
Die Menge der täglich generierten digitalen Daten wächst exponentiell mit dem Aufkommen digitaler Medien, unter anderem dem Internet der Dinge. Dieses Szenario hat zu Herausforderungen bei der Entwicklung von Tools und Technologien der nächsten Generation zum Speichern und Bearbeiten dieser Daten geführt. Hier kommt Hadoop Streaming ins Spiel! Nachstehend finden Sie eine Grafik, die das Wachstum der jährlich weltweit generierten Daten ab 2013 darstellt. IDC schätzt, dass die jährlich erstellte Datenmenge im Jahr 2025 180 Zettabyte erreichen wird!
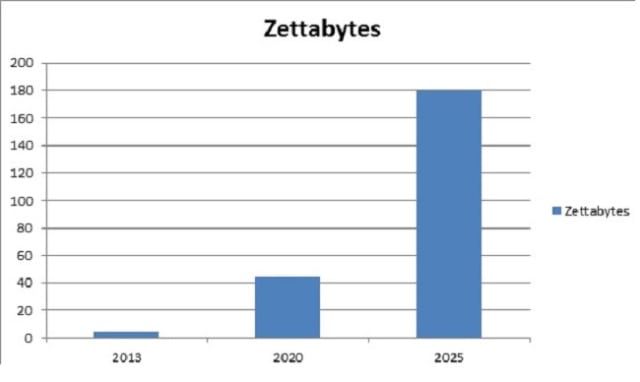
Quelle: IDC
IBM gibt an, dass täglich fast 2,5 Billionen Datenbytes erstellt werden, wobei 90 Prozent der weltweiten Daten in den letzten zwei Jahren erstellt wurden! Es ist eine herausfordernde Aufgabe, eine so große Datenmenge zu speichern. Hadoop kann große Mengen strukturierter und unstrukturierter Daten effizienter verarbeiten als das herkömmliche Enterprise Data Warehouse. Diese enormen Datenmengen werden in verteilten Computerclustern gespeichert. Hadoop Streaming verwendet das MapReduce-Framework, mit dem Anwendungen geschrieben werden können, um riesige Datenmengen zu verarbeiten.
Da das MapReduce-Framework auf Java basiert, fragen Sie sich möglicherweise, wie ein Entwickler daran arbeiten kann, wenn er keine Erfahrung mit Java hat. Nun, Entwickler können Mapper / Reducer-Anwendungen mit ihrer bevorzugten Sprache und ohne viel Java-Kenntnisse schreiben Hadoop-Streaming anstatt auf neue Tools oder Technologien wie Pig and Hive umzusteigen.
Keyword-gesteuertes Framework in Selen
Was ist Hadoop-Streaming?
Hadoop Streaming ist ein Dienstprogramm, das mit der Hadoop-Distribution geliefert wird. Es kann verwendet werden, um Programme für die Big-Data-Analyse auszuführen. Hadoop-Streaming kann mit Sprachen wie Python, Java, PHP, Scala, Perl, UNIX und vielen mehr durchgeführt werden. Mit dem Dienstprogramm können wir Map / Reduce-Jobs mit jeder ausführbaren Datei oder jedem Skript als Mapper und / oder Reduzierer erstellen und ausführen. Beispielsweise:
$ HADOOP_HOME / bin / hadoop jar $ HADOOP_HOME / hadoop-Streaming.jar
-input myInputDirs
-output myOutputDir
-Ordner / bin / cat
-reducer / bin / wc
Parameter Beschreibung::
Python MapReduce-Code::
mapper.py #! / usr / bin / python import sys #Word Count Beispiel # Die Eingabe stammt von der Standardeingabe STDIN für die Zeile in sys.stdin: line = line.strip () #Entfernen Sie führende und nachfolgende Leerzeichen words = line.split ( ) # Teilen Sie die Zeile in Wörter auf und geben Sie sie als Liste für Wörter in Wörtern zurück: # Schreiben Sie die Ergebnisse in die Standardausgabe. STDOUT print '% s% s'% (Wort, 1) # Geben Sie das Wort ein
reducer.py
#! / usr / bin / python importiere sys vom Operator importiere itemgetter # verwende ein Wörterbuch, um Wörter ihren Zählungen zuzuordnen current_word = None current_count = 0 word = None # Die Eingabe kommt von STDIN für die Zeile in sys.stdin: line = line.strip () word, count = line.split ('', 1) try: count = int (count) außer ValueError: weiter, wenn current_word == word: current_count + = count else: if current_word: print '% s% s'% (current_word, current_count) current_count = count current_word = word wenn current_word == word: '% s% s'% drucken (current_word, current_count)Lauf:
- Erstellen Sie eine Datei mit dem folgenden Inhalt und nennen Sie sie word.txt.
