
Als die Welt in die Ära der Big Data eintrat, wuchs auch der Bedarf an Speicher. Bis 2010 war dies die größte Herausforderung und Sorge für die Unternehmensbranche. Der Schwerpunkt lag auf dem Aufbau eines Frameworks und von Lösungen zum Speichern von Daten. Nachdem Hadoop und andere Frameworks das Speicherproblem erfolgreich gelöst haben, hat sich der Fokus auf die Verarbeitung dieser Daten verlagert. Data Science ist hier die geheime Sauce. Alle Ideen, die Sie in Hollywood-Science-Fiction-Filmen sehen, können von Data Science tatsächlich in die Realität umgesetzt werden. Data Science ist die Zukunft der künstlichen Intelligenz. Daher ist es sehr wichtig zu verstehen, was Data Science ist und wie es Ihrem Unternehmen einen Mehrwert verleihen kann.
Der Edureka 2019 Tech Career Guide ist da! Die heißesten Jobrollen, präzisen Lernpfade, Branchenaussichten und mehr im Leitfaden. Herunterladen jetzt.In diesem Blog werde ich die folgenden Themen behandeln.
- Was ist Data Science?
- Warum Data Science?
- Wer ist ein Data Scientist?
- Wie unterscheidet es sich von Business Intelligence (BI) und Data Science?
- Der Lebenszyklus von Data Science mithilfe eines Anwendungsfalls
Am Ende dieses Blogs werden Sie verstehen, was Data Science ist und welche Rolle es dabei spielt, aus den komplexen und großen Datenmengen um uns herum aussagekräftige Erkenntnisse zu gewinnen.Um detaillierte Informationen zu Data Science zu erhalten, können Sie sich live anmelden von Edureka mit 24/7 Support und lebenslangem Zugriff.
Was ist Data Science?
Data Science ist eine Mischung aus verschiedenen Werkzeugen, Algorithmen und Prinzipien des maschinellen Lernens mit dem Ziel, verborgene Muster aus den Rohdaten zu entdecken. Aber wie unterscheidet sich das von dem, was Statistiker seit Jahren tun?
Die Antwort liegt im Unterschied zwischen Erklären und Vorhersagen.
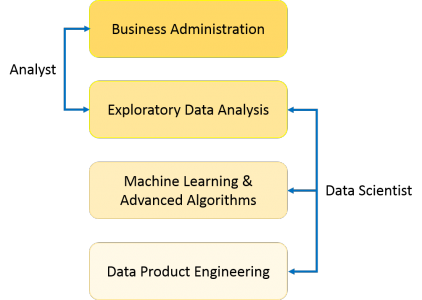
Wie Sie dem obigen Bild entnehmen können, handelt es sich um einen DatenanalystenErklärt normalerweise, was los ist, indem der Verlauf der Daten verarbeitet wird. Auf der anderen Seite führt Data Scientist nicht nur die explorative Analyse durch, um daraus Erkenntnisse zu gewinnen, sondern verwendet auch verschiedene fortschrittliche Algorithmen für maschinelles Lernen, um das Auftreten eines bestimmten Ereignisses in der Zukunft zu identifizieren. Ein Datenwissenschaftler betrachtet die Daten aus vielen Winkeln, manchmal aus Winkeln, die zuvor nicht bekannt waren.
wie man den Pfad für Java festlegt
Daher wird Data Science hauptsächlich verwendet, um Entscheidungen und Vorhersagen zu treffen, wobei prädiktive Kausalanalysen, präskriptive Analysen (Predictive Plus Decision Science) und maschinelles Lernen verwendet werden.
- Predictive Causal Analytics - Wenn Sie ein Modell wünschen, das die Möglichkeiten eines bestimmten Ereignisses in der Zukunft vorhersagen kann, müssen Sie prädiktive Kausalanalysen anwenden. Wenn Sie beispielsweise Geld auf Kredit bereitstellen, ist die Wahrscheinlichkeit, dass Kunden künftige Kreditzahlungen pünktlich leisten, ein Problem für Sie. Hier können Sie ein Modell erstellen, das Vorhersageanalysen für den Zahlungsverlauf des Kunden durchführen kann, um vorherzusagen, ob die zukünftigen Zahlungen pünktlich sein werden oder nicht.
- Prescriptive Analytics: Wenn Sie ein Modell suchen, das die Intelligenz besitzt, seine eigenen Entscheidungen zu treffen und es mit dynamischen Parametern zu ändern, benötigen Sie auf jeden Fall eine vorgeschriebene Analyse. In diesem relativ neuen Bereich dreht sich alles um Beratung. Mit anderen Worten, es wird nicht nur eine Reihe vorgeschriebener Maßnahmen und damit verbundener Ergebnisse vorhergesagt, sondern auch vorgeschlagen.
Das beste Beispiel dafür ist Googles selbstfahrendes Auto, das ich bereits zuvor besprochen hatte. Die von Fahrzeugen gesammelten Daten können zum Trainieren selbstfahrender Autos verwendet werden. Sie können Algorithmen für diese Daten ausführen, um Informationen zu liefern. Auf diese Weise kann Ihr Auto entscheiden, wann und welchen Weg es einschlagen soll,wann zu verlangsamen oder zu beschleunigen.
- Maschinelles Lernen zur Vorhersage - Wenn Sie Transaktionsdaten eines Finanzunternehmens haben und ein Modell erstellen müssen, um den zukünftigen Trend zu bestimmen, sind Algorithmen für maschinelles Lernen die beste Wahl. Dies fällt unter das Paradigma des überwachten Lernens. Es wird als überwacht bezeichnet, da Sie bereits über die Daten verfügen, anhand derer Sie Ihre Maschinen trainieren können. Beispielsweise kann ein Betrugserkennungsmodell anhand einer historischen Aufzeichnung betrügerischer Einkäufe trainiert werden.
- Maschinelles Lernen zur Mustererkennung - Wenn Sie nicht über die Parameter verfügen, anhand derer Sie Vorhersagen treffen können, müssen Sie die verborgenen Muster im Datensatz herausfinden, um aussagekräftige Vorhersagen treffen zu können. Dies ist nichts anderes als das unbeaufsichtigte Modell, da Sie keine vordefinierten Beschriftungen für die Gruppierung haben. Der am häufigsten für die Mustererkennung verwendete Algorithmus ist das Clustering.
Angenommen, Sie arbeiten in einer Telefongesellschaft und müssen ein Netzwerk aufbauen, indem Sie Türme in einer Region errichten. Anschließend können Sie mithilfe der Clustering-Technik die Turmpositionen ermitteln, die sicherstellen, dass alle Benutzer eine optimale Signalstärke erhalten.
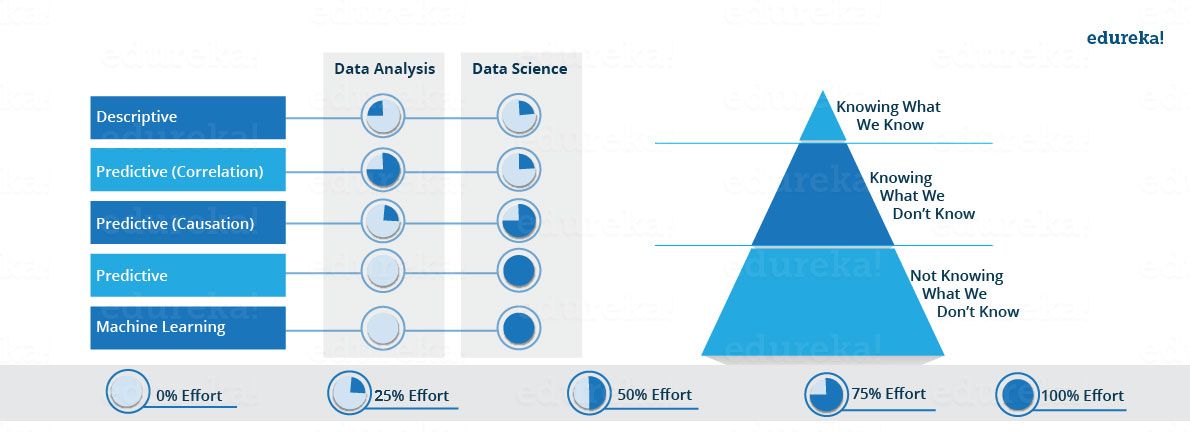
Lassen Sie uns sehen, wie sich der Anteil der oben beschriebenen Ansätze sowohl für die Datenanalyse als auch für die Datenwissenschaft unterscheidet. Wie Sie im Bild unten sehen können, Datenanalyseumfasst bis zu einem gewissen Grad deskriptive Analysen und Vorhersagen. Auf der anderen Seite geht es in Data Science mehr um Predictive Causal Analytics und maschinelles Lernen.
Nachdem Sie nun genau wissen, was Data Science ist, sollten Sie herausfinden, warum es überhaupt benötigt wurde.
Warum Data Science?
- Traditionell waren die Daten, die wir hatten, größtenteils strukturiert und klein, was mit einfachen BI-Tools analysiert werden konnte.Im Gegensatz zu Daten in dertraditionelle Systeme, die meist strukturiert warenHeute sind die meisten Daten unstrukturiert oder halbstrukturiert. Werfen wir einen Blick auf die Datentrends in der Abbildung unten, die zeigen, dass bis 2020 mehr als 80% der Daten unstrukturiert sein werden.

Diese Daten werden aus verschiedenen Quellen wie Finanzprotokollen, Textdateien, Multimedia-Formularen, Sensoren und Instrumenten generiert. Einfache BI-Tools sind nicht in der Lage, dieses riesige Datenvolumen und diese Datenvielfalt zu verarbeiten. Aus diesem Grund benötigen wir komplexere und fortschrittlichere Analysewerkzeuge und -algorithmen, um daraus aussagekräftige Erkenntnisse zu verarbeiten, zu analysieren und zu ziehen.
Dies ist nicht der einzige Grund, warum Data Science so populär geworden ist. Lassen Sie uns genauer untersuchen, wie Data Science in verschiedenen Bereichen eingesetzt wird.
- Wie wäre es, wenn Sie die genauen Anforderungen Ihrer Kunden anhand der vorhandenen Daten wie dem früheren Browserverlauf, dem Kaufverlauf, dem Alter und dem Einkommen des Kunden verstehen könnten. Zweifellos hatten Sie all diese Daten auch früher, aber jetzt, mit der großen Menge und Vielfalt der Daten, können Sie Modelle effektiver trainieren und das Produkt Ihren Kunden präziser empfehlen. Wäre es nicht erstaunlich, wenn es Ihrem Unternehmen mehr Geschäft bringen würde?
