
Apache Hive Tutorial: Einführung
Hive ist ein streng branchenweit verwendetes Tool für Big Data Analytics und ein großartiges Tool, um Ihre Arbeit zu starten mit. In diesem Hive-Tutorial-Blog werden wir uns eingehend mit Apache Hive befassen. Apache Hive ist ein Data Warehousing-Tool in der , die eine SQL-ähnliche Sprache zum Abfragen und Analysieren von Big Data bereitstellt. Die Motivation für die Entwicklung von Hive ist der reibungslose Lernpfad für SQL-Entwickler und -Analytiker. Hive ist nicht nur ein Retter für Leute ohne Programmierhintergrund, sondern reduziert auch die Arbeit von Programmierern, die viele Stunden mit dem Schreiben von MapReduce-Programmen verbringen. In diesem Apache Hive Tutorial-Blog werde ich über Folgendes sprechen:
- Was ist Hive?
- Geschichte von Apache Hive - Von Facebook zu Apache
- Vorteile von Apache Hive
- Apache Hive - NASA-Fallstudie
- Apache Hive Architektur
- Metastore-Konfiguration
- Hive-Datenmodell
Apache Hive Tutorial: Was ist Hive?
Apache Hive ist ein Data Warehouse-System, das auf Hadoop aufbaut und zur Analyse strukturierter und halbstrukturierter Daten verwendet wird.Hive abstrahiert die Komplexität von Hadoop MapReduce. Grundsätzlich bietet es einen Mechanismus zum Projizieren der Struktur auf die Daten und zum Ausführen von Abfragen, die in HQL (Hive Query Language) geschrieben sind und SQL-Anweisungen ähneln. Intern werden diese Abfragen oder HQL vom Hive-Compiler in Map-Reduce-Jobs konvertiert. Daher müssen Sie sich keine Gedanken über das Schreiben komplexer MapReduce-Programme machen, um Ihre Daten mit Hadoop zu verarbeiten. Es richtet sich an Benutzer, die mit SQL vertraut sind. Apache Hive unterstützt DDL (Data Definition Language), DML (Data Manipulation Language) und UDF (User Defined Functions).
Hive Tutorial für Anfänger | Hive In Depth verstehen | Edureka
SQL + Hadoop MapReduce = HiveQL
Apache Hive Tutorial: Geschichte von Hive - von Facebook zu Apache
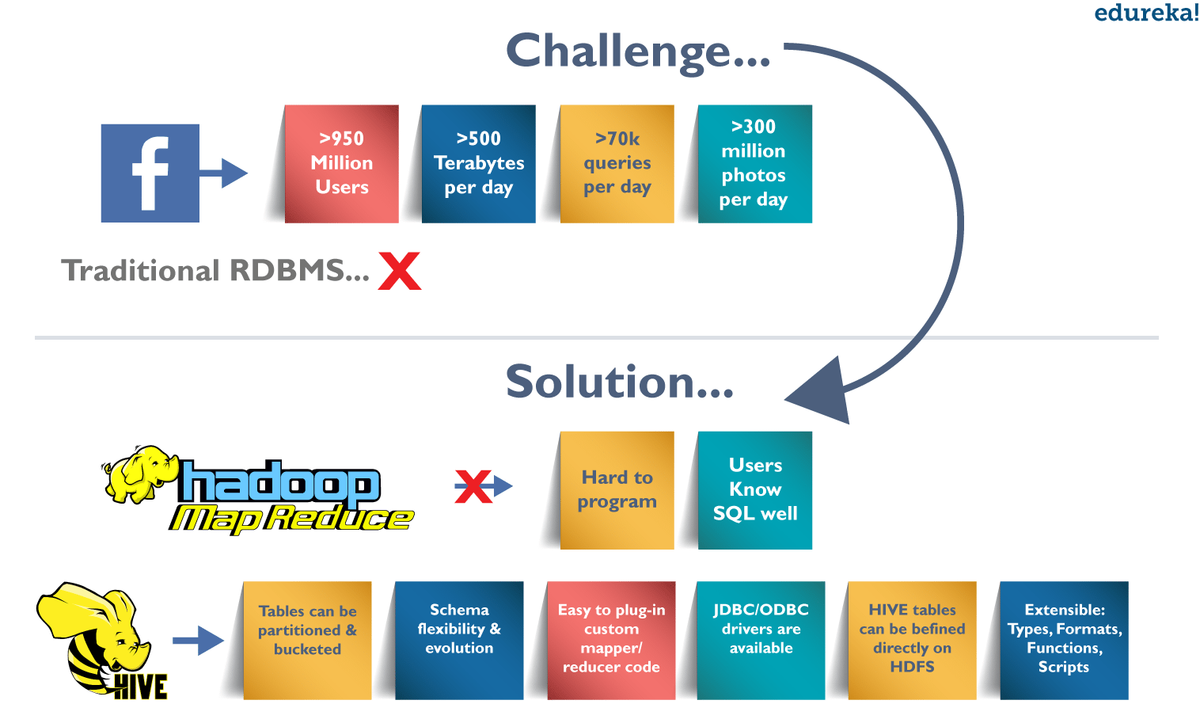 Feige : Hive Tutorial - Facebook Anwendungsfall
Feige : Hive Tutorial - Facebook Anwendungsfall
Herausforderungen bei Facebook: Exponentielles Datenwachstum
Vor 2008 wurde die gesamte Datenverarbeitungsinfrastruktur in Facebook um ein Data Warehouse herum aufgebaut, das auf kommerziellem RDBMS basiert. Diese Infrastrukturen waren in der Lage, die damaligen Bedürfnisse von Facebook zu befriedigen. Da die Daten jedoch sehr schnell wuchsen, wurde es zu einer großen Herausforderung, diesen riesigen Datensatz zu verwalten und zu verarbeiten. Laut einem Facebook-Artikel wurden die Daten von einem 15-TB-Datensatz im Jahr 2007 auf 2-PB-Daten im Jahr 2009 skaliert. Außerdem beinhalten viele Facebook-Produkte eine Analyse der Daten wie Audience Insights, Facebook-Lexikon, Facebook-Anzeigen usw. brauchte eine skalierbare und wirtschaftliche Lösung, um genau dieses Problem zu lösen, und begann daher, das Hadoop-Framework zu verwenden.
Demokratisieren Hadoop - MapReduce
Mit dem Wachstum der Daten nahm die Komplexität der Map-Reduce-Codes jedoch proportional zu. Daher wurde es schwierig, Personen mit nicht programmiertem Hintergrund für das Schreiben von MapReduce-Programmen zu schulen. Um eine einfache Analyse durchzuführen, müssen außerdem hundert Zeilen MapReduce-Code geschrieben werden. Da SQL von Ingenieuren und Analysten, einschließlich Facebook, häufig verwendet wurde, schien es eine logische Möglichkeit zu sein, Hadoop für Benutzer mit SQL-Hintergrund zugänglich zu machen, um SQL auf Hadoop zu setzen.
Die Fähigkeit von SQL, für die meisten analytischen Anforderungen zu genügen, und die Skalierbarkeit von Hadoop haben dazu geführt Apache Hive Dies ermöglicht SQL-ähnliche Abfragen für die in HDFS vorhandenen Daten. Später wurde das Hive-Projekt im August 2008 von Facebook als Open-Source-Projekt bereitgestellt und ist heute als Apache Hive frei verfügbar.
Lassen Sie uns nun die Funktionen oder Vorteile von Hive betrachten, die es so beliebt machen.
Apache Hive Tutorial: Vorteile von Hive
- Nützlich für Personen ohne Programmierhintergrund, da kein komplexes MapReduce-Programm geschrieben werden muss.
- Erweiterbar und skalierbar mit dem wachsenden Datenvolumen und der wachsenden Datenvielfalt fertig zu werden, ohne die Leistung des Systems zu beeinträchtigen.
- Es ist ein effizientes ETL-Tool (Extrahieren, Transformieren, Laden).
- Hive unterstützt alle in Java, PHP, Python, C ++ oder Ruby geschriebenen Clientanwendungen, indem es seine verfügbar macht Thrift Server . (Sie können diese in SQL eingebetteten clientseitigen Sprachen für den Zugriff auf eine Datenbank wie DB2 usw. verwenden.)
- Da die Metadateninformationen von Hive in einem RDBMS gespeichert sind, wird die Zeit für die Durchführung semantischer Überprüfungen während der Abfrageausführung erheblich verkürzt.
Apache Hive Tutorial: Wo kann man Apache Hive verwenden?
Apache Hive nutzt beide Welten, d. H. SQL Database System und Rahmen. Daher wird es von einer Vielzahl von Unternehmen eingesetzt. Es wird hauptsächlich für Data Warehousing verwendet, bei dem Sie Analysen und Data Mining durchführen können, für die keine Echtzeitverarbeitung erforderlich ist. Einige der Felder, in denen Sie Apache Hive verwenden können, sind folgende:
- Data Warehousing
- Ad-hoc-Analyse
Wie gesagt, Sie können nicht nur mit einer Hand klatschen, d. H. Sie können nicht jedes Problem mit einem einzigen Werkzeug lösen. Daher können Sie Hive mit anderen Tools koppeln, um es in vielen anderen Domänen zu verwenden. Beispielsweise kann Tableau zusammen mit Apache Hive für die Datenvisualisierung verwendet werden. Die Integration von Apache Tez in Hive bietet Echtzeitverarbeitungsfunktionen usw.
In diesem Apache Hive Tutorial-Blog werfen wir einen Blick auf eine Fallstudie der NASA, in der Sie erfahren, wie Hive das Problem gelöst hat, mit dem NASA-Wissenschaftler bei der Bewertung von Klimamodellen konfrontiert waren.
Hive Tutorial: NASA-Fallstudie
Ein Klimamodell ist eine mathematische Darstellung von Klimasystemen, die auf verschiedenen Faktoren basiert, die das Klima der Erde beeinflussen. Grundsätzlich beschreibt es das Zusammenspiel verschiedener Klimatreiber wie Ozean, Sonne, Atmosphäre etc. zugeben einen Einblick in die Dynamik des Klimasystems. Es wird verwendet, um Klimabedingungen zu projizieren, indem die Klimaveränderungen anhand von Faktoren simuliert werden, die das Klima beeinflussen. Das Jet Propulsion Laboratory der NASA hat ein regionales Klimamodell-Bewertungssystem (RCMES) zur Analyse und Bewertung des Klima-Output-Modells anhand von Fernerkundungsdaten entwickelt, die in verschiedenen externen Repositories vorhanden sind.
Das RCMES (Regional Climate Model Evaluation System) besteht aus zwei Komponenten:
Apache Spark im Vergleich zu Hadoop Mapreduce
RCMED (Regional Climate Model Evaluation Database):
Es handelt sich um eine skalierbare Cloud-Datenbank, die die Fernerkundungsdaten und Reanalyse-Daten, die sich auf das Klima beziehen, mithilfe von Extraktoren wie Apache OODT-Extraktoren, Apache Tika usw. lädt. Schließlich werden die Daten als Datenpunktmodell der Form (Breitengrad) transformiert , Länge, Zeit, Wert, Höhe) und speichert es in meiner SQL-Datenbank. Der Client kann die in RCMED vorhandenen Daten durch Ausführen von Raum / Zeit-Abfragen abrufen. Die Beschreibung solcher Abfragen ist für uns derzeit nicht relevant.
RCMET (Regional Climate Model Evaluation Toolkit):
Es bietet dem Benutzer die Möglichkeit, die im RCMED vorhandenen Referenzdaten mit den Ausgabedaten des Klimamodells zu vergleichen, die aus anderen Quellen abgerufen wurden, um verschiedene Arten von Analysen und Bewertungen durchzuführen. Sie können sich auf das folgende Bild beziehen, um die Architektur von RCMES zu verstehen.
Die Referenzdaten in der RCMED stammen aus der satellitengestützten Fernerkundung gemäß den verschiedenen Parametern, die für die Bewertung des Klimamodells erforderlich sind. Zum Beispiel - AIRS (Atmospheric Infrared Sounder) liefert Parameter wie Oberflächenlufttemperatur, Temperatur und Geopotential, TRMM (Tropical Rainfall Measurement Mission) liefert monatlichen Niederschlag usw.
Probleme der NASA bei der Verwendung des MySQL-Datenbanksystems:
- Nach dem Laden der MySQL-Datenbank mit 6 Milliarden Tupeln des Formulars (Breite, Länge, Zeit, Datenpunktwert, Höhe) stürzte das System ab (siehe Abbildung oben).
- Selbst nachdem die gesamte Tabelle in kleinere Teilmengen aufgeteilt wurde, erzeugte das System bei der Verarbeitung der Daten einen enormen Overhead.
Daher brauchten sie eine skalierbare Lösung, die diese riesige Datenmenge mit SQL-ähnlichen Abfragefunktionen speichern und verarbeiten kann. Schließlich entschieden sie sich für Apache Hive, um die oben genannten Probleme zu lösen.
Wie kann Apache Hive das Problem lösen?
Lassen Sie uns nun sehen, welche Funktionen das JPL-Team der NASA davon überzeugt haben, Apache Hive als integralen Bestandteil in ihre Lösungsstrategie aufzunehmen:
- Da Apache Hive auf Hadoop ausgeführt wird, ist es skalierbar und kann Daten verteilt und parallel verarbeiten.
- Es bietet eine Hive Query Language, die SQL ähnelt und daher leicht zu erlernen ist.
Bereitstellung von Hive:
Das folgende Bild erklärt den RCMES-Architekten mit Apache Hive-Integration:
Feige : Hive Tutorial - RCMES-Architektur mit Apache Hive
Das obige Bild zeigt die Bereitstellung von Apache Hive in RCMES. Die folgenden Schritte wurden vom NASA-Team während der Bereitstellung von Apache Hive unternommen:
- Sie installierten Hive mit Cloudera und Apache Hadoop, wie im obigen Bild gezeigt.
- Sie verwendeten Apache Sqoop, um Daten aus der MySQL-Datenbank in den Hive aufzunehmen.
- Der Apache OODT-Wrapper wurde implementiert, um Abfragen für Hive durchzuführen und die Daten zurück zu RCMET abzurufen.
Erste Benchmarking-Beobachtungen mit Hive:
- Zunächst luden sie 2,5 Milliarden Datenpunkte in eine einzelne Tabelle und führten eine Zählabfrage durch. Beispielsweise, Bienenstock> Wählen Sie count (datapoint_id) aus dataPoint aus. Das Zählen aller Datensätze dauerte 5 bis 6 Minuten (15 bis 17 Minuten für die gesamten 6,8 Milliarden Datensätze).
- Die Reduktionsphase war schnell, aber die Kartenphase dauerte 95% der gesamten Verarbeitungszeit. Sie benutzten sechs ( 4x Quad-Core ) Systeme mit 24 GB RAM (ungefähr) in jedem der Systeme.
- Auch nach dem Hinzufügen weiterer Computer können Sie die HDFS-Blockgröße (64 MB, 128 MB, 256 MB) und viele andere Konfigurationsvariablen (io) ändern.Sortieren.Faktor, ich.Sortieren.mb) hatten sie nicht viel Erfolg bei der Verkürzung der Zeit bis zum Abschluss der Zählung.
Beiträge von Mitgliedern der Hive Community:
Schließlich kamen Mitglieder der Hive-Community zur Rettung und gaben verschiedene Einblicke, um die Probleme mit ihren aktuellen Hive-Implementierungen zu lösen:
- Sie erwähnten, dass die HDFS-Lesegeschwindigkeit ungefähr ist 60 MB / s verglichen mit 1 GB / s im Falle einer lokalen Festplatte, abhängig von der Netzwerkkapazität und der Arbeitslast auf NameNode.
- Die Mitglieder schlugen das vor 16 Mapper werden in ihrem aktuellen System benötigt, um mit der E / A-Leistung einer lokalen Nicht-Hadoop-Aufgabe übereinzustimmen.
- Sie schlugen auch vor, die zu reduzieren Split-Größe für jeden Mapper, um die Anzahl zu erhöhenvonMapper und damit mehr Parallelität.
- Schließlich forderten die Community-Mitglieder sie auf benutze count (1) anstatt sich zu beziehen Anzahl ( datapoint_id) . Dies liegt daran, dass im Fall von Zählung (1) keine Referenzspalte vorhanden ist und daher während der Zählung keine Dekomprimierung und Deserialisierung stattfindet.
Schließlich konnte die NASA ihren Hive-Cluster unter Berücksichtigung aller Vorschläge der Mitglieder der Hive-Community an ihre Erwartungen anpassen. Mit den oben genannten Systemkonfigurationen konnten sie Milliarden von Zeilen in nur 15 Sekunden abfragen.
Apache Hive Tutorial: Hive-Architektur und ihre Komponenten
Das folgende Bild beschreibt die Hive-Architektur und den Ablauf, in dem eine Abfrage gesendet wirdBienenstockund schließlich mit dem MapReduce-Framework verarbeitet:
Feige : Hive Tutorial - Hive Architektur
Wie im obigen Bild gezeigt, kann die Hive-Architektur in die folgenden Komponenten unterteilt werden:
- Hive-Kunden: Hive unterstützt Anwendungen, die in vielen Sprachen wie Java, C ++, Python usw. mit JDBC-, Thrift- und ODBC-Treibern geschrieben wurden. Daher kann man immer eine Hive-Client-Anwendung schreiben, die in einer Sprache ihrer Wahl geschrieben ist.
