
Apache Flink ist eine Open Source-Plattform für die Verarbeitung verteilter Streams und Batch-Daten. Es kann unter Windows, Mac OS und Linux ausgeführt werden. In diesem Blog-Beitrag wird erläutert, wie Sie den Flink-Cluster lokal einrichten. Es ähnelt Spark in vielerlei Hinsicht - es verfügt über APIs für die Verarbeitung von Grafiken und maschinellem Lernen wie Apache Spark - aber Apache Flink und Apache Spark sind nicht genau gleich.
Um den Flink-Cluster einzurichten, muss Java 7.x oder höher auf Ihrem System installiert sein. Da ich Hadoop-2.2.0 an meinem Ende unter CentOS (Linux) installiert habe, habe ich das Flink-Paket heruntergeladen, das mit Hadoop 2.x kompatibel ist. Führen Sie den folgenden Befehl aus, um das Flink-Paket herunterzuladen.
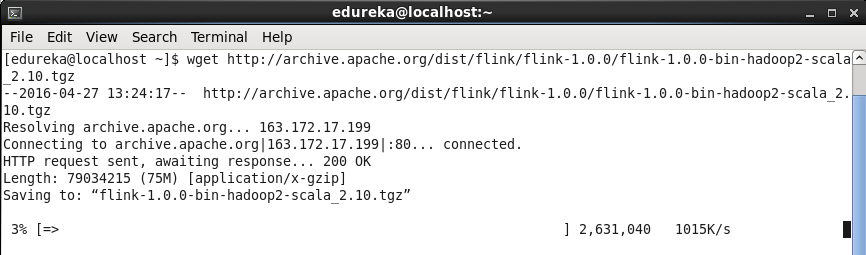
Befehl: wget http://archive.apache.org/dist/flink/flink-1.0.0/flink-1.0.0-bin-hadoop2-scala_2.10.tgz
Entpacken Sie die Datei, um das Flink-Verzeichnis abzurufen.
Befehl: tar -xvf Downloads / flink-1.0.0-bin-hadoop2-scala_2.10.tgz
Befehl: ls
Fügen Sie Flink-Umgebungsvariablen in die .bashrc-Datei ein.
Befehl: sudo gedit .bashrc
Sie müssen den folgenden Befehl ausführen, damit die Änderungen in der .bashrc-Datei aktiviert werden
Befehl: Quelle .bashrc
Gehen Sie nun zum Flink-Verzeichnis und starten Sie den Cluster lokal.
Befehl: cd heftig-1.0.0
Befehl: bin / start-local.sh
Sobald Sie den Cluster gestartet haben, wird ein neuer Daemon JobManager angezeigt.
Befehl: jps
Öffnen Sie den Browser und gehen Sie zu http: // localhost: 8081, um die Web-Benutzeroberfläche von Apache Flink anzuzeigen.
Lassen Sie uns ein einfaches Wordcount-Beispiel mit Apache Flink ausführen.
Bevor Sie das Beispiel ausführen, installieren Sie netcat auf Ihrem System (sudo yum install nc).
Führen Sie nun in einem neuen Terminal den folgenden Befehl aus.
Befehl: nc-lk 9000
Führen Sie den unten angegebenen Befehl im Flink-Terminal aus. Dieser Befehl führt ein Programm aus, das die gestreamten Daten als Eingabe verwendet und eine Wortzähloperation für diese gestreamten Daten ausführt.
Befehl: Beispiele für bin / flink-Ausführungen / Streaming / SocketTextStreamWordCount.jar –Hostname localhost –port 9000
In der Web-Benutzeroberfläche können Sie einen Job im laufenden Zustand sehen.
c ++ Sortierarray in aufsteigender Reihenfolge
Führen Sie den folgenden Befehl in einem neuen Terminal aus. Dadurch werden die gestreamten und verarbeiteten Daten gedruckt.
Befehl: tail -f log / flink - * - jobmanager - *. out
Gehen Sie nun zu dem Terminal, an dem Sie netcat gestartet haben, und geben Sie etwas ein.
Sobald Sie die Eingabetaste für Ihr Keyword drücken, nachdem Sie einige Daten auf dem Netcat-Terminal eingegeben haben, wird die Wortzählung auf diese Daten angewendet und die Ausgabe wird innerhalb von Millisekunden hier gedruckt (Jobmanager-Protokoll von flink).
Innerhalb kürzester Zeit werden Daten gestreamt, verarbeitet und gedruckt.
Es gibt noch viel mehr über Apache Flink zu lernen. Wir werden in unserem kommenden Blog auf andere Flink-Themen eingehen.
Hast du eine Frage an uns? Erwähnen Sie sie im Kommentarbereich und wir werden uns bei Ihnen melden.
Zusammenhängende Posts:
Apache Falcon: Neue Datenverwaltungsplattform für das Hadoop-Ökosystem