
Hadoop YARN strickt die Speichereinheit von Hadoop, d. H. HDFS (Hadoop Distributed File System), mit den verschiedenen Verarbeitungswerkzeugen. Für diejenigen unter Ihnen, die mit diesem Thema völlig neu sind, steht YARN für „ Y. und ZU nicht weiter R. esource N. Egoist “. Ich würde auch vorschlagen, dass Sie unsere durchgehen und bevor Sie mit dem Erlernen von Apache Hadoop YARN fortfahren. Ich werde hier die folgenden Themen erläutern, um sicherzustellen, dass am Ende dieses Blogs Ihr Verständnis von Hadoop YARN klar ist.
- Warum Garn?
- Einführung in Hadoop YARN
- Komponenten von YARN
- Bewerbung in YARN
- Anwendungsworkflow in Hadoop YARN
Warum Garn?
In Hadoop Version 1.0, das auch als MRV1 (MapReduce Version 1) bezeichnet wird, führte MapReduce sowohl Verarbeitungs- als auch Ressourcenverwaltungsfunktionen aus. Es bestand aus einem Job Tracker, der der einzige Master war. Der Job Tracker hat die Ressourcen zugewiesen, die Planung durchgeführt und die Verarbeitungsjobs überwacht. Es ordnete Karten zu und reduzierte Aufgaben in einer Reihe von untergeordneten Prozessen, die als Task-Tracker bezeichnet werden. Die Task Tracker meldeten ihre Fortschritte regelmäßig an den Job Tracker.
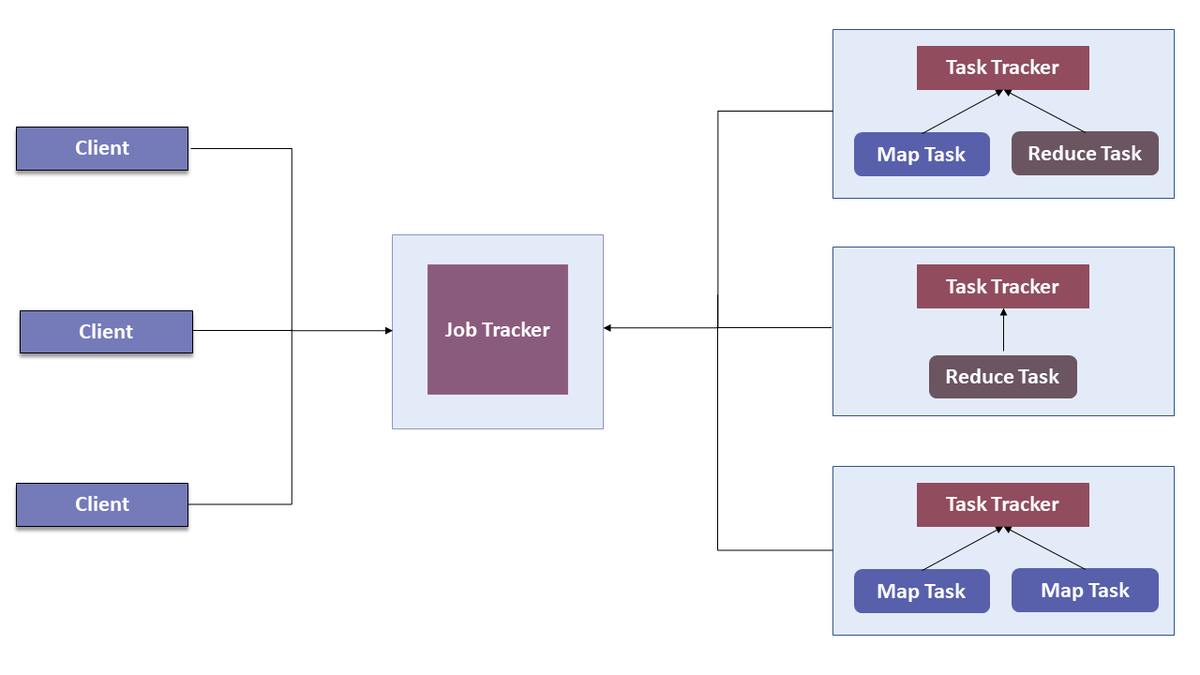
Dieses Design führte aufgrund eines einzelnen Job Tracker zu einem Engpass bei der Skalierbarkeit.IBM erwähnte in seinem Artikel, dass laut Yahoo! die praktischen Grenzen eines solchen Entwurfs mit einem Cluster von 5000 Knoten und 40.000 gleichzeitig ausgeführten Aufgaben erreicht werden.Abgesehen von dieser Einschränkung ist die Verwendung von Rechenressourcen in MRV1 ineffizient. Außerdem wurde das Hadoop-Framework nur auf das MapReduce-Verarbeitungsparadigma beschränkt.
Unterschied zwischen Koch und Ansible
Um all diese Probleme zu lösen, wurde YARN im Jahr 2012 von Yahoo und Hortonworks in Hadoop Version 2.0 eingeführt. Die Grundidee von YARN besteht darin, MapReduce zu entlasten, indem die Verantwortung für das Ressourcenmanagement und die Auftragsplanung übernommen wird. YARN hat damit begonnen, Hadoop die Möglichkeit zu geben, Nicht-MapReduce-Jobs innerhalb des Hadoop-Frameworks auszuführen.
