
Bei so vielen Fortschritten in den Bereichen Gesundheitswesen, Marketing, Wirtschaft usw. ist es notwendig geworden, fortschrittlichere und komplexere Entwicklungen zu entwickeln . Die Förderung des maschinellen Lernens ist eine solche Technik, mit der komplexe, datengesteuerte, reale Probleme gelöst werden können. Dieser Blog konzentriert sich ausschließlich auf die Funktionsweise von Boosting Machine Learning und darauf, wie es implementiert werden kann, um die Effizienz von Modellen für maschinelles Lernen zu steigern.
Um detaillierte Kenntnisse über künstliche Intelligenz und maschinelles Lernen zu erhalten, können Sie sich live anmelden von Edureka mit 24/7 Support und lebenslangem Zugriff.
Hier ist eine Liste der Themen, die behandelt werden in diesem Blog:
- Warum wird Boosting verwendet?
- Was ist Boosting?
- Wie funktioniert der Boosting-Algorithmus?
- Arten der Auffrischung
- Demo
Warum wird Boosting verwendet?
Um verschlungene Probleme zu lösen, benötigen wir fortgeschrittenere Techniken. Nehmen wir an, Sie wurden anhand eines Datensatzes von Bildern mit Bildern von Katzen und Hunden gebeten, ein Modell zu erstellen, mit dem diese Bilder in zwei separate Klassen eingeteilt werden können. Wie bei jeder anderen Person werden Sie zunächst die Bilder anhand der folgenden Regeln identifizieren:
Das Bild hat spitze Ohren: Cat
Das Bild hat katzenförmige Augen: Katze
Das Bild hat größere Glieder: Hund
Das Bild hat Krallen geschärft: Cat
Das Bild hat eine breitere Mundstruktur: Hund
All diese Regeln helfen uns zu identifizieren, ob ein Bild ein Hund oder eine Katze ist. Wenn wir jedoch ein Bild anhand einer individuellen (einzelnen) Regel klassifizieren würden, wäre die Vorhersage fehlerhaft. Jede dieser Regeln wird einzeln als schwache Lernende bezeichnet, da diese Regeln nicht stark genug sind, um ein Bild als Katze oder Hund zu klassifizieren.
Um sicherzustellen, dass unsere Vorhersage genauer ist, können wir daher die Vorhersage jedes dieser schwachen Lernenden unter Verwendung der Mehrheitsregel oder des gewichteten Durchschnitts kombinieren. Dies macht ein starkes Lernmodell.
Im obigen Beispiel haben wir 5 schwache Lernende definiert und die Mehrheit dieser Regeln (d. H. 3 von 5 Lernenden sagen das Bild als Katze voraus) gibt uns die Vorhersage dass das Bild eine Katze ist. Daher ist unsere endgültige Ausgabe eine Katze.
Das bringt uns also zu der Frage:
Was ist Boosting?
Boosting ist eine Ensemble-Lerntechnik, die eine Reihe von Algorithmen für maschinelles Lernen verwendet, um schwache Lernende in starke Lernende umzuwandeln und so die Genauigkeit des Modells zu erhöhen.