- Hive Services: Apache Hive bietet verschiedene Dienste wie CLI, Webinterface usw. zum Ausführen von Abfragen. Wir werden jeden von ihnen in Kürze in diesem Hive-Tutorial-Blog untersuchen.
- Verarbeitungsrahmen und Ressourcenmanagement: Im Inneren,Hive verwendet das Hadoop MapReduce-Framework als De-facto-Engine, um die Abfragen auszuführen. ist ein eigenständiges Thema und wird daher hier nicht behandelt.
- Verteilter Speicher: Da Hive auf Hadoop installiert ist, wird das zugrunde liegende HDFS für den verteilten Speicher verwendet. Sie können sich auf die beziehen HDFS-Blog um mehr darüber zu erfahren.
Lassen Sie uns nun die ersten beiden Hauptkomponenten der Hive-Architektur untersuchen:
1. Hive-Kunden:
Apache Hive unterstützt verschiedene Arten von Clientanwendungen zum Ausführen von Abfragen auf dem Hive. Diese Clients können in drei Typen eingeteilt werden:
- Sparsamkeitskunden: Da der Hive-Server auf Apache Thrift basiert, kann er die Anforderung aller Programmiersprachen bedienen, die Thrift unterstützen.
- JDBC-Clients: Mit Hive können Java-Anwendungen mithilfe des in der Klassenorganisation definierten JDBC-Treibers eine Verbindung herstellen.Apache.Hadoop.hive.jdbc.HiveDriver.
- ODBC-Clients: Mit dem Hive ODBC-Treiber können Anwendungen, die das ODBC-Protokoll unterstützen, eine Verbindung zu Hive herstellen. (Wie der JDBC-Treiber verwendet der ODBC-Treiber Thrift, um mit dem Hive-Server zu kommunizieren.)
2. Hive Services:
Hive bietet viele Dienste an, wie im obigen Bild gezeigt. Schauen wir uns jeden einzelnen an:
- Hive CLI (Befehlszeilenschnittstelle): Dies ist die vom Hive bereitgestellte Standard-Shell, in der Sie Ihre Hive-Abfragen und -Befehle direkt ausführen können.
- Apache Hive-Webschnittstellen: Neben der Befehlszeilenschnittstelle bietet Hive auch eine webbasierte Benutzeroberfläche zum Ausführen von Hive-Abfragen und -Befehlen.
- Hive Server: Der Hive-Server basiert auf Apache Thrift und wird daher auch als Thrift-Server bezeichnet, mit dem verschiedene Clients Anforderungen an Hive senden und das Endergebnis abrufen können.
- Apache Hive-Treiber: Es ist dafür verantwortlich, die von einem Client über die CLI, die Web-Benutzeroberfläche, Thrift, ODBC oder JDBC-Schnittstellen gesendeten Anfragen zu erhalten. Anschließend leitet der Treiber die Abfrage an den Compiler weiter, wo die Analyse, Typprüfung und semantische Analyse mithilfe des im Metastore vorhandenen Schemas erfolgt. Im nächsten Schritt wird ein optimierter logischer Plan in Form eines DAG (Directed Acyclic Graph) aus Aufgaben zur Kartenreduzierung und HDFS-Aufgaben erstellt. Schließlich führt die Ausführungsengine diese Aufgaben mithilfe von Hadoop in der Reihenfolge ihrer Abhängigkeiten aus.
- Metastore: Sie können Metastore denkenals zentrales Repository zum Speichern aller Hive-Metadateninformationen. Hive-Metadaten enthalten verschiedene Arten von Informationen wie die Struktur von Tabellen und Partitionenzusammen mit der Spalte, dem Spaltentyp, dem Serializer und dem Deserializer, die für den Lese- / Schreibvorgang für die in HDFS vorhandenen Daten erforderlich sind. Der Metastorebesteht aus zwei Grundeinheiten:
- Ein Dienst, der Metastore bereitstelltZugang zu anderenrHive-Dienste.
- Festplattenspeicher für die vom HDFS-Speicher getrennten Metadaten.
Lassen Sie uns nun die verschiedenen Möglichkeiten zur Implementierung des Hive-Metastores verstehenim nächsten Abschnitt dieses Hive-Tutorials.