Sie können auch das folgende Video sehen, in dem unsere Experte diskutiert YARN-Konzepte und deren Architektur im Detail.
Hadoop Garn Tutorial | Hadoop Garn Architektur | Edureka
Mit der Einführung von YARN wurde die wurde völlig revolutioniert. Es wurde viel flexibler, effizienter und skalierbarer. Als Yahoo im ersten Quartal 2013 mit YARN live ging, half es dem Unternehmen, die Größe seines Hadoop-Clusters von 40.000 Knoten auf 32.000 Knoten zu verkleinern. Die Zahl der Arbeitsplätze verdoppelte sich jedoch auf 26 Millionen pro Monat.
Einführung in Hadoop YARN
Nachdem ich Sie über die Notwendigkeit von YARN aufgeklärt habe, möchte ich Ihnen die Kernkomponente von Hadoop v2.0 vorstellen. GARN . Mit YARN können verschiedene Datenverarbeitungsmethoden wie Grafikverarbeitung, interaktive Verarbeitung, Stream-Verarbeitung sowie Stapelverarbeitung in HDFS gespeicherte Daten ausgeführt und verarbeitet werden. Daher öffnet YARN Hadoop für andere Arten verteilter Anwendungen außerhalb von MapReduce.
Mit YARN konnten die Benutzer Vorgänge gemäß den Anforderungen ausführen, indem sie eine Vielzahl von Tools wie z für die Echtzeitverarbeitung, Bienenstock für SQL HBase für NoSQL und andere.
Neben dem Ressourcenmanagement führt YARN auch die Auftragsplanung durch. YARN führt alle Ihre Verarbeitungsaktivitäten aus, indem es Ressourcen zuweist und Aufgaben plant. Die Apache Hadoop YARN-Architektur besteht aus den folgenden Hauptkomponenten:
- Ressourcenmanager :: Läuft auf einem Master-Daemon und verwaltet die Ressourcenzuweisung im Cluster.
- Knotenmanager: Sie laufen auf den Slave-Daemons und sind für die Ausführung einer Aufgabe auf jedem einzelnen Datenknoten verantwortlich.
- Anwendungsmaster: Verwaltet den Benutzerlebenszyklus und die Ressourcenanforderungen einzelner Anwendungen. Es arbeitet mit dem Node Manager zusammen und überwacht die Ausführung von Aufgaben.
- Container: Paket von Ressourcen einschließlich RAM, CPU, Netzwerk, Festplatte usw. auf einem einzelnen Knoten.
Komponenten von YARN
Sie können YARN als das Gehirn Ihres Hadoop-Ökosystems betrachten. Das Bild unten zeigt die YARN-Architektur.
Das erste Komponente von YARN Architecture ist,
Ressourcenmanager
- Es ist die ultimative Autorität bei der Ressourcenzuweisung .
- Beim Empfang der Verarbeitungsanforderungen werden Teile der Anforderungen entsprechend an die entsprechenden Knotenmanager weitergeleitet, wo die eigentliche Verarbeitung stattfindet.
- Es ist der Schiedsrichter der Clusterressourcen und entscheidet über die Zuweisung der verfügbaren Ressourcen für konkurrierende Anwendungen.
- Optimiert die Clusterauslastung, indem alle Ressourcen ständig genutzt werden, und zwar unter Berücksichtigung verschiedener Einschränkungen wie Kapazitätsgarantien, Fairness und SLAs.
- Es hat zwei Hauptkomponenten:a) Schedulerb)Anwendungsmanager
a) Scheduler
- Der Scheduler ist für die Zuweisung von Ressourcen zu den verschiedenen laufenden Anwendungen verantwortlich, wobei Kapazitäts-, Warteschlangen- usw. Einschränkungen unterliegen.
- In ResourceManager wird es als reiner Scheduler bezeichnet. Dies bedeutet, dass keine Überwachung oder Verfolgung des Status für die Anwendungen durchgeführt wird.
- Wenn ein Anwendungsfehler oder ein Hardwarefehler vorliegt, garantiert der Scheduler nicht, dass die fehlgeschlagenen Aufgaben neu gestartet werden.
- Führt die Planung basierend auf den Ressourcenanforderungen der Anwendungen durch.
- Es verfügt über ein steckbares Richtlinien-Plug-In, das für die Aufteilung der Clusterressourcen auf die verschiedenen Anwendungen verantwortlich ist. Es gibt zwei solche Plug-Ins: Kapazitätsplaner und Fair Scheduler , die derzeit in ResourceManager als Scheduler verwendet werden.
b) Anwendungsmanager
- Es ist für die Annahme von Einsendungen verantwortlich.
- Verhandelt den ersten Container aus dem Ressourcenmanager zur Ausführung des anwendungsspezifischen Anwendungsmasters.
- Verwaltet das Ausführen der Anwendungsmaster in einem Cluster und bietet einen Dienst zum Neustarten des Anwendungsmaster-Containers bei einem Fehler.
