffen und Sie sowohl für Kern- als auch für fortgeschrittene Python-Konzepte sowie für verschiedene Konzepte schulen mögen , , usw.
Wenn Sie auf Fragen stoßen, können Sie alle Ihre Fragen im Kommentarbereich von „Find-S-Algorithmus beim maschinellen Lernen“ stellen. Unser Team beantwortet diese gerne.