
In diesem Artikel erfahren Sie, wie Sie Kubernetes Cluster-Ereignisdaten bei Amazon veröffentlichen mit Fluentd Logging Agent. Die Daten werden dann mit angezeigt , ein Open-Source-Visualisierungstool für Elasticsearch. Amazon ES besteht aus einer integrierten Kibana-Integration.
Wir werden Sie durch den folgenden Prozess führen:
- Erstellen eines Kubernetes-Clusters
- Erstellen eines Amazon ES-Clusters
- Stellen Sie den Fluentd-Protokollierungsagenten im Kubernetes-Cluster bereit
- Visualisieren Sie das Datum der Kubernetes in Kibana
Schritt 1: Erstellen eines Kubernetes-Clusters
Kubernetes ist eine Open Source-Plattform, die von Google zur Verwaltung von Containeranwendungen entwickelt wurde. Sie können damit Ihre containerisierten Apps in einer Clusterumgebung verwalten, skalieren und bereitstellen. Wir können unsere Container auf verschiedenen Hosts mit orchestrieren Gouverneure Skalieren Sie die containerisierten Apps mit allen Ressourcen im laufenden Betrieb und verfügen Sie über eine zentralisierte Containerverwaltungsumgebung.
Wir beginnen mit der Erstellung des Kubernetes-Clusters und zeigen Ihnen Schritt für Schritt, wie Sie Kubernetes unter CentOS 7 installieren und konfigurieren.
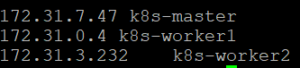
ein. Hosts konfigurieren
- vi / etc / hosts
- Nehmen Sie Änderungen gemäß Ihren Hostdetails in der Hosts-Datei vor
wie man Klassenpfad in Java setzt
2. Deaktivieren Sie SELinux, indem Sie die folgenden Befehle ausführen
- setenforce 0
- sed -i –follow-symlinks 's / SELINUX = erzwingen / SELINUX = deaktiviert / g' / etc / sysconfig / selinux
3. Aktivieren Sie das br_netfilter-Kernelmodul
Das Modul br_netfilter wird für die Installation von kubernetes benötigt. Führen Sie den folgenden Befehl aus, um das Kernelmodul br_netfilter zu aktivieren.- modprobe br_netfilter
- Echo '1'> / proc / sys / net / bridge / bridge-nf-call-iptables
Vier. Deaktivieren Sie SWAP, indem Sie die folgenden Befehle ausführen.
- Swapoff -a
- Bearbeiten Sie dann / etc / fstab und kommentieren Sie die Swap-Zeile
5. Installieren Sie die neueste Version von Docker CE.Installieren Sie die Paketabhängigkeiten für Docker-CE, indem Sie die folgenden Befehle ausführen.
- yum install -y yum-utils Geräte-Mapper-persistente-Daten lvm2
- yum-config-manager –add-repo https://download.docker.com/linux/centos/docker-ce.repo
- yum install -y docker-ce
6. Installieren Sie Kubernetes
Verwenden Sie den folgenden Befehl, um das kubernetes-Repository zum centos 7-System hinzuzufügen.- yum install -y kubelet bebeadm kubectl
[kubernetes] name = Kubernetes baseurl = https: //packages.cloud.google.com/yum/repos/kubernetes-el7-x86_64 enabled = 1 gpgcheck = 1 repo_gpgcheck = 1 gpgkey = https: //packages.cloud.google. com / yum / doc / yum-key.gpg https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg EOFInstalliere das Pakete kubeadm, kubelet und kubectl mit dem folgenden Befehl yum.
- systemctl docker starten && systemctl Docker aktivieren
Starten Sie nach Abschluss der Installation alle diese Server neu.Nach dem Neustart starten Sie die Dienste Docker und Kubelet
- systemctl docker starten && systemctl Docker aktivieren
- systemctl start kubelet && systemctl enable kubelet
- systemctl start kubelet && systemctl enable kubelet
https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
Das Flanell-Netzwerk wurde im Kubernetes-Cluster bereitgestellt. Warten Sie einige Zeit und überprüfen Sie dann den Knoten und die Pods von kubernetes mit den folgenden Befehlen.- kubectl get Knoten
- kubectl get pods - alle Namespaces
9. Hinzufügen von Knoten zum ClusterStellen Sie eine Verbindung zum node01-Server her und führen Sie den Befehl kubeadm join aus
- kubeadm join 172.31.7.47:6443 –token at03m9.iinkh5ps9q12sh2i –discovery-token-ca-cert-hash sha256: 3f6c1824796ef1ff3d9427c883bde915d5bc13331d74891d831f29a8c4a
Stellen Sie eine Verbindung zum node02-Server her und führen Sie den Befehl kubeadm join aus
- kubeadm join 172.31.7.47:6443 –token at03m9.iinkh5ps9q12sh2i –discovery-token-ca-cert-hash sha256: 3f6c1824796ef1ff3d9427c883bde915d5bc13331d74891d831f29a8c4a
Warten Sie einige Zeit und validieren Sie den Master-Cluster-Server 'k8s-master'. Überprüfen Sie die Knoten und Pods mit dem folgenden Befehl.
