
Hadoop 2.0 Cluster Architecture Federation
Einführung:
In diesem Blog werde ich mich eingehend mit der Hadoop 2.0 Cluster Architecture Federation befassen. Apache Hadoop hat sich seit der Veröffentlichung von Apache Hadoop 1.x stark weiterentwickelt. Wie Sie aus meinem vorherigen Blog wissen, dass die folgt der Master / Slave-Topologie, wobei NameNode als Master-Daemon fungiert und für die Verwaltung anderer Slave-Knoten namens DataNodes verantwortlich ist. In diesem Ökosystem wird dieser einzelne Master-Daemon oder NameNode zu einem Engpass, und im Gegenteil, Unternehmen benötigen einen hoch verfügbaren NameNode. Dieser Grund wurde zur Grundlage der HDFS Federation Architecture und HA-Architektur (Hochverfügbarkeit) .
Die Themen, die ich in diesem Blog behandelt habe, sind folgende:
- Die aktuelle HDFS-Architektur
- Einschränkungen der aktuellen HDFS-Architektur
- HDFS Federation-Architektur
Überblick über die aktuelle HDFS-Architektur:
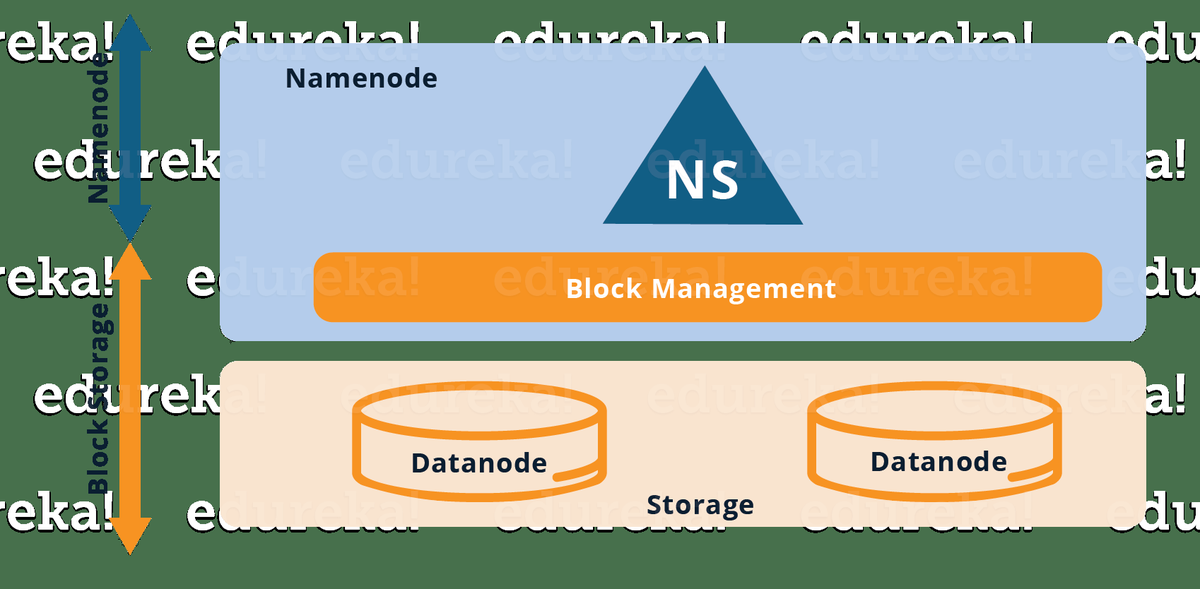
Wie Sie in der obigen Abbildung sehen können, besteht das aktuelle HDFS aus zwei Ebenen:
- HDFS-Namespace (NS): Diese Schicht ist für die Verwaltung der Verzeichnisse, Dateien und Blöcke verantwortlich. Es bietet alle mit Namespace verbundenen Dateisystemvorgänge wie das Erstellen, Löschen oder Ändern der Dateien oder Dateiverzeichnisse.
- Speicherschicht: Es besteht aus zwei Grundkomponenten.
- Blockverwaltung : Es führt die folgenden Operationen aus:
- Überprüft regelmäßig die Herzschläge von DataNodes und verwaltet die DataNode-Mitgliedschaft im Cluster.
- Verwaltet die Blockberichte und verwaltet die Blockposition.
- Unterstützt Blockoperationen wie das Erstellen, Ändern, Löschen und Zuweisen von Blockpositionen.
- Hält den Replikationsfaktor im gesamten Cluster konsistent.
- Blockverwaltung : Es führt die folgenden Operationen aus:
2. Physische Speicherung : Es wird von DataNodes verwaltet, die für das Speichern von Daten verantwortlich sind und dadurch Lese- / Schreibzugriff auf die in HDFS gespeicherten Daten ermöglichen.
Mit der aktuellen HDFS-Architektur können Sie also einen einzelnen Namespace für einen Cluster festlegen. In dieser Architektur ist ein einzelner NameNode für die Verwaltung des Namespace verantwortlich. Diese Architektur ist sehr bequem und einfach zu implementieren. Darüber hinaus bietet es ausreichende Funktionen, um die Anforderungen des kleinen Produktionsclusters zu erfüllen.
Einschränkungen des aktuellen HDFS:
Wie bereits erwähnt, hat das aktuelle HDFS die Anforderungen und Anwendungsfälle eines kleinen Produktionsclusters erfüllt. Große Unternehmen wie Yahoo und Facebook fanden jedoch einige Einschränkungen, da der HDFS-Cluster exponentiell wuchs. Lassen Sie uns einen kurzen Blick auf einige der Einschränkungen werfen:
c ++ Sortieralgorithmus
- Der Namespace ist nicht skalierbar wie DataNodes. Daher können wir nur die Anzahl von DataNodes im Cluster haben, die ein einzelner NameNode verarbeiten kann.
- Die zwei Schichten, d. H. Die Namespace-Schicht und die Speicherschicht, sind eng verbunden Dies macht die alternative Implementierung von NameNode sehr schwierig.
- Die Leistung des gesamten Hadoop-Systems hängt von der Durchsatz des NameNode. Daher hängt die gesamte Leistung aller HDFS-Vorgänge davon ab, wie viele Aufgaben der NameNode zu einem bestimmten Zeitpunkt ausführen kann.
- Der NameNode speichert den gesamten Namespace im RAM für den schnellen Zugriff. Dies führt zu Einschränkungen in Bezug auf Speichergröße d.h. die Anzahl der Namespace-Objekte (Dateien und Blöcke), die ein einzelner Namespace-Server bewältigen kann.
- In vielen Organisationen (Anbietern) mit HDFS-Bereitstellung können mehrere Organisationen (Mandanten) ihren Cluster-Namespace verwenden. Es gibt also keine Trennung des Namespace und daher auch keine keine Isolation unter den Mandantenorganisationen, die den Cluster verwenden.
HDFS Federation-Architektur:
- In der HDFS Federation Architecture haben wir eine horizontale Skalierbarkeit des Namensdienstes. Daher haben wir mehrere NameNodes, die zusammengeschlossen sind, d. H. Unabhängig voneinander.
- Die DataNodes befinden sich unten, d. H. Unter der Speicherschicht.
- Jeder DataNode registriert sich bei allen NameNodes im Cluster.
- Die DataNodes übertragen periodische Herzschläge, blockieren Berichte und verarbeiten Befehle von den NameNodes.
Die bildliche Darstellung der HDFS Federation-Architektur ist unten angegeben:
Bevor ich fortfahre, möchte ich kurz auf das obige Architekturbild eingehen:
- Es gibt mehrere Namespaces (NS1, NS2,…, NSn), von denen jeder von seinem jeweiligen NameNode verwaltet wird.
- Jeder Namespace hat einen eigenen Blockpool (NS1 hat Pool 1, NSk hat Pool k und so weiter).
- Wie in der Abbildung gezeigt, werden die Blöcke aus Pool 1 (himmelblau) auf DataNode 1, DataNode 2 usw. gespeichert. In ähnlicher Weise befinden sich alle Blöcke aus jedem Blockpool auf allen DataNodes.
Lassen Sie uns nun die Komponenten der HDFS-Verbundarchitektur im Detail verstehen:
Blockpool:
Der Blockpool ist nichts anderes als eine Gruppe von Blöcken, die zu einem bestimmten Namespace gehören. Wir haben also eine Sammlung von Blockpools, in denen jeder Blockpool unabhängig vom anderen verwaltet wird. Diese Unabhängigkeit, bei der jeder Blockpool unabhängig verwaltet wird, ermöglicht es dem Namespace, Block-IDs für neue Blöcke ohne Koordination mit anderen Namespaces zu erstellen. Die im gesamten Blockpool vorhandenen Datenblöcke werden in allen DataNodes gespeichert. Grundsätzlich bietet der Blockpool eine Abstraktion, sodass die in den DataNodes (wie in der Single Namespace Architecture) befindlichen Datenblöcke entsprechend einem bestimmten Namespace gruppiert werden können.
Namespace-Volume:
Das Namespace-Volume ist zusammen mit seinem Blockpool nichts anderes als ein Namespace. Daher haben wir in HDFS Federation mehrere Namespace-Volumes. Es ist eine in sich geschlossene Verwaltungseinheit, d. H. Jedes Namespace-Volume kann unabhängig funktionieren. Wenn ein NameNode oder Namespace gelöscht wird, wird auch der entsprechende Blockpool gelöscht, der sich auf den DataNodes befindet.
Demo zu Hadoop 2.0 Cluster Architecture Federation | Edureka
Ich denke, Sie haben eine ziemlich gute Vorstellung von der HDFS Federation Architecture. Es ist eher ein theoretisches Konzept und wird im Allgemeinen nicht in einem praktischen Produktionssystem verwendet. Es gibt einige Implementierungsprobleme mit HDFS Federation, die die Bereitstellung erschweren. deshalb, die HA-Architektur (Hochverfügbarkeit) wird bevorzugt, um das Single Point of Failure-Problem zu lösen. Ich habe das abgedeckt HDFS HA-Architektur in meinem nächsten Blog.
Nachdem Sie die Hadoop HDFS Federation-Architektur verstanden haben, lesen Sie die von Edureka, einem vertrauenswürdigen Online-Lernunternehmen mit einem Netzwerk von mehr als 250.000 zufriedenen Lernenden auf der ganzen Welt. Der Edureka Big Data Hadoop-Zertifizierungskurs hilft Lernenden, Experten für HDFS, Garn, MapReduce, Schwein, Bienenstock, HBase, Oozie, Flume und Sqoop zu werden. Dabei werden Anwendungsfälle in Echtzeit in den Bereichen Einzelhandel, soziale Medien, Luftfahrt, Tourismus und Finanzen verwendet.
Hast du eine Frage an uns? Bitte erwähnen Sie es in den Kommentaren und wir werden uns bei Ihnen melden.
wie man ein Java-Programm im Code stoppt