Kommen zum zweite Komponente welches ist::
Knotenmanager
- Es kümmert sich um einzelne Knoten in einem Hadoop-Cluster undverwaltet Benutzerjobs und Workflows auf dem angegebenen Knoten.
- Es registriert sich beim Ressourcenmanager und sendet Herzschläge mit dem Integritätsstatus des Knotens.
- Das Hauptziel besteht darin, Anwendungscontainer zu verwalten, die ihm vom Ressourcenmanager zugewiesen wurden.
- Es bleibt mit dem Ressourcenmanager auf dem neuesten Stand.
- Der Anwendungsmaster fordert den zugewiesenen Container vom Knotenmanager an, indem er ihm einen Container Launch Context (CLC) sendet, der alles enthält, was die Anwendung zum Ausführen benötigt. Der Knotenmanager erstellt den angeforderten Containerprozess und startet ihn.
- Überwacht die Ressourcennutzung (Speicher, CPU) einzelner Container.
- Führt die Protokollverwaltung durch.
- Außerdem wird der Container gemäß den Anweisungen des Ressourcenmanagers beendet.
Das dritte Komponente von Apache Hadoop YARN ist,
Anwendungsmaster
- Eine Bewerbung ist ein einzelner Job, der an das Framework gesendet wird. Jeder solchen Anwendung ist ein eindeutiger Anwendungsmaster zugeordnet, der eine Framework-spezifische Entität darstellt.
- Dieser Prozess koordiniert die Ausführung einer Anwendung im Cluster und verwaltet auch Fehler.
- Seine Aufgabe besteht darin, Ressourcen aus dem Ressourcenmanager auszuhandeln und mit dem Knotenmanager zusammenzuarbeiten, um die Komponentenaufgaben auszuführen und zu überwachen.
- Es ist dafür verantwortlich, geeignete Ressourcencontainer im ResourceManager auszuhandeln, ihren Status zu verfolgen und den Fortschritt zu überwachen.
- Nach dem Start sendet es regelmäßig Herzschläge an den Ressourcenmanager, um dessen Zustand zu bestätigen und die Aufzeichnung seiner Ressourcenanforderungen zu aktualisieren.
Das vierte Komponente ist:
Container
- Es handelt sich um eine Sammlung physischer Ressourcen wie RAM, CPU-Kerne und Festplatten auf einem einzelnen Knoten.
- YARN-Container werden von einem Container-Startkontext verwaltet, bei dem es sich um den Container-Lebenszyklus (CLC) handelt. Dieser Datensatz enthält eine Zuordnung von Umgebungsvariablen, Abhängigkeiten, die in einem remote zugänglichen Speicher gespeichert sind, Sicherheitstoken, Nutzdaten für Node Manager-Dienste und den zum Erstellen des Prozesses erforderlichen Befehl.
- Es gewährt einer Anwendung das Recht, eine bestimmte Menge an Ressourcen (Speicher, CPU usw.) auf einem bestimmten Host zu verwenden.
Bewerbung in YARN
Sehen Sie sich das Bild an und sehen Sie sich die Schritte an, die mit der Einreichung des Antrags von Hadoop YARN verbunden sind:
1) Senden Sie den Job
2)Anwendungs-ID abrufen
3) Kontext der Antragseinreichung
4 a) Container startenStarten
b) Starten Sie Application Master
5) Ressourcen zuweisen
6 a) Behälter
Wirke Double auf Int Java
b) Starten
Anwendungsworkflow in Hadoop YARN
Sehen Sie sich das angegebene Bild an und sehen Sie sich die folgenden Schritte im Anwendungsworkflow von Apache Hadoop YARN an:
- Der Kunde reicht einen Antrag ein
- Der Ressourcenmanager weist einen Container zum Starten des Anwendungsmanagers zu
- Der Anwendungsmanager wird beim Ressourcenmanager registriert
- Der Anwendungsmanager fragt Container vom Ressourcenmanager ab
- Der Anwendungsmanager benachrichtigt den Knotenmanager, um Container zu starten
- Der Anwendungscode wird im Container ausgeführt
- Der Client kontaktiert Resource Manager / Application Manager, um den Anwendungsstatus zu überwachen
- Application Manager hebt die Registrierung bei Resource Manager auf
Jetzt, da Sie Apache Hadoop YARN kennen, lesen Sie die von Edureka, einem vertrauenswürdigen Online-Lernunternehmen mit einem Netzwerk von mehr als 250.000 zufriedenen Lernenden auf der ganzen Welt. Der Edureka Big Data Hadoop-Zertifizierungskurs hilft Lernenden, Experten für HDFS, Garn, MapReduce, Schwein, Bienenstock, HBase, Oozie, Flume und Sqoop zu werden. Dabei werden Anwendungsfälle in Echtzeit in den Bereichen Einzelhandel, soziale Medien, Luftfahrt, Tourismus und Finanzen verwendet.
Hast du eine Frage an uns? Bitte erwähnen Sie es in den Kommentaren und wir werden uns bei Ihnen melden.