- Nehmen wir ein anderes Szenario, um die Rolle von Data Science in zu verstehen Entscheidungen fällen.Wie wäre es, wenn Ihr Auto die Intelligenz hätte, Sie nach Hause zu fahren? Die selbstfahrenden Autos sammeln Live-Daten von Sensoren, einschließlich Radar, Kameras und Lasern, um eine Karte ihrer Umgebung zu erstellen. Basierend auf diesen Daten werden Entscheidungen getroffen, wie wann zu beschleunigen, wann zu beschleunigen, wann zu überholen, wo eine Kurve zu fahren ist - unter Verwendung fortschrittlicher Algorithmen für maschinelles Lernen.
- Lassen Sie uns sehen, wie Data Science in der prädiktiven Analyse verwendet werden kann. Nehmen wir als Beispiel die Wettervorhersage. Daten von Schiffen, Flugzeugen, Radargeräten und Satelliten können gesammelt und analysiert werden, um Modelle zu erstellen. Diese Modelle prognostizieren nicht nur das Wetter, sondern helfen auch bei der Vorhersage des Auftretens von Naturkatastrophen. Es wird Ihnen helfen, im Voraus geeignete Maßnahmen zu ergreifen und viele wertvolle Leben zu retten.
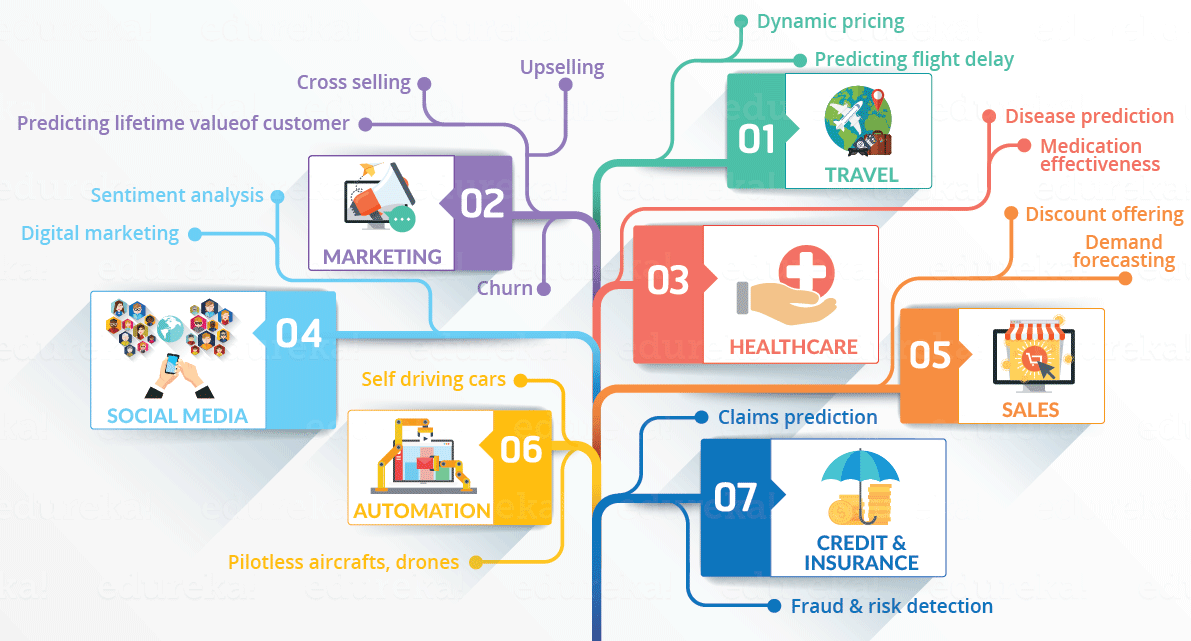
Schauen wir uns die folgende Infografik an, um alle Bereiche zu sehen, in denen Data Science seinen Eindruck hinterlässt.
Wer ist ein Data Scientist?
Es gibt verschiedene Definitionen für Data Scientists. Mit einfachen Worten, ein Data Scientist ist einer, der die Kunst der Data Science praktiziert.Der Begriff 'Data Scientist' wurdegeprägt nach Berücksichtigung der Tatsache, dass ein Data Scientist viele Informationen aus den wissenschaftlichen Bereichen und Anwendungen bezieht, sei es Statistik oder Mathematik.
Was macht ein Data Scientist?
Datenwissenschaftler sind diejenigen, die komplexe Datenprobleme mit ihrem starken Fachwissen in bestimmten wissenschaftlichen Disziplinen lösen. Sie arbeiten mit verschiedenen Elementen in Bezug auf Mathematik, Statistik, Informatik usw. (obwohl sie möglicherweise nicht in allen diesen Bereichen Experten sind).Sie nutzen die neuesten Technologien in hohem Maße, um Lösungen zu finden und Schlussfolgerungen zu ziehen, die für das Wachstum und die Entwicklung eines Unternehmens von entscheidender Bedeutung sind. Datenwissenschaftler präsentieren die Daten in einer viel nützlicheren Form als die Rohdaten, die ihnen sowohl aus strukturierten als auch aus unstrukturierten Formen zur Verfügung stehen.
Weitere Informationen zu einem Data Scientist finden Sie in diesem Artikel unter
Lassen Sie uns nun BI näher erläutern. Ich bin sicher, Sie haben auch von Business Intelligence (BI) gehört. Oft wird Data Science mit BI verwechselt. Ich werde einige prägnante und klare Aussagen machenKontraste zwischen den beiden, die Ihnen helfen, ein besseres Verständnis zu bekommen. Werfen wir einen Blick.
Business Intelligence (BI) vs. Data Science
- Business Intelligence (BI) analysiert im Wesentlichen die vorherigen Daten, um Rückblicke und Erkenntnisse zur Beschreibung von Geschäftstrends zu erhalten. Hier können Sie mit BI Daten aus externen und internen Quellen entnehmen, vorbereiten, Abfragen ausführen und Dashboards erstellen, um Fragen wie zu beantwortenvierteljährliche Umsatzanalyseoder geschäftliche Probleme. BI kann die Auswirkungen bestimmter Ereignisse in naher Zukunft bewerten.
- Data Science ist ein zukunftsorientierterer Ansatz, ein explorativer Weg mit dem Schwerpunkt auf der Analyse vergangener oder aktueller Daten und der Vorhersage zukünftiger Ergebnisse mit dem Ziel, fundierte Entscheidungen zu treffen. Es beantwortet die offenen Fragen zu „Was“ und „Wie“.
Schauen wir uns einige kontrastierende Funktionen an.
| Eigenschaften | Business Intelligence (BI) | Data Science |
| Datenquellen | Strukturiert (Normalerweise SQL, oft Data Warehouse) | Sowohl strukturiert als auch unstrukturiert (Protokolle, Cloud-Daten, SQL, NoSQL, Text) |
| Ansatz | Statistik und Visualisierung | Statistik, Maschinelles Lernen, Graphanalyse, Neurolinguistische Programmierung (NLP) |
| Fokus | Vergangenheit und Gegenwart | Gegenwart und Zukunft |
| Werkzeuge | Pentaho, Microsoft BI,QlikView, R. | RapidMiner, BigML, Weka, R. |
Hier ging es um Data Science. Lassen Sie uns nun den Lebenszyklus von Data Science verstehen.
Ein häufiger Fehler in Data Science-Projekten besteht darin, Daten zu sammeln und zu analysieren, ohne die Anforderungen zu verstehen oder das Geschäftsproblem richtig zu definieren. Daher ist es sehr wichtig, dass Sie alle Phasen während des gesamten Lebenszyklus von Data Science verfolgen, um ein reibungsloses Funktionieren des Projekts sicherzustellen.
Lebenszyklus der Datenwissenschaft
Hier ist ein kurzer Überblick über die Hauptphasen des Data Science-Lebenszyklus:
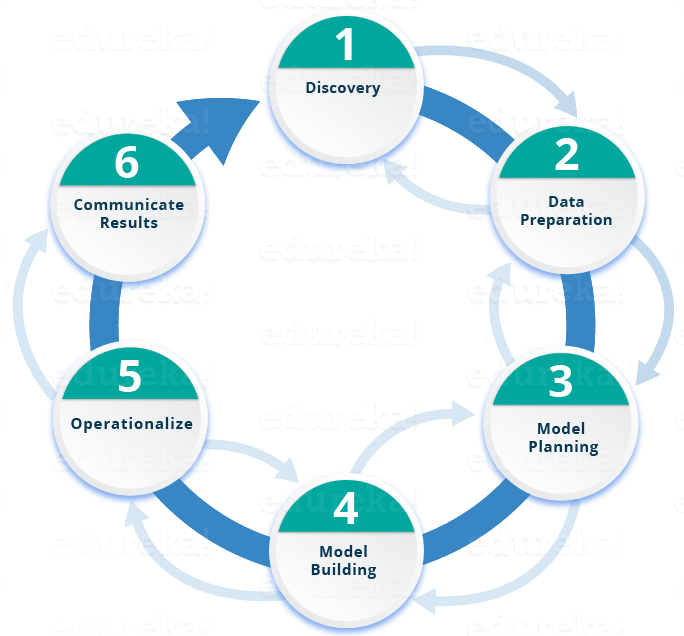
 Phase 1 - Entdeckung: Bevor Sie mit dem Projekt beginnen, ist es wichtig, die verschiedenen Spezifikationen, Anforderungen, Prioritäten und das erforderliche Budget zu kennen. Sie müssen die Fähigkeit besitzen, die richtigen Fragen zu stellen.Hier beurteilen Sie, ob Sie über die erforderlichen Ressourcen in Bezug auf Personen, Technologie, Zeit und Daten verfügen, um das Projekt zu unterstützen.In dieser Phase müssen Sie auch das Geschäftsproblem einrahmen und erste Hypothesen (IH) zum Testen formulieren.
Phase 1 - Entdeckung: Bevor Sie mit dem Projekt beginnen, ist es wichtig, die verschiedenen Spezifikationen, Anforderungen, Prioritäten und das erforderliche Budget zu kennen. Sie müssen die Fähigkeit besitzen, die richtigen Fragen zu stellen.Hier beurteilen Sie, ob Sie über die erforderlichen Ressourcen in Bezug auf Personen, Technologie, Zeit und Daten verfügen, um das Projekt zu unterstützen.In dieser Phase müssen Sie auch das Geschäftsproblem einrahmen und erste Hypothesen (IH) zum Testen formulieren.

Phase 2 - Datenaufbereitung: In dieser Phase benötigen Sie eine analytische Sandbox, in der Sie Analysen für die gesamte Dauer des Projekts durchführen können. Sie müssen Daten vor der Modellierung untersuchen, vorverarbeiten und bedingen. Außerdem führen Sie ETLT (Extrahieren, Transformieren, Laden und Transformieren) durch, um Daten in die Sandbox zu übertragen. Schauen wir uns den statistischen Analysefluss unten an.

Sie können R zur Datenbereinigung, -transformation und -visualisierung verwenden. Auf diese Weise können Sie die Ausreißer erkennen und eine Beziehung zwischen den Variablen herstellen.Sobald Sie die Daten bereinigt und vorbereitet haben, ist es Zeit, sie zu erkundenAnalytikdarauf. Mal sehen, wie Sie das erreichen können.
Phase 3 - Modellplanung:  Hier bestimmen Sie die Methoden und Techniken zum Zeichnen der Beziehungen zwischen Variablen.Diese Beziehungen bilden die Basis für die Algorithmen, die Sie in der nächsten Phase implementieren werden.Sie wenden Exploratory Data Analytics (EDA) mit verschiedenen statistischen Formeln und Visualisierungstools an.
Hier bestimmen Sie die Methoden und Techniken zum Zeichnen der Beziehungen zwischen Variablen.Diese Beziehungen bilden die Basis für die Algorithmen, die Sie in der nächsten Phase implementieren werden.Sie wenden Exploratory Data Analytics (EDA) mit verschiedenen statistischen Formeln und Visualisierungstools an.
Schauen wir uns verschiedene Modellplanungstools an.

- R. verfügt über einen vollständigen Satz von Modellierungsfunktionen und bietet eine gute Umgebung zum Erstellen von Interpretationsmodellen.
- SQL Analysis-Dienste kann datenbankinterne Analysen mit gängigen Data Mining-Funktionen und grundlegenden Vorhersagemodellen durchführen.
- SAS / ACCESS kann für den Zugriff auf Daten von Hadoop verwendet werden und dient zum Erstellen wiederholbarer und wiederverwendbarer Modellflussdiagramme.
Obwohl viele Werkzeuge auf dem Markt vorhanden sind, ist R das am häufigsten verwendete Werkzeug.
Nachdem Sie nun Einblicke in die Art Ihrer Daten erhalten und die zu verwendenden Algorithmen festgelegt haben. In der nächsten Phase werden Sieanwendenden Algorithmus und bauen ein Modell auf.
 Phase 4 - Modellbau: In dieser Phase entwickeln Sie Datensätze für Schulungs- und Testzwecke. Hier ySie müssen überlegen, ob Ihre vorhandenen Tools für die Ausführung der Modelle ausreichen oder ob eine robustere Umgebung erforderlich ist (z. B. schnelle und parallele Verarbeitung). Sie analysieren verschiedene Lerntechniken wie Klassifizierung, Assoziation und Clustering, um das Modell zu erstellen.
Phase 4 - Modellbau: In dieser Phase entwickeln Sie Datensätze für Schulungs- und Testzwecke. Hier ySie müssen überlegen, ob Ihre vorhandenen Tools für die Ausführung der Modelle ausreichen oder ob eine robustere Umgebung erforderlich ist (z. B. schnelle und parallele Verarbeitung). Sie analysieren verschiedene Lerntechniken wie Klassifizierung, Assoziation und Clustering, um das Modell zu erstellen.
Sie können die Modellbildung mit den folgenden Tools erreichen.

Phase 5 - Operationalisieren:  In dieser Phase liefern Sie Abschlussberichte, Briefings, Code und technische Dokumente.Darüber hinaus wird manchmal ein Pilotprojekt auch in einer Echtzeit-Produktionsumgebung implementiert. Auf diese Weise erhalten Sie vor der vollständigen Bereitstellung ein klares Bild der Leistung und anderer damit verbundener Einschränkungen in geringem Umfang.
In dieser Phase liefern Sie Abschlussberichte, Briefings, Code und technische Dokumente.Darüber hinaus wird manchmal ein Pilotprojekt auch in einer Echtzeit-Produktionsumgebung implementiert. Auf diese Weise erhalten Sie vor der vollständigen Bereitstellung ein klares Bild der Leistung und anderer damit verbundener Einschränkungen in geringem Umfang.
 Phase 6 - Ergebnisse kommunizieren: Jetzt ist es wichtig zu bewerten, ob Sie Ihr in der ersten Phase geplantes Ziel erreicht haben. In der letzten Phase identifizieren Sie also alle wichtigen Ergebnisse, kommunizieren mit den Stakeholdern und bestimmen, ob die Ergebnisse vorliegendes Projekts sind ein Erfolg oder ein Misserfolg basierend auf den in Phase 1 entwickelten Kriterien.
Phase 6 - Ergebnisse kommunizieren: Jetzt ist es wichtig zu bewerten, ob Sie Ihr in der ersten Phase geplantes Ziel erreicht haben. In der letzten Phase identifizieren Sie also alle wichtigen Ergebnisse, kommunizieren mit den Stakeholdern und bestimmen, ob die Ergebnisse vorliegendes Projekts sind ein Erfolg oder ein Misserfolg basierend auf den in Phase 1 entwickelten Kriterien.
Jetzt werde ich eine Fallstudie machen, um Ihnen die verschiedenen oben beschriebenen Phasen zu erklären.
Fallstudie: Diabetes-Prävention
Was wäre, wenn wir das Auftreten von Diabetes vorhersagen und im Voraus geeignete Maßnahmen ergreifen könnten, um dies zu verhindern?
In diesem Anwendungsfall werden wir das Auftreten von Diabetes anhand des gesamten zuvor diskutierten Lebenszyklus vorhersagen. Lassen Sie uns die verschiedenen Schritte durchgehen.
Schritt 1:
- Zuerst,Wir werden die Daten basierend auf der Krankengeschichte sammelndes Patienten wie in Phase 1 beschrieben. Sie können sich auf die folgenden Probendaten beziehen.
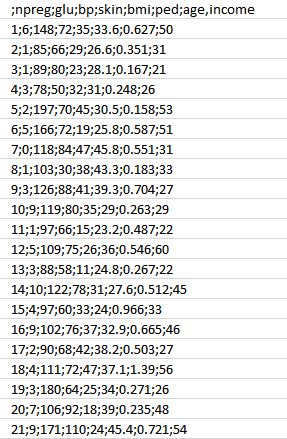
- Wie Sie sehen können, haben wir die verschiedenen Attribute, wie unten erwähnt.
Attribute:
- npreg - Anzahl der Schwangerschaften
- Glukose - Plasmaglukosekonzentration
- bp - Blutdruck
- Haut - Trizeps Hautfaltenstärke
- bmi - Body Mass Index
- ped - Diabetes Stammbaumfunktion
- Alter - Alter
- Einkommen - Einkommen
Schritt 2:
- Sobald wir die Daten haben, müssen wir sie bereinigen und für die Datenanalyse vorbereiten.
- Diese Daten weisen viele Inkonsistenzen auf, wie fehlende Werte, leere Spalten, abrupte Werte und falsches Datenformat, die bereinigt werden müssen.
- Hier haben wir die Daten in einer einzigen Tabelle unter verschiedenen Attributen organisiert, damit sie strukturierter aussehen.
- Schauen wir uns die folgenden Beispieldaten an.
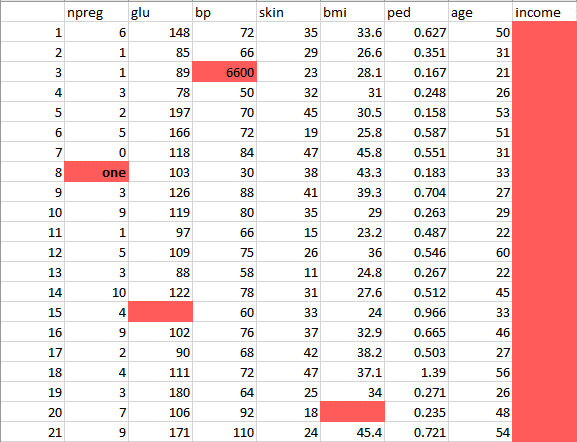
Diese Daten weisen viele Inkonsistenzen auf.
- In der Spalte npreg , 'Eins' ist geschrieben inWörter,während es in der numerischen Form wie 1 sein sollte.
- In Spalte bp einer der Werte ist 6600, was unmöglich ist (zumindest für Menschen) da bp nicht auf einen so großen Wert steigen kann.
- Wie Sie sehen können Einkommen Die Spalte ist leer und macht auch keinen Sinn bei der Vorhersage von Diabetes. Daher ist es überflüssig, es hier zu haben und sollte aus der Tabelle entfernt werden.
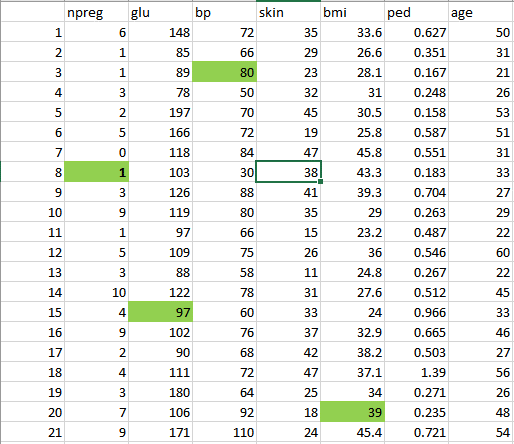
- Wir werden diese Daten also bereinigen und vorverarbeiten, indem wir die Ausreißer entfernen, die Nullwerte auffüllen und den Datentyp normalisieren. Wenn Sie sich erinnern, ist dies unsere zweite Phase, die Datenvorverarbeitung.
- Schließlich erhalten wir die unten gezeigten sauberen Daten, die für die Analyse verwendet werden können.
Schritt 3:
Lassen Sie uns nun einige Analysen durchführen, wie weiter oben in Phase 3 erläutert.
- Zuerst laden wir die Daten in die analytische Sandbox und wenden verschiedene statistische Funktionen darauf an. Zum Beispiel hat R Funktionen wie beschreibt Das gibt uns die Anzahl der fehlenden Werte und eindeutigen Werte. Wir können auch die Zusammenfassungsfunktion verwenden, die statistische Informationen wie Mittelwert, Median, Bereich, Min- und Max-Werte liefert.
- Anschließend verwenden wir Visualisierungstechniken wie Histogramme, Liniendiagramme und Boxplots, um eine gute Vorstellung von der Verteilung der Daten zu erhalten.
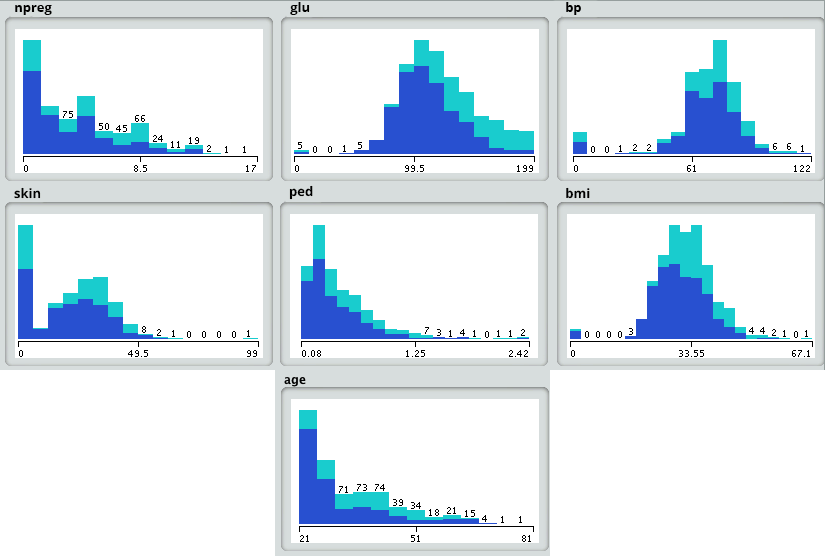
Schritt 4:
Basierend auf den Erkenntnissen aus dem vorherigen Schritt ist der Entscheidungsbaum die beste Lösung für diese Art von Problem. Mal sehen wie?
- Da haben wir schon die Hauptattribute für die Analyse wie npreg, bmi usw., also werden wir verwendenbetreute Lerntechnik zum Aufbau einesModell hier.
- Darüber hinaus haben wir den Entscheidungsbaum besonders verwendet, da er alle Attribute auf einmal berücksichtigt, wie diejenigen, die eine habenlineare Beziehung sowie solche, die eine nichtlineare Beziehung haben. In unserem Fall haben wir eine lineare Beziehung zwischen npreg und Alter, während die nichtlineare Beziehung zwischen npreg und ped .
- Entscheidungsbaummodelle sind auch sehr robust, da wir die unterschiedliche Kombination von Attributen verwenden können, um verschiedene Bäume zu erstellen und schließlich das mit maximaler Effizienz zu implementieren.
Werfen wir einen Blick auf unseren Entscheidungsbaum.
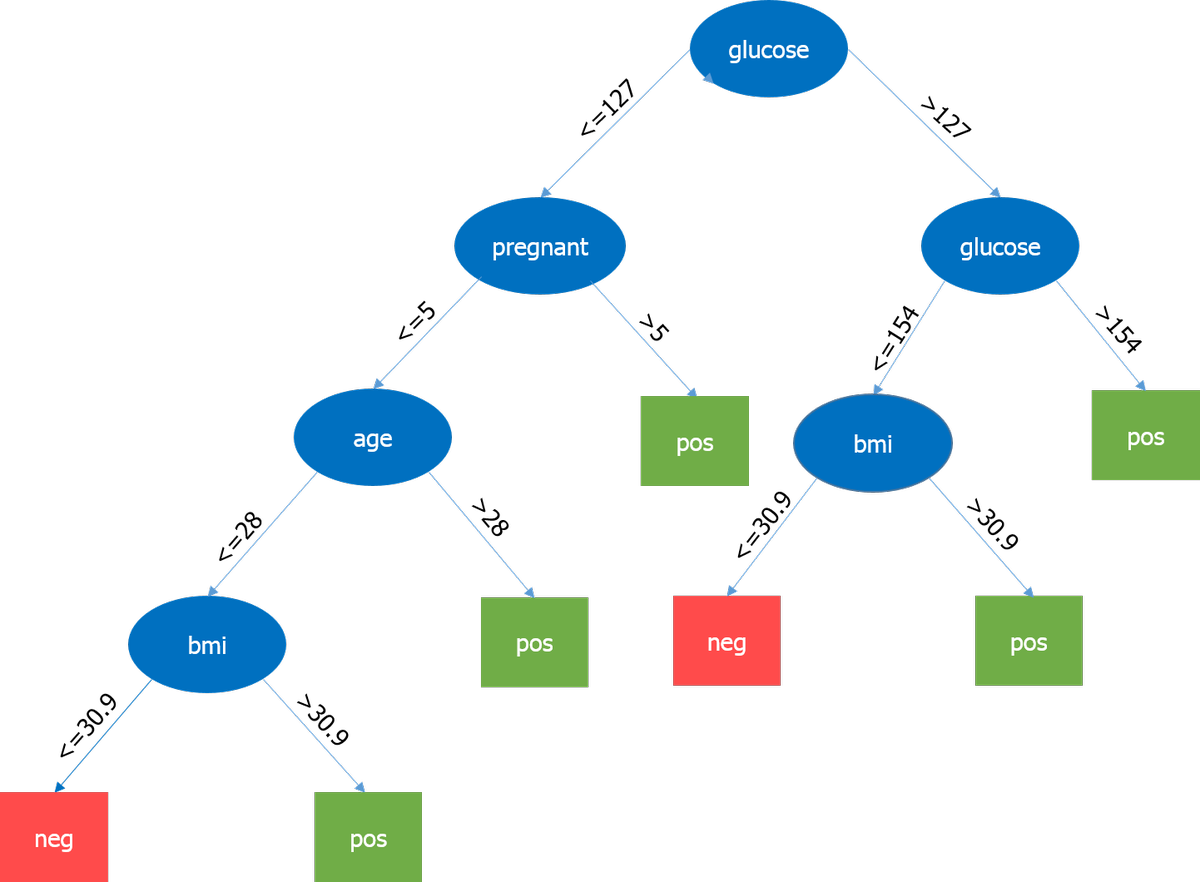
Hier ist der wichtigste Parameter der Glukosespiegel, also unser Wurzelknoten. Der aktuelle Knoten und sein Wert bestimmen nun den nächsten wichtigen Parameter. Es geht weiter, bis wir das Ergebnis in Bezug auf erhalten pos oder neg . Pos bedeutet, dass die Tendenz zu Diabetes positiv ist und neg bedeutet, dass die Tendenz zu Diabetes negativ ist.