- kubectl get Knoten
Jetzt erhalten Sie Arbeiter1 und Arbeiter2 wurde dem Cluster mit dem Status 'Bereit' hinzugefügt.
- kubectl get pods - alle Namespaces
Die Initialisierung und Konfiguration des Kubernetes-Cluster-Masters wurde abgeschlossen.
Schritt 2: Erstellen eines Amazon ES-Clusters
Elasticsearch ist eine Open-Source-Such- und Analyse-Engine, die zur Protokollanalyse und Echtzeitüberwachung von Anwendungen verwendet wird. Amazon Elasticsearch Service (Amazon ES) ist ein AWS-Service, der die Bereitstellung, den Betrieb und die Skalierung von Elasticsearch in der AWS-Cloud ermöglicht. Mit Amazon ES können Sie E-Mail-Sendeereignisse von Ihrem Amazon SES aus analysieren
Wir werden einen Amazon ES-Cluster erstellen und dann den Fluentd-Protokollierungsagenten im Kubernetes-Cluster bereitstellen, der Protokolle sammelt und an den Amazon ES-Cluster sendet
In diesem Abschnitt wird gezeigt, wie Sie mit der Amazon ES-Konsole einen Amazon ES-Cluster erstellen.
So erstellen Sie einen Amazon ES-Cluster
Was ist eine Instanzvariable in Java
- Melden Sie sich bei der AWS Management Console an und öffnen Sie die Amazon Elasticsearch Service-Konsole unter https://console.aws.amazon.com/es/
- Wählen Erstellen Sie eine neue Domäne und wählen Sie Bereitstellungstyp in der Amazon ES-Konsole.
- Übernehmen Sie unter Version den Standardwert des Elasticsearch-Versionsfelds.
- Wählen Sie Weiter
- Geben Sie einen Namen für Ihre Elastic-Suchdomäne in das Feld ein Cluster konfigurieren Seite unter Domain konfigurieren.
- Wählen Sie auf der Seite Cluster konfigurieren unter Dateninstanzen die folgenden Optionen aus
- Instanztyp - Wählen Sie t2.micro.elasticsearch (Free Tier berechtigt).
- Anzahl der Instanzen - ein
- UnterDedizierte Master-Instanzen
- Aktivieren Sie den dedizierten Master - Aktivieren Sie diese Option nicht.
- Aktivieren Sie die Zonenerkennung - Aktivieren Sie diese Option nicht.
- Wählen Sie unter Speicherkonfiguration die folgenden Optionen aus.
- Speichertyp - Wählen Sie EBS. Wählen Sie für die EBS-Einstellungen den EBS-Volume-Typ für allgemeine Zwecke (SSD) und die EBS-Volume-Größe& thinspvon 10.
- Unter Verschlüsselung - Aktivieren Sie diese Option nicht
- Unter Snapshot-Konfiguration
- Automatisierte Startstunde für Schnappschüsse - Wählen Sie Automatische Schnappschüsse Startstunde 00:00 UTC (Standard).
- Wählen Sie Weiter
- Wählen Sie unter Netzwerkkonfiguration die Option VPC-Zugriff aus und wählen Sie Details gemäß Ihrer VPC aus.Unter Kibana-Authentifizierung: - Aktivieren Sie diese Option nicht.
- Um die Zugriffsrichtlinie festzulegen, wählen Sie Offener Zugriff auf die Domäne zulassen.Hinweis: - In der Produktion sollten Sie den Zugriff auf bestimmte IP-Adressen oder Bereiche beschränken.
- Wählen Sie Weiter.
- Überprüfen Sie auf der Seite Überprüfen Ihre Einstellungen und wählen Sie dann Bestätigen und Erstellen.
Hinweis: Die Bereitstellung des Clusters dauert bis zu zehn Minuten. Notieren Sie sich Ihre Kibana-URL, sobald Sie auf die erstellte elastische Suchdomäne klicken.
Schritt 3: Stellen Sie den Fluentd-Protokollierungsagenten im Kubernetes-Cluster bereit
Fluentd ist ein Open-Source-Datensammler, mit dem Sie die Datenerfassung und den Datenverbrauch vereinheitlichen können, um Daten besser nutzen und verstehen zu können. In diesem Fall stellen wir die Fluentd-Protokollierung im Kubernetes-Cluster bereit, der die Protokolldateien sammelt und an die Amazon Elastic Search sendet.
Wir werden eine ClusterRole erstellen, die Berechtigungen für Pods und Namespace-Objekte bereitstellt, um Anforderungen für das Abrufen, Auflisten und Überwachen von Clustern zu stellen.
Zunächst müssen wir die RBAC-Berechtigungen (rollenbasierte Zugriffssteuerung) konfigurieren, damit Fluentd auf die entsprechenden Komponenten zugreifen kann.
1.fluentd-rbac.yaml:
apiVersion: v1 Art: ServiceAccount-Metadaten: Name: fließender Namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1beta1 Art: ClusterRole-Metadaten: Name: fließender Namespace: kube-System Regeln: - apiGroups: - ' 'Ressourcen: - pods - Namespaces Verben: - get - list - watch --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1beta1 Metadaten: name: fluentd roleRef: kind: ClusterRole name: fluentd apiGroup: rbac.authorization .k8s.io Themen: - Art: ServiceAccount Name: fließend Namespace: kube-System
Erstellen: $ kubectl create -f kubernetes / fluentd-rbac.yaml
Jetzt können wir das DaemonSet erstellen.
2. fluentd-daemonset.yaml
apiVersion: extensions / v1beta1 Art: DaemonSet-Metadaten: Name: Fluentd-Namespace: Kubesystem-Labels: k8s-App: Fluentd-Protokollierungsversion: v1 kubernetes.io/cluster-service: 'true' Spezifikation: Vorlage: Metadaten: Labels: k8s -app: fluentd-logging version: v1 kubernetes.io/cluster-service: 'true' spec: serviceAccount: fluentd serviceAccountName: fluentd tolerations: - key: node-role.kubernetes.io/master effect: NoSchedule container: - name: fließendes Bild: fließend / fließend-kubernetes-daemonset: v1.3-debian-elasticsearch env: - Name: FLUENT_ELASTICSEARCH_HOST Wert: 'elasticsearch.logging' - Name: FLUENT_ELASTICSEARCH_PORT Wert: '9200' - Name: FLUENT_ELASTICSEAR Name: FLUENT_UID Wert: '0' Ressourcen: Grenzwerte: Speicher: 200Mi Anforderungen: CPU: 100M Speicher: 200Mi VolumeMounts: - Name: varlog mountPath: / var / log - Name: varlibdockercontainer mountPath: / var / lib / docker / container readOnly : true terminierungGracePeriodSeconds: 30 Volumes: - Name: varlog hostPath: Pfad: / var / log - Name: varlibdockercontainers hostPath: Pfad: / var / lib / docker / container
Stellen Sie sicher, dass Sie FLUENT_ELASTICSEARCH_HOST & FLUENT_ELASTICSEARCH_PORT entsprechend Ihrer elastischen Suchumgebung definieren
wie man einen Pfad in Java einstellt
Bereitstellen:
$ kubectl create -f kubernetes / fluentd-daemonset.yaml
Überprüfen Sie die Protokolle
$ kubectl protokolliert fluentd-lwbt6 -n kube-system | grep Verbindung
Sie sollten sehen, dass Fluentd in den Protokollen eine Verbindung zu Elasticsearch herstellt:
Schritt 4: Visualisieren Sie Kubernetes-Daten in Kibana
- Stellen Sie eine Verbindung zur Kibana-Dashboard-URL her, um von der Amazon ES-Konsole zu gelangen
- Um die von Fluentd in Kibana gesammelten Protokolle anzuzeigen, klicken Sie auf 'Verwaltung' und wählen Sie dann 'Indexmuster' unter 'Kibana' aus.
- Wählen Sie das Standard-Indexmuster (logstash- *).
- Klicken Sie auf Nächster Schritt, legen Sie den Namen des Zeitfilterfelds (@timestamp) fest und wählen Sie Indexmuster erstellen
- Klicken Sie auf Erkennen, um Ihre Anwendungsprotokolle anzuzeigen
- Klicken Sie auf Visualisieren und wählen Sie Visualisierung erstellen und dann Kreis. Füllen Sie die folgenden Felder wie unten gezeigt aus.
- Wählen Sie Logstash- * Index und klicken Sie auf Split Slices
- Aggregation - Wichtige Begriffe
- Feld = Kubernetes.pod_name.keyword
- Größe 10
7. Und Änderungen übernehmen
Das ist es! So können Sie den in Kibana erstellten Kubernetes Pod visualisieren.
Zusammenfassung ::
Die Überwachung durch Protokollanalyse ist eine wichtige Komponente jeder Anwendungsbereitstellung. Sie können Protokolle in Ihrem Cluster in Kubernetes sammeln und konsolidieren, um den gesamten Cluster von einem einzigen Dashboard aus zu überwachen. In unserem Beispiel haben wir gesehen, dass Fluentd als Vermittler zwischen Kubernetes Cluster und Amazon ES fungiert. Fluentd kombiniert die Erfassung und Aggregation von Protokollen und sendet Protokolle zur Protokollanalyse und Datenvisualisierung mit kibana an Amazon ES.
Das obige Beispiel zeigt, wie Sie AWS Elastic Search Logging und Kibana Monitoring mithilfe von Fluentd zum Kubernetes-Cluster hinzufügen.
Wenn Sie diesen Kubernetes-Blog für relevant befunden haben, lesen Sie die von Edureka, einem vertrauenswürdigen Online-Lernunternehmen mit einem Netzwerk von mehr als 250.000 zufriedenen Lernenden auf der ganzen Welt.
Hast du eine Frage an uns? Bitte erwähnen Sie es in den Kommentaren und wir werden uns bei Ihnen melden.