Apache Hive Tutorial: Metastore-Konfiguration
Metastore speichert die Metadateninformationen mithilfe von RDBMS und einer Open-Source-ORM-Schicht (Object Relational Model) namens Data Nucleus, die die Objektdarstellung in ein relationales Schema konvertiert und umgekehrt. Der Grund für die Wahl von RDBMS anstelle von HDFS ist die Erzielung einer geringen Latenz. Wir können Metastore in den folgenden drei Konfigurationen implementieren:
1. Eingebetteter Metastore:
Sowohl der Metastore-Dienst als auch der Hive-Dienst werden standardmäßig in derselben JVM ausgeführt, wobei eine eingebettete Derby-Datenbankinstanz verwendet wird, in der Metadaten auf der lokalen Festplatte gespeichert sind. Dies wird als eingebettete Metastore-Konfiguration bezeichnet. In diesem Fall kann jeweils nur ein Benutzer eine Verbindung zur Metastore-Datenbank herstellen. Wenn Sie eine zweite Instanz des Hive-Treibers starten, wird eine Fehlermeldung angezeigt. Dies ist gut für Unit-Tests, aber nicht für die praktischen Lösungen.
2. Lokaler Metastore:
Diese Konfiguration ermöglicht es uns, mehrere Hive-Sitzungen durchzuführen, d. H. Mehrere Benutzer können die Metastore-Datenbank gleichzeitig verwenden. Dies wird durch die Verwendung einer JDBC-kompatiblen Datenbank wie MySQL erreicht, die in einer separaten JVM oder einem anderen Computer als dem Hive-Dienst und dem Metastore-Dienst ausgeführt wird, die in derselben JVM wie oben gezeigt ausgeführt werden. Im Allgemeinen ist die Implementierung eines MySQL-Servers als Metastore-Datenbank die beliebteste Option.
3. Remote Metastore:
In der Remote-Metastore-Konfiguration wird der Metastore-Dienst auf einer eigenen separaten JVM und nicht in der JVM des Hive-Dienstes ausgeführt. Andere Prozesse kommunizieren mit dem Metastore-Server über Thrift Network-APIs. In diesem Fall können Sie einen oder mehrere Metastore-Server haben, um mehr Verfügbarkeit zu gewährleisten.Der Hauptvorteil der Verwendung von Remote-Metastore besteht darin, dass Sie nicht für jeden Hive-Benutzer JDBC-Anmeldeinformationen freigeben müssen, um auf die Metastore-Datenbank zuzugreifen.
Apache Hive Tutorial: Datenmodell
Daten in Hive können auf granularer Ebene in drei Typen eingeteilt werden:
- Tabelle
- Partition
- Eimer
Tabellen:
Die Tabellen in Hive entsprechen den Tabellen in einer relationalen Datenbank. Sie können Filter-, Projekt-, Join- und Union-Vorgänge für sie ausführen. In Hive gibt es zwei Arten von Tabellen:
1. Verwaltete Tabelle:
Befehl:
CREATE TABLE (Spalte1 Datentyp, Spalte2 Datentyp)
LOAD DATA INPATH INTO Tabelle manage_table
Wie der Name schon sagt (verwaltete Tabelle), ist Hive für die Verwaltung der Daten einer verwalteten Tabelle verantwortlich. Mit anderen Worten, was ich mit 'Hive verwaltet die Daten' gemeint habe, ist, dass Sie die Daten aus einer in HDFS vorhandenen Datei in einen Hive laden Verwaltete Tabelle Wenn Sie einen DROP-Befehl eingeben, wird die Tabelle zusammen mit ihren Metadaten gelöscht. Also die Daten, die zum fallen gelassen werden verwaltete_Tabelle gibt es in HDFS nirgendwo mehr und Sie können es auf keinen Fall abrufen. Grundsätzlich verschieben Sie die Daten, wenn Sie den Befehl LOAD vom Speicherort der HDFS-Datei in das Hive-Warehouse-Verzeichnis ausgeben.
Hinweis: Der Standardpfad des Warehouse-Verzeichnisses ist / user / hive / warehouse. Die Daten einer Hive-Tabelle befinden sich in warehouse_directory /. Tabellenname (HDFS). Sie können den Pfad des Warehouse-Verzeichnisses auch im Konfigurationsparameter hive.metastore.warehouse.dir angeben, der in der Datei hive-site.xml vorhanden ist.
2. Externe Tabelle:
Befehl:
Was ist MVC in Java
EXTERNE TABELLE ERSTELLEN (Spalte1 Datentyp, Spalte2 Datentyp) LOCATION ‘’
LOAD DATA INPATH ‘’ IN TABLE
Zum externer Tisch , Hive ist nicht verantwortlich für die Verwaltung der Daten. In diesem Fall verschiebt Hive beim Ausgeben des Befehls LOAD die Daten in sein Warehouse-Verzeichnis. Anschließend erstellt Hive die Metadateninformationen für die externe Tabelle. Wenn Sie jetzt einen DROP-Befehl auf dem ausgeben externer Tisch Es werden nur Metadateninformationen zur externen Tabelle gelöscht. Daher können Sie die Daten dieser sehr externen Tabelle weiterhin mithilfe von HDFS-Befehlen aus dem Warehouse-Verzeichnis abrufen.
Partitionen:
Befehl:
CREATE TABLE Tabellenname (Spalte1 Datentyp, Spalte2 Datentyp) PARTITIONED BY (Partition1 Datentyp, Partition2 Datentyp & hellip.)
Hive organisiert Tabellen in Partitionen, um ähnliche Datentypen basierend auf einer Spalte oder einem Partitionsschlüssel zu gruppieren. Jede Tabelle kann einen oder mehrere Partitionsschlüssel enthalten, um eine bestimmte Partition zu identifizieren. Dies ermöglicht uns eine schnellere Abfrage von Datenschnitten.
Hinweis: Denken Sie daran, dass der häufigste Fehler beim Erstellen von Partitionen darin besteht, einen vorhandenen Spaltennamen als Partitionsspalte anzugeben. Dabei erhalten Sie eine Fehlermeldung: 'Fehler bei der semantischen Analyse: Spalte in Partitionierungsspalten wiederholt'.
Lassen Sie uns die Partition verstehen, indem wir ein Beispiel nehmen, in dem ich eine Tabelle student_details habe, die die Studenteninformationen einer Ingenieurschule wie student_id, Name, Abteilung, Jahr usw. enthält. Wenn ich nun eine Partitionierung basierend auf der Abteilungsspalte durchführe, die Informationen aller Studenten Die Zugehörigkeit zu einer bestimmten Abteilung wird zusammen in dieser Partition gespeichert. Physikalisch ist eine Partition nichts anderes als ein Unterverzeichnis im Tabellenverzeichnis.
Nehmen wir an, wir haben Daten für drei Abteilungen in unserer Tabelle student_details - CSE, ECE und Civil. Daher haben wir insgesamt drei Partitionen für jede der Abteilungen, wie in der Abbildung unten gezeigt. Und für jede Abteilung haben wir alle Daten zu dieser Abteilung in einem separaten Unterverzeichnis unter dem Hive-Tabellenverzeichnis. Beispielsweise werden alle Studentendaten zu CSE-Abteilungen in user / hive / warehouse / student_details / dept. = CSE gespeichert. Bei den Abfragen zu CSE-Schülern müssten also nur die in der CSE-Partition vorhandenen Daten durchsucht werden. Dies macht die Partitionierung sehr nützlich, da sie die Abfragelatenz nur durch Scannen verringert relevant partitionierte Daten anstelle des gesamten Datensatzes. Tatsächlich werden Sie in realen Implementierungen mit Hunderten von TB Daten arbeiten. Stellen Sie sich vor, Sie scannen diese riesige Datenmenge nach Abfragen, bei denen 95% Von Ihnen gescannte Daten waren für Ihre Anfrage nicht relevant.
Ich würde Ihnen vorschlagen, den Blog weiter zu lesen Hive-Befehle Hier finden Sie anhand eines Beispiels verschiedene Möglichkeiten zum Implementieren von Partitionen.
Eimer:
Befehle:
CREATE TABLE Tabellenname PARTITIONED BY (Partition1 Datentyp, Partition2 Datentyp & hellip.) CLUSTERED BY (Spaltenname1, Spaltenname2,…) SORTIERT NACH (Spaltenname [ASC | DESC],…)] INTO num_buckets BUCKETS
Jetzt können Sie jede Partition oder die nicht partitionierte Tabelle basierend auf der Hash-Funktion einer Spalte in der Tabelle in Buckets unterteilen. Tatsächlich ist jeder Bucket nur eine Datei im Partitionsverzeichnis oder im Tabellenverzeichnis (nicht partitionierte Tabelle). Wenn Sie die Partitionen in n Buckets unterteilt haben, befinden sich in jedem Partitionsverzeichnis n Dateien. Sie können beispielsweise das obige Bild sehen, in dem wir jede Partition in zwei Buckets unterteilt haben. Jede Partition, z. B. CSE, enthält zwei Dateien, in denen jeweils die Daten des CSE-Schülers gespeichert werden.
Wie verteilt Hive die Reihen in Eimer?
Nun, Hive bestimmt die Bucket-Nummer für eine Zeile mithilfe der folgenden Formel: hash_function (bucketing_column) modulo (num_of_buckets) . Hier, hash_function hängt vom Spaltendatentyp ab. Wenn Sie beispielsweise die Tabelle auf der Grundlage einer Spalte, z. B. user_id, des INT-Datentyps, aufteilen, lautet die Hash-Funktion: hash_function (user_id ) = ganzzahliger Wert von user_id . Angenommen, Sie haben zwei Buckets erstellt, dann ermittelt Hive die Zeilen, die in jeder Partition in Bucket 1 verschoben werden, indem Folgendes berechnet wird:Wert von user_id) modulo (2). Daher befinden sich in diesem Fall Zeilen mit user_id, die mit einer geraden Ganzzahl enden, in demselben Bucket, der jeder Partition entspricht. Die hash_function für andere Datentypen ist etwas komplex zu berechnen und tatsächlich ist sie für eine Zeichenfolge nicht einmal menschlich erkennbar.
Hinweis: Wenn Sie Apache Hive 0.x oder 1.x verwenden, müssen Sie den Befehl set hive.enforce.bucketing = true von Ihrem Hive-Terminal aus eingeben, bevor Sie das Bucketing durchführen. Auf diese Weise können Sie die richtige Anzahl von Reduzierungen festlegen, während Sie die Cluster-by-Klausel zum Bucketing einer Spalte verwenden. Falls Sie dies nicht getan haben, entspricht die Anzahl der in Ihrem Tabellenverzeichnis generierten Dateien möglicherweise nicht der Anzahl der Buckets. Alternativ können Sie auch die Anzahl der Reduzierer gleich der Anzahl der Buckets festlegen, indem Sie set mapred.reduce.task = num_bucket verwenden.
Warum brauchen wir Eimer?
Es gibt zwei Hauptgründe für das Bucketing einer Partition:
- ZU Map Side Join erfordert, dass die Daten, die zu einem eindeutigen Verknüpfungsschlüssel gehören, in derselben Partition vorhanden sind. Aber was ist mit den Fällen, in denen sich Ihr Partitionsschlüssel vom Join unterscheidet? In diesen Fällen können Sie daher einen Map-Side-Join ausführen, indem Sie die Tabelle mit dem Join-Schlüssel in Buckets umwandeln.
- Durch das Bucketing wird der Stichprobenprozess effizienter und wir können daher die Abfragezeit verkürzen.
Ich möchte diesen Hive-Tutorial-Blog hier abschließen. Ich bin mir ziemlich sicher, dass Sie nach dem Durchblättern dieses Hive-Tutorial-Blogs die Einfachheit von Apache Hive erkannt hätten. Seitdem habt ihr alle Grundlagen von Hive gelerntEs ist höchste Zeit, praktische Erfahrungen mit Apache Hive zu sammeln. Schauen Sie sich also das nächste Blog in dieser Hive Tutorial-Blogserie an, in der es um die Installation von Hive geht, und beginnen Sie mit der Arbeit an Apache Hive.
Nachdem Sie Apache Hive und seine Funktionen verstanden haben, lesen Sie die von Edureka, einem vertrauenswürdigen Online-Lernunternehmen mit einem Netzwerk von mehr als 250.000 zufriedenen Lernenden auf der ganzen Welt. Der Edureka Big Data Hadoop-Zertifizierungskurs hilft Lernenden, Experten für HDFS, Garn, MapReduce, Schwein, Bienenstock, HBase, Oozie, Flume und Sqoop zu werden. Dabei werden Anwendungsfälle in Echtzeit in den Bereichen Einzelhandel, soziale Medien, Luftfahrt, Tourismus und Finanzen verwendet.
Hast du eine Frage an uns? Bitte erwähnen Sie es in den Kommentaren und wir werden uns bei Ihnen melden.