
Pig-Programmierung: Erstellen Sie Ihr erstes Apache Pig-Skript
In unserer Jetzt lernen wir, wie man ein Apache Pig-Skript erstellt. Apache Pig-Skripte werden verwendet, um eine Reihe von Apache Pig-Befehlen gemeinsam auszuführen. Dies hilft dabei, den Zeit- und Arbeitsaufwand für das manuelle Schreiben und Ausführen jedes Befehls zu reduzieren, während Sie dies in der Pig-Programmierung tun.Es ist auch ein wesentlicher Bestandteil der .Dieser Blog ist eine Schritt-für-Schritt-Anleitung, mit der Sie Ihr erstes Apache Pig-Skript erstellen können.
Ausführungsmodi für Apache Pig-Skripte
Lokalbetrieb : Im 'lokalen Modus' können Sie das Pig-Skript im lokalen Dateisystem ausführen. In diesem Fall müssen Sie die Daten nicht im Hadoop HDFS-Dateisystem speichern, sondern können mit den im lokalen Dateisystem selbst gespeicherten Daten arbeiten.
MapReduce-Modus : Im MapReduce-Modus müssen die Daten im HDFS-Dateisystem gespeichert werden, und Sie können die Daten mithilfe eines Pig-Skripts verarbeiten.
Apache Pig Script im MapReduce-Modus
Angenommen, unsere Aufgabe besteht darin, Daten aus einer Datendatei zu lesen und den erforderlichen Inhalt auf dem Terminal als Ausgabe anzuzeigen.
Die Beispieldatendatei enthält folgende Daten:
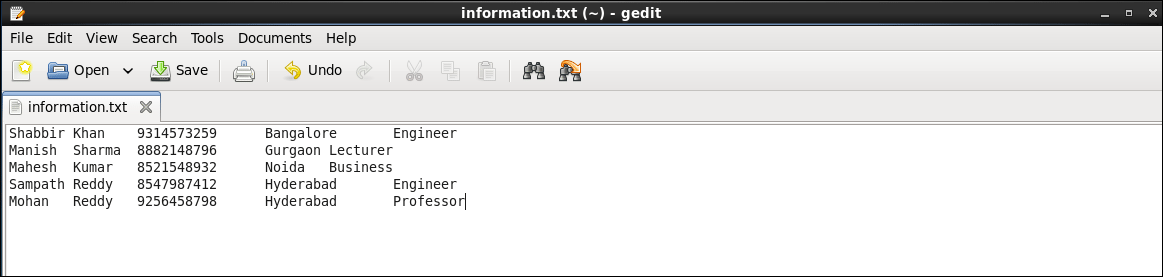
Speichern Sie die Textdatei unter dem Namen 'information.txt'.
Die Beispieldatendatei enthält fünf Spalten Vorname , Familienname, Nachname , MobileNo , Stadt , und Beruf getrennt durch Tab-Taste . Unsere Aufgabe ist es, den Inhalt dieser Datei aus dem HDFS zu lesen und alle Spalten dieser Datensätze anzuzeigen.
Client-Server-Socket-Programmierung in Java
Um diese Daten mit Pig zu verarbeiten, sollte diese Datei in Apache Hadoop HDFS vorhanden sein.
Befehl : hadoop fs –copyFromLocal /home/edureka/information.txt / edureka
Schritt 1: Ein Pig-Skript schreiben
Erstellen und öffnen Sie eine Apache Pig-Skriptdatei in einem Editor (z. B. gedit).
Befehl : sudo gedit /home/edureka/output.pig
Mit diesem Befehl wird eine Datei 'output.pig' im Ausgangsverzeichnis des edureka-Benutzers erstellt.
Schreiben wir einige PIG-Befehle in die Datei output.pig.
A = LOAD '/edureka/information.txt' mit PigStorage ('') als (FName: chararray, LName: chararray, MobileNo: chararray, Stadt: chararray, Beruf: chararray) B = FOREACH A generiere FName, MobileNo, Beruf DUMP B.Speichern und schließen Sie die Datei.
- Der erste Befehl lädt die Datei 'information.txt' in die Variable A mit indirektem Schema (FName, LName, MobileNo, City, Profession).
- Der zweite Befehl lädt die erforderlichen Daten von Variable A in Variable B.
- In der dritten Zeile wird der Inhalt der Variablen B auf dem Terminal / der Konsole angezeigt.
Schritt 2: Führen Sie das Apache Pig-Skript aus
Was ist Hashmap und Hashtable in Java
Führen Sie den folgenden Befehl aus, um das Pig-Skript im HDFS-Modus auszuführen:
Befehl : pig /home/edureka/output.pig
Überprüfen Sie nach Abschluss der Ausführung das Ergebnis. Diese folgenden Bilder zeigen die Ergebnisse und ihre Zwischenabbildung und reduzieren Funktionen.
Das folgende Bild zeigt, dass das Skript erfolgreich ausgeführt wurde.
Das folgende Bild zeigt das Ergebnis unseres Skripts.
Herzlichen Glückwunsch zur erfolgreichen Ausführung Ihres ersten Apache Pig-Skripts!
Jetzt wissen Sie, wie Sie ein Apache Pig-Skript erstellen und ausführen. Daher unser nächster Blog in wird behandeln, wie es geht Erstellen Sie UDF (User Defined Functions) in Apache Pig und führen Sie es im MapReduce / HDFS-Modus aus.
Nachdem Sie das Apache Pig-Skript erstellt und ausgeführt haben, lesen Sie das von Edureka, einem vertrauenswürdigen Online-Lernunternehmen mit einem Netzwerk von mehr als 250.000 zufriedenen Lernenden auf der ganzen Welt. Der Edureka Big Data Hadoop-Zertifizierungskurs hilft Lernenden, Experten für HDFS, Garn, MapReduce, Schwein, Bienenstock, HBase, Oozie, Flume und Sqoop zu werden. Dabei werden Anwendungsfälle in Echtzeit in den Bereichen Einzelhandel, soziale Medien, Luftfahrt, Tourismus und Finanzen verwendet.
Hast du eine Frage an uns? Bitte erwähnen Sie es in den Kommentaren und wir werden uns bei Ihnen melden.