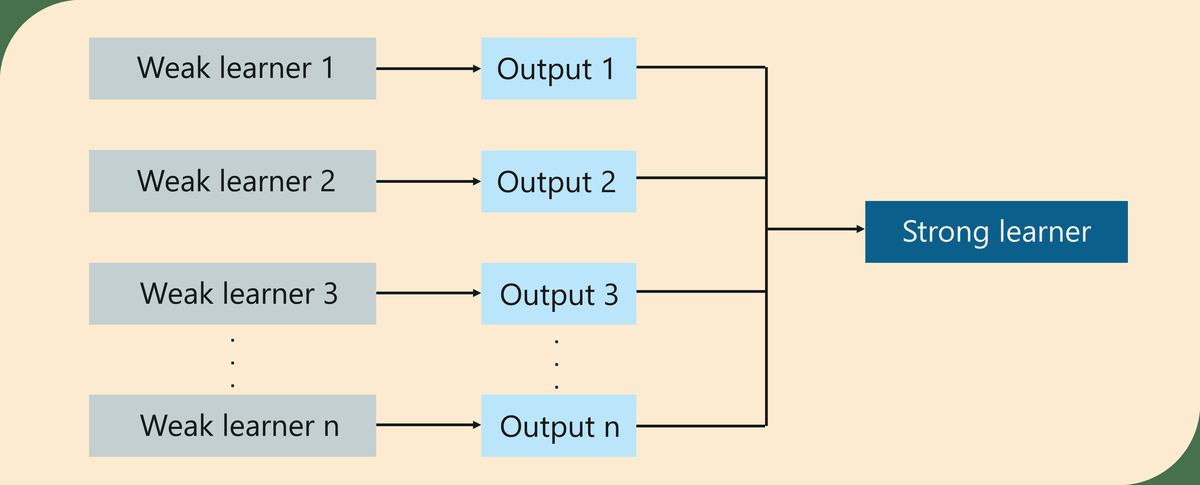
Was ist Boosting - Boosting Machine Learning - Edureka
Wie ich bereits erwähnte, ist Boosting eine Ensemble-Lernmethode, aber was genau ist Ensemble-Lernen?
php mysql_fetch_array
Was ist Ensemble beim maschinellen Lernen?
Ensemble-Lernen ist eine Methode, mit der die Leistung des Modells für maschinelles Lernen durch die Kombination mehrerer Lernender verbessert wird. Im Vergleich zu einem einzelnen Modell werden durch diese Art des Lernens Modelle mit verbesserter Effizienz und Genauigkeit erstellt. Genau aus diesem Grund werden Ensemble-Methoden verwendet, um marktführende Wettbewerbe wie den Netflix-Empfehlungswettbewerb, Kaggle-Wettbewerbe usw. zu gewinnen.
Was ist Ensemble-Lernen? - Maschinelles Lernen fördern - Edureka
Im Folgenden habe ich auch den Unterschied zwischen Boosting und Bagging erörtert.
Boosting vs Bagging
Das Lernen von Ensembles kann auf zwei Arten durchgeführt werden:
Sequentielles Ensemble, im Volksmund bekannt als erhöhen Hier werden die schwachen Lernenden während der Trainingsphase nacheinander erzeugt. Die Leistung des Modells wird verbessert, indem den vorherigen, falsch klassifizierten Stichproben eine höhere Gewichtung zugewiesen wird. Ein Beispiel für das Boosten ist der AdaBoost-Algorithmus.
Paralleles Set , im Volksmund bekannt als Absacken Hier werden die schwachen Lernenden während der Trainingsphase parallel produziert. Die Leistung des Modells kann gesteigert werden, indem eine Reihe schwacher Lernender parallel zu Bootstrap-Datensätzen geschult werden. Ein Beispiel für das Absacken ist der Random Forest Algorithmus.
In diesem Blog werde ich mich auf die Boosting-Methode konzentrieren. Im folgenden Abschnitt werden wir verstehen, wie der Boosting-Algorithmus funktioniert.
Wie funktioniert der Boosting-Algorithmus?
Das Grundprinzip hinter der Arbeit des Boosting-Algorithmus besteht darin, mehrere schwache Lernende zu generieren und ihre Vorhersagen zu einer starken Regel zu kombinieren. Diese schwachen Regeln werden durch Anwenden von Basisalgorithmen für maschinelles Lernen auf verschiedene Verteilungen des Datensatzes generiert. Diese Algorithmen erzeugen schwache Regeln für jede Iteration. Nach mehreren Iterationen werden die schwachen Lernenden zu einem starken Lernenden zusammengefasst, der ein genaueres Ergebnis vorhersagt.
Wie funktioniert der Boosting-Algorithmus? - Boosting Machine Learning - Edureka
So funktioniert der Algorithmus:
Schritt 1: Der Basisalgorithmus liest die Daten und weist jeder Probenbeobachtung das gleiche Gewicht zu.
