
Apache Drill ist die erste schemafreie SQL Engine der Branche. Drill ist nicht die weltweit erste Abfrage-Engine, aber die erste, die ein ausgewogenes Verhältnis zwischen Flexibilität und Geschwindigkeit schafft. Drill ist so konzipiert, dass es auf mehrere Tausend Knoten skaliert und Petabyte an Daten mit interaktiven Geschwindigkeiten abfragt, die für BI / Analytics-Umgebungen erforderlich sind.
Es kann in verschiedene Datenquellen wie Hive, HBase, MongoDB, Dateisystem und RDBMS integriert werden. Auch Eingabeformate wie Avro-, CSV-, TSV-, PSV-, Parkett-, Hadoop-Sequenzdateien und viele andere können problemlos in Drill verwendet werden.
Warum Apache Drill?
Der größte Vorteil von Apache Drill besteht darin, dass es das Schema im laufenden Betrieb erkennen kann, wenn Sie Daten abfragen. Darüber hinaus kann es mit Ihren BI-Tools wie Tableau, Qlikview, MicroStrategy usw. für eine bessere Analyse zusammenarbeiten.
Hier ist ein Zitat eines Branchenanalysten, das den Wert von Apache Drill zusammenfasst:
'Bei Drill geht es nicht nur um SQL-on-Hadoop. Es geht um SQL-on-so ziemlich alles, sofort und ohne Formalität. '
- Andrew Burst, Gigaom Research, Januar 2015
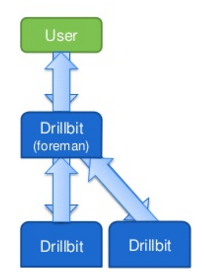
Drillbit ist der Daemon von Apache Drill, der auf jedem Knoten im Cluster ausgeführt wird. Es verwendet ZooKeeper für die gesamte Kommunikation in der Cluster- und Wartungscluster-Mitgliedschaft. Es ist dafür verantwortlich, Anforderungen vom Client anzunehmen, die Abfragen zu verarbeiten und Ergebnisse an den Client zurückzugeben. Der Drillbit, der die Anfrage vom Kunden erhält, wird als „Vorarbeiter“ bezeichnet. Es generiert den Ausführungsplan, die Ausführungsfragmente werden an andere Drillbits gesendet, die im Cluster ausgeführt werden.
Ein weiterer Vorteil ist, dass die Installation und Einrichtung des Bohrers ziemlich einfach ist. Lassen Sie uns lernen, wie Sie Apache Drill installieren.
Der erste Schritt ist das Herunterladen des Bohrpakets.
So konfigurieren Sie Eclipse für Java
Befehl: wget https://archive.apache.org/dist/drill/drill-1.5.0/apache-drill-1.5.0.tar.gz
Befehl: tar -xvf Apache-Drill-1.5.0.tar.gz
Befehl: ls
Legen Sie als Nächstes die Umgebungsvariablen in der .bashrc-Datei fest.
Befehl: sudo gedit .bashrc
export DRILL_HOME = / home / edureka / apache-burn-1.5.0
export PATH = $ PATH: /home/edureka/apache-drill-1.5.0/bin
Dieser Befehl aktualisiert die Änderungen:
Befehl: Quelle .bashrc
Gehen Sie nun zum Drill-Conf-Verzeichnis und bearbeiten Sie die Drill-override.conf-Datei mit der Cluster-ID und dem Zookeeper-Host und -Port. Wir werden sie auf einem lokalen Cluster ausführen.
Befehl: CD Apache-Drill-1.5.0
Befehl: sudo gedit conf / burn-override.conf
Standardmäßig beträgt DRILL_MAX_DIRECT_MEMORY in Drill-env.sh 8 GB, und wir müssen es entsprechend dem vorhandenen Speicher aufbewahren.
Befehl: sudo gedit conf / burn-env.sh
Um Drill nur auf einem einzelnen Knoten zu installieren, können Sie den eingebetteten Modus verwenden, in dem er lokal ausgeführt wird. Der Drillbit-Dienst wird automatisch gestartet, wenn Sie diesen Befehl ausführen.
Befehl: ./bin/drill-embedded
Sie können eine einfache Abfrage ausführen, um die Installation zu überprüfen.
Befehl: Wählen Sie * aus sys.options WHERE type = 'SYSTEM' und nennen Sie 'security%'.
Um die Webkonsole von Apache Drill zu überprüfen, müssen Sie im Webbrowser zu localhost: 8047 gehen.
Sie können Ihre Abfrage auch auf der Registerkarte Abfrage ausführen.
Um Drill im verteilten Modus auszuführen, müssen Sie die Cluster-ID bearbeiten und ZooKeeper-Informationen in der Drill-override.conf wie folgt hinzufügen.
Dann müssen wir den ZooKeeper-Dienst auf jedem Knoten starten. Danach müssen Sie mit diesem Befehl den Drillbit-Dienst auf jedem Knoten starten.
Was ist eine Methode Javascript
Befehl: ./bin/drillbit.sh starten
Befehl: jps
Jetzt verwenden wir den folgenden Befehl, um die Bohrschale zu starten.
Jetzt können wir unsere Abfragen im Cluster im verteilten Modus ausführen.
Dies ist der erste Blog-Beitrag in einer zweiteiligen Apache Drill-Blogserie. Der zweite Blog der Reihe kommt bald.
Hast du eine Frage an uns? Erwähnen Sie sie im Kommentarbereich und wir werden uns bei Ihnen melden.
Zusammenhängende Posts: