
Ich werde diesen Apache Spark vs Hadoop-Blog starten, indem ich zuerst Hadoop und Spark vorstelle, um den richtigen Kontext für beide Frameworks festzulegen. Anschließend werden wir beide Big-Data-Frameworks anhand verschiedener Parameter vergleichen, um ihre Stärken und Schwächen zu analysieren.Unabhängig vom Ergebnis unseres Vergleichs sollten Sie jedoch wissen, dass sowohl Spark als auch Hadoop entscheidende Bestandteile des .
Apache Spark vs Hadoop: Einführung in Hadoop
Hadoop ist ein Framework, mit dem Sie Big Data zunächst in einer verteilten Umgebung speichern können, damit Sie es parallel verarbeiten können. Grundsätzlich gibt es in Hadoop zwei Komponenten:
HDFS
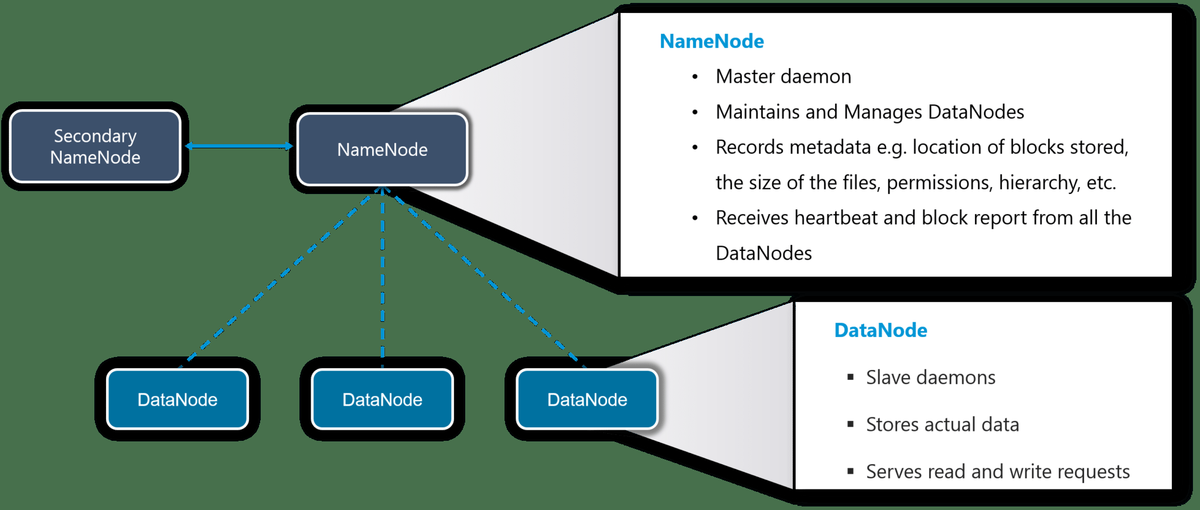
HDFS erstellt eine Abstraktion von Ressourcen. Lassen Sie mich dies für Sie vereinfachen. Ähnlich wie bei der Virtualisierung können Sie HDFS logisch als eine Einheit zum Speichern von Big Data sehen, aber tatsächlich speichern Sie Ihre Daten auf mehreren Knoten verteilt. Hier haben Sie Master-Slave-Architektur. In HDFS ist Namenode ein Masterknoten und Datanodes sind Slaves.
NameNode
Es ist der Master-Daemon, der die DataNodes (Slave-Knoten) verwaltet und verwaltet. Es zeichnet die Metadaten aller im Cluster gespeicherten Dateien auf, z. Speicherort der gespeicherten Blöcke, Größe der Dateien, Berechtigungen, Hierarchie usw. Es werden alle Änderungen an den Metadaten des Dateisystems aufgezeichnet.
Wenn beispielsweise eine Datei in HDFS gelöscht wird, zeichnet der NameNode dies sofort im EditLog auf. Es erhält regelmäßig einen Heartbeat- und einen Blockbericht von allen DataNodes im Cluster, um sicherzustellen, dass die DataNodes aktiv sind. Es zeichnet alle Blöcke in HDFS auf und in welchen Knoten diese Blöcke gespeichert sind.
DataNode
Dies sind Slave-Daemons, die auf jeder Slave-Maschine ausgeführt werden. Die tatsächlichen Daten werden auf DataNodes gespeichert. Sie sind für die Bearbeitung von Lese- und Schreibanforderungen der Kunden verantwortlich. Sie sind auch dafür verantwortlich, Blöcke zu erstellen, Blöcke zu löschen und diese basierend auf den vom NameNode getroffenen Entscheidungen zu replizieren.
 GARN
GARN
YARN führt alle Ihre Verarbeitungsaktivitäten aus, indem es Ressourcen zuweist und Aufgaben plant. Es hat zwei Hauptdämonen, d.h. Ressourcenmanager und NodeManager .
Ressourcenmanager
Es ist eine Komponente auf Clusterebene (eine für jeden Cluster) und wird auf dem Master-Computer ausgeführt. Es verwaltet Ressourcen und plant Anwendungen, die auf YARN ausgeführt werden.
NodeManager
Es ist eine Komponente auf Knotenebene (eine auf jedem Knoten) und wird auf jedem Slave-Computer ausgeführt. Es ist für die Verwaltung der Container und die Überwachung der Ressourcennutzung in jedem Container verantwortlich. Es verfolgt auch den Knotenzustand und die Protokollverwaltung. Es kommuniziert kontinuierlich mit ResourceManager, um auf dem neuesten Stand zu bleiben. Sie können also mit MapReduce eine parallele Verarbeitung auf HDFS durchführen.
Um mehr über Hadoop zu erfahren, können Sie dies durchgehen Blog. Nachdem wir alle mit der Einführung von Hadoop fertig sind, fahren wir mit der Einführung von Spark fort.
Apache Spark vs Hadoop: Einführung in Apache Spark
Apache Spark ist ein Framework für die Echtzeit-Datenanalyse in einer verteilten Computerumgebung. Es führt speicherinterne Berechnungen durch, um die Geschwindigkeit der Datenverarbeitung zu erhöhen. Es ist schneller für die Verarbeitung großer Datenmengen, da es speicherinterne Berechnungen und andere Optimierungen ausnutzt. Daher erfordert es eine hohe Verarbeitungsleistung.
Resilient Distributed Dataset (RDD) ist eine grundlegende Datenstruktur von Spark. Es ist eine unveränderliche verteilte Sammlung von Objekten. Jeder Datensatz in RDD ist in logische Partitionen unterteilt, die auf verschiedenen Knoten des Clusters berechnet werden können. RDDs können alle Arten von Python-, Java- oder Scala-Objekten enthalten, einschließlich benutzerdefinierter Klassen. Funkenkomponenten machen es schnell und zuverlässig. Apache Spark besteht aus folgenden Komponenten:
Übertragen Sie Dateien auf die ec2 Windows-Instanz
- Funkenkern - Spark Core ist die Basis-Engine für die parallele und verteilte Datenverarbeitung in großem Maßstab. Darüber hinaus ermöglichen zusätzliche Bibliotheken, die auf dem Kern erstellt werden, unterschiedliche Workloads für Streaming, SQL und maschinelles Lernen. Es ist verantwortlich für die Speicherverwaltung und Fehlerbehebung, das Planen, Verteilen und Überwachen von Jobs in einem Cluster und die Interaktion mit Speichersystemen
- Spark Streaming - Spark Streaming ist die Komponente von Spark, mit der Echtzeit-Streaming-Daten verarbeitet werden. Somit ist es eine nützliche Ergänzung zur Kern-Spark-API. Es ermöglicht die Verarbeitung von Live-Datenströmen mit hohem Durchsatz und fehlertoleranten Streams
- Spark SQL : Spark SQL ist ein neues Modul in Spark, das die relationale Verarbeitung in die funktionale Programmier-API von Spark integriert. Es unterstützt das Abfragen von Daten entweder über SQL oder über die Hive Query Language. Für diejenigen unter Ihnen, die mit RDBMS vertraut sind, ist Spark SQL ein einfacher Übergang zu Ihren früheren Tools, mit denen Sie die Grenzen der traditionellen relationalen Datenverarbeitung erweitern können.
- GraphX : GraphX ist die Spark-API für Diagramme und graphparallele Berechnungen. Daher wird das Spark-RDD um ein Resilient Distributed Property Graph erweitert. Auf hoher Ebene erweitert GraphX die Spark-RDD-Abstraktion durch die Einführung des Resilient Distributed Property Graph: eines gerichteten Multigraphen mit Eigenschaften, die an jeden Scheitelpunkt und jede Kante angehängt sind.
- MLlib (Maschinelles Lernen): MLlib steht für Machine Learning Library. Spark MLlib wird verwendet, um maschinelles Lernen in Apache Spark durchzuführen.
Wie Sie sehen können, enthält Spark zahlreiche Bibliotheken auf hoher Ebene, einschließlich Unterstützung für R, SQL, Python, Scala, Java usw. Diese Standardbibliotheken verbessern die nahtlose Integration in komplexe Workflows. Darüber hinaus können verschiedene Dienste wie MLlib, GraphX, SQL + Data Frames, Streaming-Dienste usw. integriert werden, um die Funktionen zu erweitern.
Um mehr über Apache Spark zu erfahren, können Sie dies durchgehen Blog. Jetzt ist der Grundstein für Apache Spark gegen Hadoop gelegt. Vergleichen wir Apache Spark mit Hadoop anhand verschiedener Parameter, um deren Stärken zu verstehen.
Apache Spark vs Hadoop: Zu vergleichende Parameter
Performance
Spark ist schnell, weil es In-Memory-Verarbeitung hat. Es kann auch eine Festplatte für Daten verwenden, die nicht alle in den Speicher passen. Die In-Memory-Verarbeitung von Spark liefert nahezu Echtzeitanalysen. Dies macht Spark für Kreditkartenverarbeitungssysteme, maschinelles Lernen, Sicherheitsanalysen und Internet-of-Things-Sensoren geeignet.
Hadoop wurde ursprünglich so eingerichtet, dass Daten aus mehreren Quellen kontinuierlich erfasst werden, ohne sich Gedanken über die Art der Daten zu machen und diese in einer verteilten Umgebung zu speichern. MapReduce verwendet die Stapelverarbeitung. MapReduce wurde nie für die Echtzeitverarbeitung entwickelt. Die Hauptidee von YARN ist die parallele Verarbeitung über verteilte Datensätze.
Das Problem beim Vergleich der beiden ist, dass sie die Verarbeitung unterschiedlich durchführen.
Benutzerfreundlichkeit
Spark wird mit benutzerfreundlichen APIs für Scala, Java, Python und Spark SQL geliefert. Spark SQL ist SQL sehr ähnlich, sodass SQL-Entwickler es leichter erlernen können. Spark bietet Entwicklern auch eine interaktive Shell, mit der sie andere Aktionen abfragen und ausführen sowie sofortiges Feedback erhalten können.
Sie können Daten in Hadoop einfach aufnehmen, indem Sie entweder eine Shell verwenden oder sie in mehrere Tools wie Sqoop, Flume usw. integrieren. YARN ist nur ein Verarbeitungsframework und kann in mehrere Tools wie Hive und Pig integriert werden. HIVE ist eine Data Warehousing-Komponente, die das Lesen, Schreiben und Verwalten großer Datenmengen in einer verteilten Umgebung mithilfe einer SQL-ähnlichen Schnittstelle durchführt. Sie können dies durchgehen Hadoop-Ökosystem Blog, um mehr über die verschiedenen Tools zu erfahren, die in Hadoop integriert werden können.
Kosten
Hadoop und Spark sind beide Open-Source-Projekte von Apache, daher fallen für die Software keine Kosten an. Die Kosten sind nur mit der Infrastruktur verbunden. Beide Produkte sind so konzipiert, dass sie auf Standardhardware mit niedrigen Gesamtbetriebskosten ausgeführt werden können.
Jetzt fragen Sie sich vielleicht, wie sie sich unterscheiden. Speicher und Verarbeitung in Hadoop sind festplattenbasiert und Hadoop verwendet Standardspeicher. Mit Hadoop benötigen wir also viel Speicherplatz sowie schnellere Festplatten. Für Hadoop sind außerdem mehrere Systeme erforderlich, um die Festplatten-E / A zu verteilen.
Aufgrund der Speicherverarbeitung von Apache Spark wird viel Speicher benötigt, es kann jedoch mit einer Standardgeschwindigkeit und -menge der Festplatte gearbeitet werden. Da Speicherplatz eine relativ kostengünstige Ware ist und Spark keine Festplatten-E / A für die Verarbeitung verwendet, erfordert es stattdessen große Mengen an RAM, um alles im Speicher auszuführen. Somit verursacht das Spark-System mehr Kosten.
