
Eine der attraktivsten Funktionen des Hadoop-Frameworks ist seine Nutzung von Standardhardware . Dies führt jedoch zu häufigen DataNode-Abstürzen in einem Hadoop-Cluster. Ein weiteres auffälliges Merkmal von Hadoop Framework ist das einfache Skalierung entsprechend dem schnellen Wachstum des Datenvolumens . Aus diesen beiden Gründen besteht eine der häufigsten Aufgaben eines Hadoop-Administrators darin, Kommission (Hinzufügen) und Stilllegung (Entfernen) Datenknoten in einem Hadoop-Cluster.
pl sql Entwickler-Tutorial für Anfänger
Inbetriebnahme- und Stilllegungsknoten in einem Hadoop-Cluster:
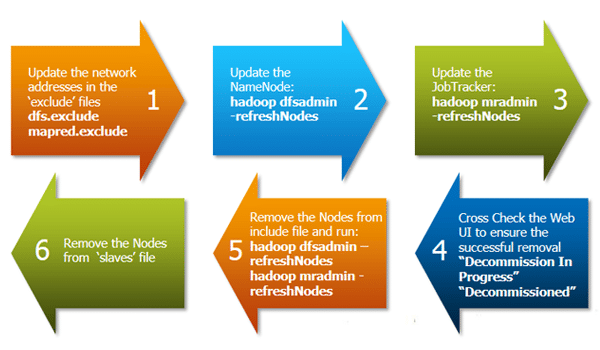
Das obige Diagramm zeigt einen schrittweisen Prozess zum Außerbetriebnehmen eines DataNode im Cluster.
Die erste Aufgabe besteht darin, die ausschließen ‘Dateien für beide HDFS (hdfs-site.xml) und Karte verkleinern (mapred-site.xml).
Die Ausschlussdatei:
- für Jobtracker enthält die Liste der Hosts, die vom Jobtracker ausgeschlossen werden sollen. Wenn der Wert leer ist, werden keine Hosts ausgeschlossen.
- für Namenode enthält eine Liste von Hosts, die keine Verbindung zum Namenode herstellen dürfen.
Hier ist die Beispielkonfiguration für die Ausschlussdatei in hdfs-site.xml und mapred-site.xml:
hdfs-site.xml
dfs.hosts.exclude
/ home / hadoop / schließt aus
wahr
mapred-site.xml
mapred.hosts.exclude
/ home / hadoop / schließt aus
wahr
Hinweis: Der vollständige Pfadname der Dateien muss angegeben werden.
Ebenso haben wir die Include-Dateien:
- für Jobtracker Enthält die Liste der Knoten, die eine Verbindung zum JobTracker herstellen können. Wenn der Wert leer ist, sind alle Hosts zulässig.
- für Namenode enthält eine Liste von Hosts, die eine Verbindung zum Namenode herstellen dürfen. Wenn der Wert leer ist, sind alle Hosts zulässig.
Das ' dfsadmin ' und ' mradmin ’Befehle aktualisieren die Konfiguration mit den Änderungen, um sie auf den neuen Knoten aufmerksam zu machen.
Das ' Sklaven Die Datei auf dem Master-Server enthält die Liste aller Datenknoten. Dies muss auch aktualisiert werden, um sicherzustellen, dass beim zukünftigen Start / Stopp des Hadoop-Daemons Probleme auftreten.
Der wichtige Schritt bei der Datenknoten-Provisionierung ist die Ausführung des Cluster Balancer.
> Hadoop Balancer - Schwelle 40
Balancer versucht, ein Gleichgewicht zwischen Datenknoten bis zu einem bestimmten Schwellenwert herzustellen, indem Blockdaten von älteren Knoten auf neu in Betrieb genommene Knoten kopiert werden.
So können Sie also tun - Inbetriebnahme und Stilllegung Knoten in einem Hadoop-Cluster.
Hast du eine Frage an uns? Bitte erwähnen Sie es in den Kommentaren und wir werden uns bei Ihnen melden.
Verwandte Links: