
Der Zweck von Informatica ETL besteht darin, den Benutzern nicht nur einen Prozess zum Extrahieren von Daten aus Quellsystemen und zum Einbringen in das Data Warehouse bereitzustellen, sondern den Benutzern auch eine gemeinsame Plattform zur Integration ihrer Daten von verschiedenen Plattformen und Anwendungen bereitzustellen.Dies hat zu einem Anstieg der Nachfrage nach geführt .Bevor wir über Informatica ETL sprechen, lassen Sie uns zunächst verstehen, warum wir ETL benötigen.
Warum brauchen wir ETL?
Jedes Unternehmenin diesen Tagen müssen große Datenmengen aus verschiedenen Quellen verarbeiten. Diese Daten müssen verarbeitet werden, um aufschlussreiche Informationen für Geschäftsentscheidungen zu erhalten. Solche Daten haben jedoch häufig folgende Herausforderungen:
- Große Unternehmen generieren viele Daten und solch große Datenmengen können in jedem Format vorliegen. Sie wären in mehreren Datenbanken und vielen unstrukturierten Dateien verfügbar.
- Diese Daten müssen gesammelt, kombiniert, verglichen und als nahtloses Ganzes verwendet werden. Die verschiedenen Datenbanken kommunizieren jedoch nicht gut!
- Viele Organisationen haben Schnittstellen zwischen diesen Datenbanken implementiert, standen jedoch vor folgenden Herausforderungen:
- Jedes Datenbankpaar benötigt eine eindeutige Schnittstelle.
- Wenn Sie eine Datenbank ändern, müssen möglicherweise viele Schnittstellen aktualisiert werden.
Unten sehen Sie die verschiedenen Datenbanken einer Organisation und ihre Interaktionen:
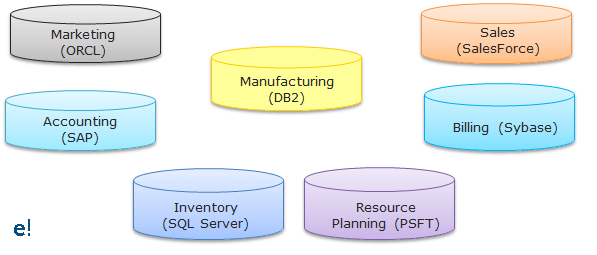
Verschiedene Datenbanken, die von verschiedenen Abteilungen einer Organisation verwendet werden
Unterschiedliche Interaktionen der Datenbanken in einer Organisation
Wie oben dargestellt, kann eine Organisation verschiedene Datenbanken in ihren verschiedenen Abteilungen haben, und die Interaktion zwischen ihnen wird schwierig zu implementieren, da verschiedene Interaktionsschnittstellen für sie erstellt werden müssen. Um diese Herausforderungen zu bewältigen, ist die bestmögliche Lösung die Verwendung der Konzepte von Datenintegration Dadurch könnten Daten aus verschiedenen Datenbanken und Formaten miteinander kommunizieren. Die folgende Abbildung hilft uns zu verstehen, wie das Datenintegrationstool zu einer gemeinsamen Schnittstelle für die Kommunikation zwischen den verschiedenen Datenbanken wird.
Verschiedene über Datenintegration verbundene Datenbanken
Für die Datenintegration stehen jedoch verschiedene Prozesse zur Verfügung. Unter diesen Prozessen ist ETL der optimalste, effizienteste und zuverlässigste Prozess. Über ETL kann der Benutzer nicht nur Daten aus verschiedenen Quellen einbringen, sondern auch die verschiedenen Vorgänge für die Daten ausführen, bevor diese Daten auf dem Endziel gespeichert werden.
Informatica PowerCenter ist unter den verschiedenen auf dem Markt verfügbaren ETL-Tools die marktführende Datenintegrationsplattform des Marktes. Informatica PowerCenter inter wurde auf fast 500.000 Kombinationen von Plattformen und Anwendungen getestet und arbeitet mit einem möglichst breiten Spektrum unterschiedlicher Standards, Systeme und Anwendungen. Lassen Sie uns nun die Schritte des Informatica ETL-Prozesses verstehen.
Informatik ETL | Informatica Architektur | Informatica PowerCenter Tutorial | Edureka
Dieses Tutorial zu Edureka Informatica hilft Ihnen, die Grundlagen von ETL mit Informatica Powercenter im Detail zu verstehen.
Schritte im Informatica ETL-Prozess:
Bevor wir zu den verschiedenen Schritten in Informatica ETL übergehen, geben wir Ihnen einen Überblick über ETL. In ETL werden bei der Extraktion Daten aus homogenen oder heterogenen Datenquellen extrahiert. Bei der Transformation werden die Daten zum Speichern im richtigen Format oder in der richtigen Struktur zum Abfragen und Analysieren transformiert. Beim Laden werden die Daten in die endgültige Zieldatenbank geladen. Betriebsdatenspeicher, Data Mart oder Data Warehouse. Das folgende Bild hilft Ihnen zu verstehen, wie der Informatica ETL-Prozess abläuft.
ETL-Prozessübersicht
Wie oben dargestellt, kann Informatica PowerCenter Daten aus verschiedenen Quellen laden und in einem einzigen Data Warehouse speichern. Betrachten wir nun die Schritte des Informatica ETL-Prozesses.
Der Informatica ETL-Prozess besteht hauptsächlich aus 4 Schritten. Lassen Sie uns diese nun genauer verstehen:
- Extrahieren oder erfassen
- Schrubben oder reinigen
- Verwandeln
- Laden und Indexieren
1. Extrahieren oder erfassen: Wie in der Abbildung unten dargestellt, ist das Erfassen oder Extrahieren der erste Schritt des Informatica ETL-Prozesses.Hierbei wird ein Snapshot der ausgewählten Teilmenge von Daten aus der Quelle abgerufen, der in das Data Warehouse geladen werden muss. Ein Snapshot ist eine schreibgeschützte statische Ansicht der Daten in der Datenbank. Es gibt zwei Arten des Extraktionsprozesses:
- Vollständiger Auszug: Die Daten werden vollständig aus dem Quellsystem extrahiert und es ist nicht erforderlich, Änderungen an der Datenquelle seit der letzten erfolgreichen Extraktion zu verfolgen.
- Inkrementeller Extrakt: Dadurch werden nur Änderungen erfasst, die seit dem letzten vollständigen Extrakt aufgetreten sind.
Phase 1: Extrahieren oder Erfassen
2. Schrubben oder reinigen: Dies ist der Prozess des Bereinigens der von der Quelle kommenden Daten unter Verwendung verschiedener Mustererkennungs- und KI-Techniken, um die Qualität der übertragenen Daten zu verbessern. Normalerweise sind die Fehler wie Rechtschreibfehler, fehlerhafte Daten, falsche Feldverwendung, nicht übereinstimmende Adressen, fehlende Daten, doppelte Daten, Inkonsistenzenhervorgehoben und dann korrigiert oder entferntin diesem Schritt. In diesem Schritt werden auch Vorgänge wie Dekodieren, Neuformatieren, Zeitstempeln, Konvertieren, Schlüsselgenerieren, Zusammenführen, Fehlererkennung / -protokollierung und Suchen fehlender Daten ausgeführt. Wie in der Abbildung unten dargestellt, ist dies der zweite Schritt des Informatica ETL-Prozesses.
Phase 2: Bereinigen oder Bereinigen von Daten
3. Transformieren: Wie in der Abbildung unten dargestellt, ist dies der dritte und wichtigste Schritt des Informatica ETL-Prozesses. Bei Transformationen werden Daten aus dem Format des Quellsystems in das Grundgerüst von Data Warehouse konvertiert. Eine Transformation wird im Wesentlichen verwendet, um eine Reihe von Regeln darzustellen, die den Datenfluss definieren und wie die Daten in die Ziele geladen werden. Weitere Informationen zur Transformation finden Sie unter Transformationen in der Informatik Blog.
Phase 3: Transformation
4. Laden und Indexieren: Dies ist der letzte Schritt des Informatica ETL-Prozesses (siehe Abbildung unten). In dieser Phase platzieren wir die transformierten Daten im Warehouse und erstellen Indizes für die Daten. Basierend auf dem Ladevorgang stehen zwei Haupttypen des Datenladens zur Verfügung:
- Volllast oder Massenlast ::Der Datenladevorgang, wenn wir ihn zum ersten Mal ausführen. Der Job extrahiert das gesamte Datenvolumen aus einer Quelltabelle und wird nach Anwendung der erforderlichen Transformationen in das Zieldatenlager geladen. Es wird ein einmaliger Job ausgeführt, nachdem Änderungen allein als Teil eines inkrementellen Extrakts erfasst wurden.
- Inkrementelle Last oder Aktualisierungslast :: Die geänderten Daten allein werden im Ziel aktualisiert, gefolgt von der Volllast. Die Änderungen werden erfasst, indem das erstellte oder geänderte Datum mit dem letzten Ausführungsdatum des Jobs verglichen wird.Die geänderten Daten allein werden aus der Quelle extrahiert und im Ziel aktualisiert, ohne die vorhandenen Daten zu beeinträchtigen.
Phase 4: Laden und Indexieren
Wenn Sie den Informatica ETL-Prozess verstanden haben, können wir jetzt besser verstehen, warum Informatica in solchen Fällen die beste Lösung ist.
Funktionen von Informatica ETL:
Informatica hat uns für alle Datenintegrations- und ETL-Vorgänge zur Verfügung gestellt Informatica PowerCenter . Lassen Sie uns nun einige wichtige Funktionen von Informatica ETL sehen:
- Bietet die Möglichkeit, eine große Anzahl von Transformationsregeln mit einer GUI anzugeben.
- Generieren Sie Programme zum Transformieren von Daten.
- Behandeln Sie mehrere Datenquellen.
- Unterstützt Datenextraktion, Bereinigung, Aggregation, Reorganisation, Transformation und Ladevorgänge.
- Generiert automatisch Programme zur Datenextraktion.
- Hochgeschwindigkeitsladen von Zieldatenlagern.
Im Folgenden sind einige der typischen Szenarien aufgeführt, in denen Informatica PowerCenter verwendet wird:
- Datenmigration:
Ein Unternehmen hat einen neuen Kreditorenbuchhaltungsantrag für seine Buchhaltungsabteilung gekauft. PowerCenter kann die vorhandenen Kontodaten in die neue Anwendung verschieben. Die folgende Abbildung hilft Ihnen zu verstehen, wie Sie Informatica PowerCenter für die Datenmigration verwenden können. Informatica PowerCenter kann die Datenherkunft für Steuer-, Buchhaltungs- und andere gesetzlich vorgeschriebene Zwecke während des Datenmigrationsprozesses problemlos beibehalten.
Datenmigration von einer älteren Buchhaltungsanwendung zu einer neuen Anwendung
- Anwendungsintegration:
Nehmen wir an, Unternehmen A kauft Unternehmen B. Um die Vorteile der Konsolidierung zu erzielen, muss das Abrechnungssystem von Unternehmen B in das Abrechnungssystem von Unternehmen A integriert werden, was mit Informatica PowerCenter problemlos möglich ist. Die folgende Abbildung hilft Ihnen zu verstehen, wie Sie Informatica PowerCenter für die Integration von Anwendungen zwischen den Unternehmen verwenden können.
Anwendung zwischen Unternehmen integrieren
- Data Warehousing
Typische Aktionen, die in Data Warehouses erforderlich sind, sind:
- Kombinieren von Informationen aus vielen Quellen zur Analyse.
- Verschieben von Daten aus vielen Datenbanken in das Data Warehouse.
Alle oben genannten typischen Fälle können problemlos mit Informatica PowerCenter ausgeführt werden. Unten sehen Sie, dass Informatica PowerCenter verwendet wird, um die Daten aus verschiedenen Arten von Datenbanken wie Oracle, SalesForce usw. zu kombinieren und in ein von Informatica PowerCenter erstelltes gemeinsames Data Warehouse zu bringen.
Daten Aus verschiedenen Datenbanken, die in ein gemeinsames Data Warehouse integriert sind
- Middleware
Angenommen, eine Einzelhandelsorganisation verwendet SAP R3 für ihre Einzelhandelsanwendungen und SAP BW als Data Warehouse. Eine direkte Kommunikation zwischen diesen beiden Anwendungen ist aufgrund fehlender Kommunikationsschnittstelle nicht möglich. Informatica PowerCenter kann jedoch als Middleware zwischen diesen beiden Anwendungen verwendet werden. In der Abbildung unten sehen Sie die Architektur, wie Informatica PowerCenter als Middleware zwischen SAP R / 3 und SAP BW verwendet wird. Die Anwendungen aus SAP R / 3 übertragen ihre Daten an das ABAP-Framework, das sie dann an das überträgtSAP Point of Sale (POS) und SAPBills of Services (BOS). Informatica PowerCenter unterstützt die Übertragung von Daten von diesen Services zum SAP Business Warehouse (BW).
Informatica PowerCenter als Middleware in der SAP Retail Architecture
Sie haben zwar einige wichtige Funktionen und typische Szenarien von Informatica ETL gesehen, aber ich hoffe, Sie verstehen, warum Informatica PowerCenter das beste Tool für den ETL-Prozess ist. Lassen Sie uns nun einen Anwendungsfall von Informatica ETL sehen.
Anwendungsfall: Verbinden von zwei Tabellen, um eine einzelne detaillierte Tabelle zu erhalten
Angenommen, Sie möchten Ihren Mitarbeitern einen abteilungsweisen Transport anbieten, da sich die Abteilungen an verschiedenen Standorten befinden. Dazu müssen Sie zunächst wissen, zu welcher Abteilung jeder Mitarbeiter gehört und wo sich die Abteilung befindet. Die Details der Mitarbeiter werden jedoch in verschiedenen Tabellen gespeichert, und Sie müssen die Details der Abteilung mit einer vorhandenen Datenbank mit den Details aller Mitarbeiter verknüpfen. Zu diesem Zweck laden wir zuerst beide Tabellen in Informatica PowerCenter, führen eine Quellqualifizierungstransformation für die Daten durch und laden schließlich die Details in die Zieldatenbank.Lasst uns anfangen:
Schritt 1 :: Öffnen Sie PowerCenter Designer.
Unten finden Sie die Startseite von Informatica PowerCenter Designer.
Stellen wir jetzt eine Verbindung zum Repository her. Falls Sie Ihre Repositorys nicht konfiguriert haben oder Probleme haben, können Sie unsere überprüfen Blog.
Schritt 2: Klicken Sie mit der rechten Maustaste auf Ihr Repository und wählen Sie die Verbindungsoption.
Wenn Sie auf die Verbindungsoption klicken, werden Sie im folgenden Bildschirm aufgefordert, Ihren Repository-Benutzernamen und Ihr Kennwort einzugeben.
Sobald Sie eine Verbindung zu Ihrem Repository hergestellt haben, müssen Sie Ihren Arbeitsordner wie folgt öffnen:
Sie werden aufgefordert, nach dem Namen Ihres Mappings zu fragen. Geben Sie den Namen Ihres Mappings an und klicken Sie auf OK (ich habe es als benannt m-MITARBEITER ).
Schritt 3: Laden wir nun die Tabellen aus der Datenbank. Stellen Sie zunächst eine Verbindung zur Datenbank her. Wählen Sie dazu die Registerkarte Quellen und die Option Aus Datenbank importieren (siehe unten):
Wenn Sie auf Aus Datenbank importieren klicken, wird der folgende Bildschirm angezeigt, in dem Sie nach den Details Ihrer Datenbank sowie deren Benutzername und Kennwort für die Verbindung gefragt werden (ich verwende die Oracle-Datenbank und den HR-Benutzer).
Klicken Sie auf Verbinden, um eine Verbindung zu Ihrer Datenbank herzustellen.
Schritt 4: Da möchte ich mich dem anschließen ANGESTELLTE und ABTEILUNG Tabellen werde ich sie auswählen und auf OK klicken.
Die Quellen werden in Ihrem Mapping Designer-Arbeitsbereich angezeigt (siehe unten).
Schritt 5: Laden Sie auf ähnliche Weise die Zieltabelle in die Zuordnung.
Schritt 6: Lassen Sie uns nun das Quellqualifikationsmerkmal und die Zieltabelle verknüpfen. Klicken Sie mit der rechten Maustaste auf eine leere Stelle im Arbeitsbereich und wählen Sie Autolink aus (siehe unten):
Unten finden Sie die von Autolink verknüpfte Zuordnung.
Schritt 7: Da wir beide Tabellen mit dem Quellqualifizierer verknüpfen müssen, wählen Sie die Spalten der Abteilungstabelle aus und legen Sie sie wie unten gezeigt im Quellqualifizierer ab:
__init __ (selbst)
Legen Sie die Spaltenwerte im Quellqualifikator ab SQ_EMPLOYEES .
Unten finden Sie den aktualisierten Quellqualifizierer.
Schritt 8: Doppelklicken Sie auf Source Qualifier, um die Umwandlung zu bearbeiten.
Das Popup 'Bearbeitung bearbeiten' wird angezeigt (siehe unten). Klicken Sie auf die Registerkarte Eigenschaften.
Schritt 9: Klicken Sie auf der Registerkarte Eigenschaften auf das Feld Wert in der Zeile UserDefined Join.
Sie erhalten folgenden SQL-Editor:
Schritt 10: Eingeben EMPLOYEES.DEPARTMENT_ID = DEPARTMENT.DEPARTMENT_ID als Bedingung, um beide Tabellen im SQL-Feld zu verbinden und auf OK zu klicken.
Schritt 11: Klicken Sie nun auf die Zeile SQL Query, um das SQL für den Beitritt zu generieren (siehe unten):
Sie erhalten den folgenden SQL-Editor: Klicken Sie auf die Option SQL generieren.
Die folgende SQL wird für die Bedingung generiert, die wir im vorherigen Schritt angegeben haben. Klicken Sie auf OK.
Schritt 12: Klicken Sie auf Übernehmen und auf OK.
Unten finden Sie die vollständige Zuordnung.
Wir haben den Entwurf abgeschlossen, wie die Daten von der Quelle zum Ziel übertragen werden müssen. Die eigentliche Datenübertragung steht jedoch noch aus und dafür müssen wir das PowerCenter Workflow Design verwenden. Die Ausführung des Workflows führt zur Übertragung von Daten von der Quelle zum Ziel. Weitere Informationen zum Workflow finden Sie in unserem Informatica Tutorial: Workflow Blog
Schritt 13: L.Starten Sie jetzt den Workflow Manager, indem Sie auf das W-Symbol klicken (siehe unten):
Unten finden Sie die Homepage des Workflow-Designers.
Schritt 14: Lassen Sie uns jetzt einen neuen Workflow für unser Mapping erstellen. Klicken Sie auf die Registerkarte Workflow und wählen Sie Option erstellen.
Sie erhalten das folgende Popup. Geben Sie den Namen Ihres Workflows an und klicken Sie auf OK.
Schritt 15 : Sobald ein Workflow erstellt wurde, wird das Startsymbol im Workflow Manager-Arbeitsbereich angezeigt.
Fügen Sie dem Arbeitsbereich nun eine neue Sitzung hinzu, indem Sie auf das Sitzungssymbol und dann auf den Arbeitsbereich klicken:
Klicken Sie auf den Arbeitsbereich, um das Sitzungssymbol zu platzieren.
Schritt 16: Während Sie die Sitzung hinzufügen, müssen Sie die Zuordnung auswählen, die Sie in den obigen Schritten erstellt und gespeichert haben. (Ich hatte es als m-MITARBEITER gespeichert).
Unten finden Sie den Arbeitsbereich nach dem Hinzufügen des Sitzungssymbols.
Schritt 17 : Nachdem Sie eine neue Sitzung erstellt haben, müssen Sie sie mit der Startaufgabe verknüpfen. Wir können dies tun, indem wir auf das Symbol 'Aufgabe verknüpfen' klicken (siehe unten):
Klicken Sie zuerst auf das Symbol Start und dann auf das Symbol Sitzung, um einen Link herzustellen.
Unten finden Sie einen verbundenen Workflow.
Schritt 18: Nachdem wir das Design fertiggestellt haben, starten wir den Workflow. Klicken Sie auf die Registerkarte Workflow und wählen Sie die Option Workflow starten.
Workflow Manager startet Workflow Monitor.
Schritt 19 : Sobald wir den Workflow starten, wird der Workflow Manager automatisch gestartetundMit dieser Option können Sie die Ausführung Ihres Workflows überwachen. Unten sehen Sie, dass der Workflow-Monitor den Status Ihres Workflows anzeigt.
Schritt 20: Um den Status des Workflows zu überprüfen, klicken Sie mit der rechten Maustaste auf den Workflow und wählen Sie 'Run-Eigenschaften abrufen' (siehe unten):
Wählen Sie die Registerkarte Quell- / Zielstatistik.
Unten sehen Sie die Anzahl der Zeilen, die nach der Transformation zwischen Quelle und Ziel übertragen wurden.
Sie können Ihr Ergebnis auch überprüfen, indem Sie Ihre Zieltabelle überprüfen (siehe unten).
Ich hoffe, dieser Informatica ETL-Blog war hilfreich, um Ihr Verständnis für die Konzepte von ETL mithilfe von Informatica zu erweitern, und hat genug Interesse geweckt, damit Sie mehr über Informatica erfahren können.
Wenn Sie diesen Blog hilfreich fanden, können Sie auch unsere Informatica Tutorial-Blogserie lesen , Informatica-Lernprogramm: Informatica „Inside Out“ verstehen und Informatica-Transformationen: Das Herz und die Seele von Informatica PowerCenter . Wenn Sie Details zur Informatica-Zertifizierung suchen, können Sie unseren Blog besuchen Informatica-Zertifizierung: Alles, was Sie wissen müssen .
Wenn Sie sich bereits für eine Karriere bei Informatica entschieden haben, würde ich Ihnen empfehlen, sich unsere anzuschauen Kursseite. Das Informatica-Zertifizierungs-Training bei Edureka macht Sie durch Live-Sitzungen unter Anleitung von Lehrern und praktische Schulungen anhand realer Anwendungsfälle zu einem Experten für Informatica.