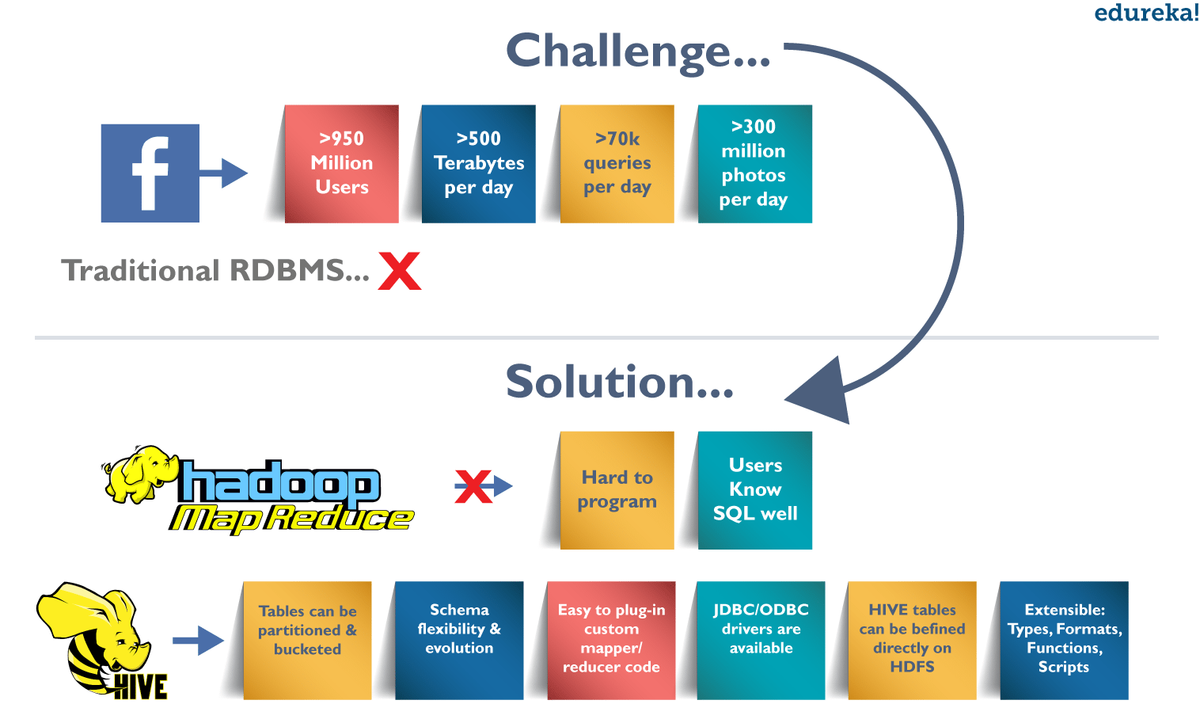
Spark vs Hadoop: Welches ist das beste Big Data Framework?
Dieser Blog-Beitrag spricht über Apache Spark vs Hadoop. Sie erhalten eine Vorstellung davon, welches Big Data-Framework in verschiedenen Szenarien das richtige ist.

Dieser Blog-Beitrag spricht über Apache Spark vs Hadoop. Sie erhalten eine Vorstellung davon, welches Big Data-Framework in verschiedenen Szenarien das richtige ist.
In diesem Blog erfahren Sie, wie Sie das sbteclipse-Plugin installieren und einrichten. Es enthält schrittweise Anweisungen zum Ausführen der Scala-Anwendung in Eclipse IDE.
Dieser Blog-Beitrag erklärt, warum Sie nach Hadoop mit Apache Spark beginnen müssen und warum das Erlernen von Spark nach dem Erlernen von Hadoop Wunder für Ihre Karriere bewirken kann!
Dieses Apache Drill-Tutorial bietet Ihnen alle Informationen, die Sie benötigen, um mit der Apache Drill-Abfrage-Engine und der Verwendung mit Hadoop, Big Data und Apache Spark zu beginnen.
In diesem Spark Hadoop-Blog erfahren Sie alles, was Sie über Apache Spark combinByKey wissen müssen. Ermitteln Sie die durchschnittliche Punktzahl pro Schüler mithilfe der kombinierten Methode.
Apache Falcon ist eine neue Datenverwaltungsplattform für das Hadoop-Ökosystem, die die Onboarding-Feed-Verarbeitung und das Feed-Management in Hadoop-Clustern vereinfacht. Erfahren Sie, wie Sie es einrichten.
In diesem Apache Spark-Blog werden Spark-Akkumulatoren ausführlich erläutert. Erfahren Sie anhand von Beispielen, wie Spark-Akkus verwendet werden. Funkenakkumulatoren sind wie Hadoop Mapreduce-Zähler.
In diesem Blog erfahren Sie alles über Apache Flink und das Einrichten eines Flink-Clusters. Flink unterstützt Echtzeit- und Stapelverarbeitung und ist eine unverzichtbare Big Data-Technologie für Big Data Analytics.
In diesem Blogbeitrag wird das verteilte Caching mit Broadcast-Variablen erläutert und Sie können mit der effizienten Verteilung großer Werte in der Spark-Programmierung beginnen.
CCA- und CCP-Zertifizierungen von Cloudera haben die CCDH- und CCSHB-Prüfungen ersetzt. In diesem Blog erfahren Sie alles, was Sie über die neuen Zertifizierungen wissen müssen.
In diesem Blogbeitrag werden statusbehaftete Transformationen mit Fenstern in Spark Streaming erläutert. Erfahren Sie alles über das stapelweise Verfolgen von Daten mithilfe von D-Streams.
Dieser Blog-Beitrag beschreibt zustandsbehaftete Transformationen in Spark Streaming. Erfahren Sie alles über kumulatives Tracking und Up-Skills für eine Hadoop Spark-Karriere.
Hadoop & Big Data-Technologien revolutionieren die Analytik im Gesundheitswesen. In diesem Big Data-Blog im Gesundheitswesen wird erläutert, wie Big Data-Analysen die medizinische Versorgung verbessern können.
Dieser Blog-Beitrag zu Hadoop Streaming ist eine Schritt-für-Schritt-Anleitung zum Schreiben eines Hadoop MapReduce-Programms in Python zur Verarbeitung großer Mengen von Big Data.
Dieser Blog zum Big Data Tutorial bietet Ihnen einen vollständigen Überblick über Big Data, seine Eigenschaften, Anwendungen sowie Herausforderungen mit Big Data.
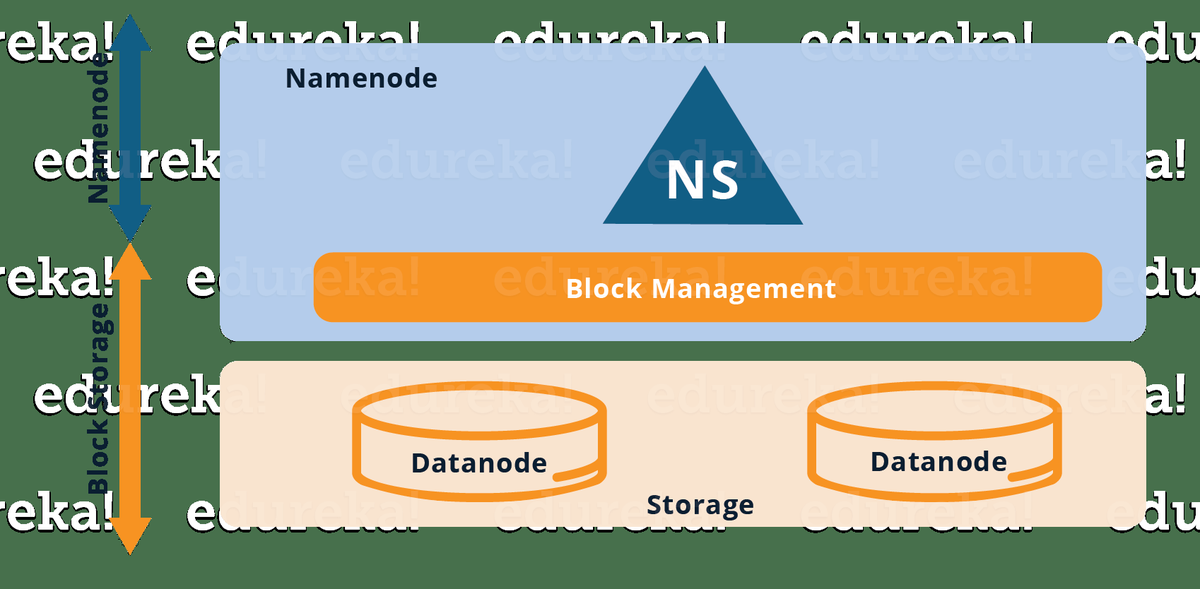
Dieses HDFS-Tutorial-Blog hilft Ihnen dabei, das verteilte HDFS- oder Hadoop-Dateisystem und seine Funktionen zu verstehen. Sie werden auch kurz die Kernkomponenten untersuchen.
Verstehen Sie in diesem Splunk-Tutorial die Unterschiede zwischen Splunk und ELK und Sumo Logic und bestimmen Sie, welches dieser Tools am besten zu Ihnen passt.
In diesem Splunk-Anwendungsfall-Blog erfahren Sie, wie Domino's Pizza Splunk verwendet hat, um Einblicke in das Verbraucherverhalten zu gewinnen und ihre Geschäftsstrategien zu formulieren.
Dieses Tutorial ist eine schrittweise Anleitung zum Installieren und Konfigurieren des Hadoop-Clusters auf einem einzelnen Knoten. Alle Hadoop-Installationsschritte gelten für CentOS-Computer.
In diesem Blog werden die verschiedenen HDFS-Befehle wie fsck, copyFromLocal, expunge, cat usw. behandelt, mit denen das Hadoop-Dateisystem verwaltet wird.