Katzenmaus Löwenhirsch Tigerlöwe Elefant Löwenhirsch
- Kopieren Sie die Skripte mapper.py und reducer.py in denselben Ordner, in dem sich die obige Datei befindet.
- Öffnen Sie das Terminal und suchen Sie das Verzeichnis der Datei. Befehl: ls: um alle Dateien im Verzeichnis cd aufzulisten: um das Verzeichnis / den Ordner zu ändern
- Siehe den Inhalt der Datei.
Befehl: cat Dateinamen
> Inhalt von mapper.py
Java-Befehl zum Beenden des Programms
Befehl: cat mapper.py
> Inhalt von reducer.py
Befehl: cat reducer.py
Wir können Mapper und Reducer für lokale Dateien ausführen (z. B. word.txt). Um die Map auszuführen und das Hadoop Distributed File System (HDFS) zu reduzieren, benötigen wir das Hadoop Streaming Glas. Bevor wir die Skripte auf HDFS ausführen, führen wir sie lokal aus, um sicherzustellen, dass sie ordnungsgemäß funktionieren.
> Führen Sie den Mapper aus
Befehl: cat word.txt | python mapper.py
> Führen Sie reducer.py aus
Befehl: cat word.txt | python mapper.py | sort -k1,1 | python reducer.py
Wir können sehen, dass der Mapper und der Reduzierer wie erwartet funktionieren, sodass wir keine weiteren Probleme haben.
Ausführen der Python-Code auf Hadoop
Kopieren Sie lokale Daten (word.txt) nach HDFS, bevor Sie die MapReduce-Task unter Hadoop ausführen
> Beispiel: hdfs dfs -put source_directory hadoop_destination_directory
Befehl: hdfs dfs -put /home/edureka/MapReduce/word.txt / user / edureka
Kopieren Sie den Pfad der JAR-Datei
Der Pfad des Hadoop Streaming-JARs basierend auf der Version des JARs lautet:
/usr/lib/hadoop-2.2.X/share/hadoop/tools/lib/hadoop-streaming-2.2.X.jar
Suchen Sie also das Hadoop-Streaming-Glas auf Ihrem Terminal und kopieren Sie den Pfad.
Befehl:
ls /usr/lib/hadoop-2.2.0/share/hadoop/tools/lib/hadoop-streaming-2.2.0.jar
Führen Sie den MapReduce-Job aus
Befehl:
hadoop jar /usr/lib/hadoop-2.2.0/share/hadoop/tools/lib/hadoop-streaming-2.2.0.jar -file /home/edureka/mapper.py -mapper mapper.py -file / home / edureka / reducer.py -reducer reducer.py -input / user / edureka / word -output / user / edureka / Wordcount
Hadoop bietet eine grundlegende Weboberfläche für Statistiken und Informationen. Wenn der Hadoop-Cluster ausgeführt wird, öffnen Sie http: // localhost: 50070 im Browser. Hier ist der Screenshot der Hadoop-Weboberfläche.
Durchsuchen Sie nun das Dateisystem und suchen Sie die generierte Wordcount-Datei, um die Ausgabe anzuzeigen. Unten ist der Screenshot.
Mit diesem Befehl können wir die Ausgabe auf dem Terminal sehen
Befehl: hadoop fs -cat / user / edureka / Wordcount / part-00000
Sie haben jetzt gelernt, wie Sie ein in Python geschriebenes MapReduce-Programm mit Hadoop Streaming ausführen!
Unterschied zwischen flacher Kopie und tiefer Kopie in Java
Edureka bietet einen Live- und von Lehrern geleiteten Kurs zu Big Data & Hadoop an, der von Branchenkennern gemeinsam erstellt wurde.
Hast du eine Frage an uns? Bitte erwähnen Sie es in den Kommentaren und wir werden uns bei Ihnen melden.