Aber ja, eine wichtige Sache, die Sie beachten sollten, ist, dass die Technologie von Spark die Anzahl der erforderlichen Systeme reduziert. Es werden deutlich weniger Systeme benötigt, die mehr kosten. Es wird also einen Punkt geben, an dem Spark die Kosten pro Recheneinheit trotz des zusätzlichen RAM-Bedarfs reduziert.
Was ist br Tag in HTML
Datenverarbeitung
Es gibt zwei Arten der Datenverarbeitung: Stapelverarbeitung und Stream-Verarbeitung.
Stapelverarbeitung vs Stream-Verarbeitung
Stapelverarbeitung : Die Stapelverarbeitung war für die Big-Data-Welt von entscheidender Bedeutung. Im einfachsten Sinne arbeitet die Stapelverarbeitung mit hohen Datenmengen, die über einen bestimmten Zeitraum gesammelt wurden. Bei der Stapelverarbeitung werden zuerst Daten gesammelt und dann zu einem späteren Zeitpunkt verarbeitete Ergebnisse erzeugt.
Die Stapelverarbeitung ist eine effiziente Methode zur Verarbeitung großer statischer Datensätze. Im Allgemeinen führen wir eine Stapelverarbeitung für archivierte Datensätze durch. Zum Beispiel die Berechnung des Durchschnittseinkommens eines Landes oder die Bewertung der Veränderung des E-Commerce im letzten Jahrzehnt.
Stream-Verarbeitung : Stream-Verarbeitung ist der aktuelle Trend in der Big-Data-Welt. Das Gebot der Stunde sind Geschwindigkeits- und Echtzeitinformationen, wie es die Dampfverarbeitung tut. Die Stapelverarbeitung ermöglicht es Unternehmen nicht, schnell auf sich ändernde Geschäftsanforderungen in Echtzeit zu reagieren. Die Stream-Verarbeitung hat einen raschen Anstieg der Nachfrage verzeichnet.
YARN ist ein Framework für die Stapelverarbeitung, das nun zu Apache Spark vs Hadoop zurückkehrt. Wenn wir einen Job an YARN senden, liest er Daten aus dem Cluster, führt die Operation aus und schreibt die Ergebnisse zurück in den Cluster. Dann liest es erneut die aktualisierten Daten, führt die nächste Operation aus und schreibt die Ergebnisse zurück in den Cluster und so weiter.
Spark führt ähnliche Vorgänge aus, verwendet jedoch die In-Memory-Verarbeitung und optimiert die Schritte. Mit GraphX können Benutzer dieselben Daten wie Diagramme und Sammlungen anzeigen. Benutzer können Diagramme auch mit Resilient Distributed Datasets (RDDs) transformieren und verknüpfen.
Fehlertoleranz
Hadoop und Spark bieten beide Fehlertoleranz, haben jedoch unterschiedliche Ansätze. Sowohl für HDFS als auch für YARN prüfen Master-Daemons (d. H. NameNode bzw. ResourceManager) den Herzschlag von Slave-Daemons (d. H. DataNode bzw. NodeManager). Wenn ein Slave-Daemon ausfällt, planen Master-Daemons alle ausstehenden und laufenden Vorgänge auf einen anderen Slave um. Diese Methode ist effektiv, kann jedoch auch die Abschlusszeiten für Vorgänge mit einem einzelnen Fehler erheblich verlängern. Da Hadoop Standardhardware verwendet, besteht eine andere Möglichkeit, wie HDFS die Fehlertoleranz sicherstellt, darin, Daten zu replizieren.
Wie oben erläutert, sind RDDs Bausteine von Apache Spark. RDDs bieten Spark Fehlertoleranz. Sie können auf jeden Datensatz verweisen, der in einem externen Speichersystem wie HDFS, HBase oder einem gemeinsam genutzten Dateisystem vorhanden ist. Sie können parallel betrieben werden.
RDDs können ein Dataset über mehrere Vorgänge hinweg im Speicher beibehalten, wodurch zukünftige Aktionen zehnmal schneller werden. Wenn eine RDD verloren geht, wird sie automatisch unter Verwendung der ursprünglichen Transformationen neu berechnet. So bietet Spark Fehlertoleranz.
Sicherheit
Hadoop unterstützt Kerberos für die Authentifizierung, ist jedoch schwierig zu handhaben. Es werden jedoch auch Drittanbieter wie LDAP (Lightweight Directory Access Protocol) für die Authentifizierung unterstützt. Sie bieten auch Verschlüsselung. HDFS unterstützt herkömmliche Dateiberechtigungen sowie Zugriffssteuerungslisten (ACLs). Hadoop bietet eine Service Level-Autorisierung, die garantiert, dass Kunden über die richtigen Berechtigungen für die Auftragsübermittlung verfügen.
Spark unterstützt derzeit die Authentifizierung über ein gemeinsames Geheimnis. Spark kann in HDFS integriert werden und HDFS-ACLs und Berechtigungen auf Dateiebene verwenden. Spark kann auch auf YARN ausgeführt werden, wobei die Funktionen von Kerberos genutzt werden.
Anwendungsfälle, in denen Hadoop am besten passt:
- Archivdaten analysieren. YARN ermöglicht die parallele Verarbeitung großer Datenmengen. Teile von Daten werden parallel und separat auf verschiedenen DataNodes verarbeitet und sammeln Ergebnisse von jedem NodeManager.
- Wenn keine sofortigen Ergebnisse erforderlich sind. Hadoop MapReduce ist eine gute und wirtschaftliche Lösung für die Stapelverarbeitung.
Anwendungsfälle, in denen Spark am besten passt:
Echtzeit-Big-Data-Analyse:
Echtzeit-Datenanalyse bedeutet, dass Daten verarbeitet werden, die von den Echtzeit-Ereignisströmen generiert werden, die mit einer Rate von Millionen von Ereignissen pro Sekunde eingehen, beispielsweise Twitter-Daten. Die Stärke von Spark liegt in seiner Fähigkeit, das Streaming von Daten zusammen mit der verteilten Verarbeitung zu unterstützen. Dies ist eine nützliche Kombination, die eine nahezu zeitnahe Verarbeitung von Daten ermöglicht. MapReduce ist von einem solchen Vorteil betroffen, da es für die stapelweise verteilte Verarbeitung großer Datenmengen ausgelegt ist. Echtzeitdaten können weiterhin auf MapReduce verarbeitet werden, ihre Geschwindigkeit entspricht jedoch nicht annähernd der von Spark.
Ausnahmebehandlung in Oracle gespeicherter Prozedur
Spark behauptet, Daten 100-mal schneller als MapReduce zu verarbeiten, während sie mit den Festplatten 10-mal schneller sind.
Grafikverarbeitung:
Die meisten Grafikverarbeitungsalgorithmen wie der Seitenrang führen mehrere Iterationen über dieselben Daten durch, und dies erfordert einen Mechanismus zur Nachrichtenübermittlung. Wir müssen MapReduce explizit programmieren, um solche mehreren Iterationen über dieselben Daten zu verarbeiten. Das funktioniert ungefähr so: Lesen Sie Daten von der Festplatte und schreiben Sie nach einer bestimmten Iteration Ergebnisse in das HDFS und lesen Sie dann Daten aus dem HDFS für die nächste Iteration. Dies ist sehr ineffizient, da Daten gelesen und auf die Festplatte geschrieben werden müssen, was aus Gründen der Fehlertoleranz umfangreiche E / A-Vorgänge und Datenreplikationen im gesamten Cluster erfordert. Außerdem weist jede MapReduce-Iteration eine sehr hohe Latenz auf, und die nächste Iteration kann erst beginnen, nachdem der vorherige Job vollständig abgeschlossen wurde.
Außerdem erfordert das Weiterleiten von Nachrichten Punktzahlen benachbarter Knoten, um die Punktzahl eines bestimmten Knotens zu bewerten. Diese Berechnungen erfordern Nachrichten von seinen Nachbarn (oder Daten über mehrere Phasen des Jobs), ein Mechanismus, der MapReduce fehlt. Verschiedene Grafikverarbeitungswerkzeuge wie Pregel und GraphLab wurden entwickelt, um der Notwendigkeit einer effizienten Plattform für Grafikverarbeitungsalgorithmen gerecht zu werden. Diese Tools sind schnell und skalierbar, aber für die Erstellung und Nachbearbeitung dieser komplexen mehrstufigen Algorithmen nicht effizient.
Die Einführung von Apache Spark löste diese Probleme weitgehend. Spark enthält eine Graph-Berechnungsbibliothek namens GraphX, die unser Leben vereinfacht. Die In-Memory-Berechnung und die integrierte Grafikunterstützung verbessern die Leistung des Algorithmus gegenüber herkömmlichen MapReduce-Programmen um ein oder zwei Grad. Spark verwendet eine Kombination aus Netty und Akka, um Nachrichten an die Ausführenden zu verteilen. Schauen wir uns einige Statistiken an, die die Leistung des PageRank-Algorithmus mit Hadoop und Spark darstellen.
Iterative Algorithmen für maschinelles Lernen:
Fast alle Algorithmen für maschinelles Lernen arbeiten iterativ. Wie wir bereits gesehen haben, beinhalten iterative Algorithmen E / A-Engpässe in den MapReduce-Implementierungen. MapReduce verwendet grobkörnige Aufgaben (Parallelität auf Aufgabenebene), die für iterative Algorithmen zu schwer sind. Spark mit Hilfe von Mesos - einem verteilten Systemkernel, speichert das Zwischendatensatz nach jeder Iteration zwischen und führt mehrere Iterationen für dieses zwischengespeicherte Dataset aus, wodurch die E / A reduziert und der Algorithmus fehlertolerant schneller ausgeführt wird.
Spark verfügt über eine integrierte skalierbare Bibliothek für maschinelles Lernen namens MLlib, die hochwertige Algorithmen enthält, die Iterationen nutzen und bessere Ergebnisse liefern als Annäherungen an einen Durchgang, die manchmal in MapReduce verwendet werden.
- Schnelle Datenverarbeitung. Wie wir wissen, ermöglicht Spark die In-Memory-Verarbeitung. Infolgedessen ist Spark für Daten im RAM bis zu 100-mal schneller und für Daten im Speicher bis zu 10-mal schneller.
- Iterative Verarbeitung. Mit den RDDs von Spark können mehrere Kartenoperationen im Speicher ausgeführt werden, ohne dass zwischenzeitliche Datensätze auf eine Festplatte geschrieben werden müssen.
- Nahezu Echtzeitverarbeitung. Spark ist ein hervorragendes Tool, um sofortige Geschäftsinformationen bereitzustellen. Dies ist der Grund, warum Spark im Streaming-System Ihrer Kreditkarte verwendet wird.
'Apache Spark: Ein Mörder oder Retter von Apache Hadoop?'
Die Antwort darauf - Hadoop MapReduce und Apache Spark konkurrieren nicht miteinander. Tatsächlich ergänzen sie sich recht gut. Hadoop bringt riesige Datensätze unter Kontrolle von Warensystemen. Spark bietet speicherinterne Echtzeitverarbeitung für die Datensätze, die dies erfordern. Wenn wir die Fähigkeit von Apache Spark, d. H. Hohe Verarbeitungsgeschwindigkeit, erweiterte Analyse und Unterstützung für mehrere Integrationen, mit Hadoops kostengünstigem Betrieb auf Standardhardware kombinieren, erzielen wir die besten Ergebnisse. Hadoop ergänzt die Apache Spark-Funktionen. Spark kann Hadoop nicht vollständig ersetzen, aber die gute Nachricht ist, dass die Nachfrage nach Spark derzeit auf einem Allzeithoch ist! Dies ist der richtige Zeitpunkt, um Spark zu meistern und die Karrieremöglichkeiten zu nutzen, die sich Ihnen bieten. Jetzt loslegen!
Hast du eine Frage an uns? Bitte erwähnen Sie es in den Kommentaren und wir werden uns frühestens bei Ihnen melden.
Wenn Sie Spark lernen und eine Karriere in der Spark-Domäne aufbauen möchten, um eine umfassende Datenverarbeitung mit RDD, Spark-Streaming, SparkSQL, MLlib, GraphX und Scala mit realen Anwendungsfällen durchzuführen, besuchen Sie unser interaktives Live-Online Hier, Dazu gehört eine 24 * 7-Unterstützung, die Sie während Ihrer gesamten Lernphase begleitet.