Wenn Sie mehr über die Implementierung des Entscheidungsbaums erfahren möchten, lesen Sie diesen Blog
Schritt 5:
In dieser Phase werden wir ein kleines Pilotprojekt durchführen, um zu überprüfen, ob unsere Ergebnisse angemessen sind. Wir werden auch nach Leistungsbeschränkungen suchen, falls vorhanden. Wenn die Ergebnisse nicht korrekt sind, müssen wir das Modell neu planen und neu erstellen.
Schritt 6:
Sobald wir das Projekt erfolgreich ausgeführt haben, werden wir die Ausgabe für die vollständige Bereitstellung freigeben.
Ein Data Scientist zu sein ist leichter gesagt als getan. Mal sehen, was Sie alles brauchen, um ein Data Scientist zu sein.Ein Data Scientist benötigt grundsätzlich Fähigkeitenaus drei Hauptbereichen wie unten gezeigt.
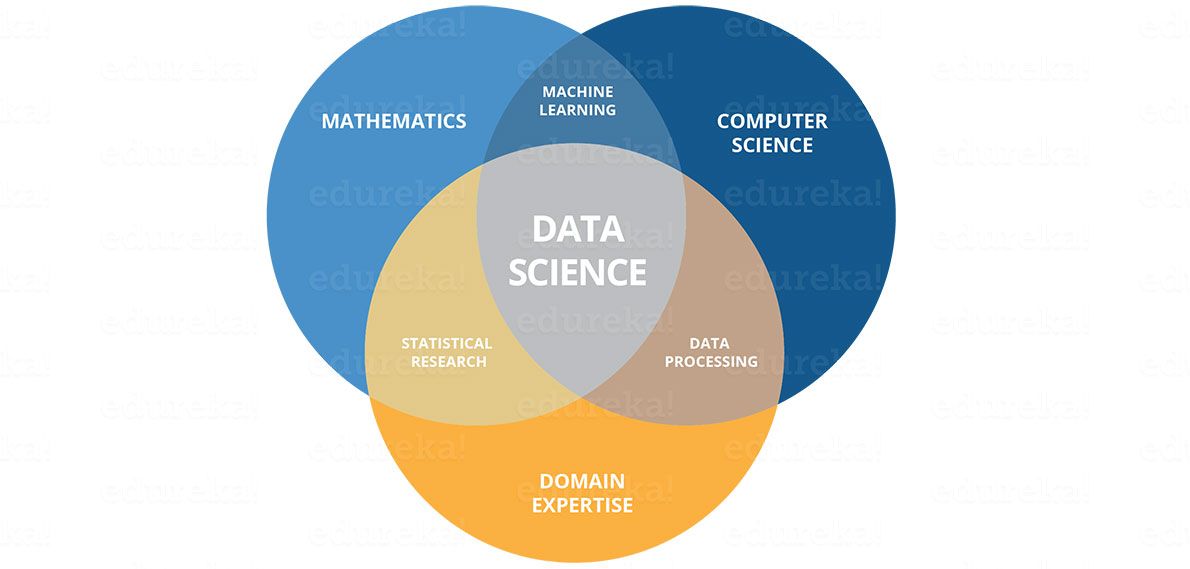
Wie Sie im obigen Bild sehen können, müssen Sie verschiedene Hard- und Soft Skills erwerben. Du musst gut darin sein Statistiken und Mathematik Daten zu analysieren und zu visualisieren. Unnötig zu erwähnen, Maschinelles Lernen bildet das Herz von Data Science und erfordert, dass Sie gut darin sind. Außerdem müssen Sie ein solides Verständnis für das haben Domain Sie arbeiten daran, die geschäftlichen Probleme klar zu verstehen. Ihre Aufgabe endet hier nicht. Sie sollten in der Lage sein, verschiedene Algorithmen zu implementieren, die gute erfordern Codierung Kompetenzen. Sobald Sie bestimmte wichtige Entscheidungen getroffen haben, ist es wichtig, dass Sie diese den Stakeholdern übermitteln. So gut Kommunikation wird definitiv Brownie-Punkte zu Ihren Fähigkeiten hinzufügen.
Ich fordere Sie dringend auf, dieses Video-Tutorial zu Data Science zu lesen, in dem erklärt wird, was Data Science ist und was wir im Blog besprochen haben. Mach weiter, genieße das Video und sag mir, was du denkst.
Was ist Data Science? Data Science Kurs - Data Science Tutorial für Anfänger | Edureka
Dieses Edureka Data Science-Kursvideo führt Sie durch die Anforderungen von Data Science, Data Science, Data Science-Anwendungsfälle für Unternehmen, BI vs. Data Science, Datenanalysetools, Data Science-Lebenszyklus sowie eine Demo.
Am Ende ist es nicht falsch zu sagen, dass die Zukunft den Data Scientists gehört. Es wird vorausgesagt, dass bis Ende des Jahres 2018 rund eine Million Data Scientists benötigt werden. Immer mehr Daten bieten die Möglichkeit, wichtige Geschäftsentscheidungen zu treffen. Es wird bald die Art und Weise verändern, wie wir die Welt betrachten, die mit Daten um uns herum überflutet ist. Daher sollte ein Data Scientist hochqualifiziert und motiviert sein, die komplexesten Probleme zu lösen.
Ich hoffe, Ihnen hat das Lesen meines Blogs gefallen und Sie haben verstanden, was Data Science ist.Schauen Sie sich unsere Hier geht es um von Lehrern geführtes Live-Training und praktische Projekterfahrung.