Schritt 2: Falsche Vorhersagen des Basisschülers werden identifiziert. In der nächsten Iteration werden diese falschen Vorhersagen dem nächsten Grundschüler mit einer höheren Gewichtung dieser falschen Vorhersagen zugewiesen.
Schritt 3: Wiederholen Sie Schritt 2, bis der Algorithmus die Ausgabe korrekt klassifizieren kann.
Daher ist das Hauptziel von Boosting sich mehr auf falsch klassifizierte Vorhersagen zu konzentrieren.
Nachdem wir nun wissen, wie der Boosting-Algorithmus funktioniert, wollen wir die verschiedenen Arten von Boosting-Techniken verstehen.
Arten der Auffrischung
Es gibt drei Hauptmethoden, mit denen das Boosten durchgeführt werden kann:
Adaptives Boosting oder AdaBoost
Gradientenverstärkung
XGBoost
Ich werde die Grundlagen hinter jedem dieser Typen diskutieren.
Adaptives Boosting
AdaBoost wird implementiert, indem mehrere schwache Lernende zu einem einzigen starken Lernenden kombiniert werden.
Die schwachen Lernenden in AdaBoost berücksichtigen eine einzelne Eingabefunktion und zeichnen einen einzelnen geteilten Entscheidungsbaum, den so genannten Entscheidungsstumpf. Jede Beobachtung wird gleich gewogen, während der erste Entscheidungsstumpf herausgezogen wird.
Die Ergebnisse des ersten Entscheidungsstumpfes werden analysiert, und wenn Beobachtungen falsch klassifiziert werden, werden ihnen höhere Gewichte zugewiesen.
Danach wird ein neuer Entscheidungsstumpf gezogen, indem die Beobachtungen mit höheren Gewichten als signifikanter betrachtet werden.
Wenn Beobachtungen falsch klassifiziert werden, erhalten sie ein höheres Gewicht und dieser Prozess wird fortgesetzt, bis alle Beobachtungen in die richtige Klasse fallen.
Adaboost kann sowohl für klassifizierungs- als auch für regressionsbasierte Probleme verwendet werden, wird jedoch häufiger für Klassifizierungszwecke verwendet.
Gradientenverstärkung
Gradient Boosting basiert auch auf sequentiellem Ensemble-Lernen. Hier werden die Basislerner nacheinander so erzeugt, dass der gegenwärtige Basislerner immer effektiver ist als der vorherige, d. H. Das Gesamtmodell verbessert sich nacheinander mit jeder Iteration.
Der Unterschied bei dieser Art der Steigerung besteht darin, dass die Gewichte für falsch klassifizierte Ergebnisse nicht erhöht werden. Stattdessen versucht die Gradientenverstärkungsmethode, die Verlustfunktion des vorherigen Lernenden zu optimieren, indem ein neues Modell hinzugefügt wird, das schwache Lernende hinzufügt, um die Verlustfunktion zu verringern.
Die Hauptidee hierbei ist es, die Fehler in den Vorhersagen des vorherigen Lernenden zu überwinden. Diese Art der Verstärkung besteht aus drei Hauptkomponenten:
Verlustfunktion das muss verbessert werden.
Schwacher Lerner zur Berechnung von Vorhersagen und zur Bildung starker Lernender.
Ein Additives Modell das wird die Verlustfunktion regulieren.
Wie AdaBoost kann Gradient Boosting auch für Klassifizierungs- und Regressionsprobleme verwendet werden.
XGBoost
XGBoost ist eine erweiterte Version der Gradientenverstärkungsmethode. Es bedeutet wörtlich eXtreme Gradientenverstärkung. XGBoost, entwickelt von Tianqi Chen, fällt unter die Kategorie Distributed Machine Learning Community (DMLC).
Das Hauptziel dieses Algorithmus ist es, die Geschwindigkeit und Effizienz der Berechnung zu erhöhen. Der Gradient Descent Boosting-Algorithmus berechnet die Ausgabe langsamer, da sie den Datensatz nacheinander analysieren. Daher wird XGBoost verwendet, um die Leistung des Modells zu steigern oder extrem zu steigern.
XGBoost - Förderung des maschinellen Lernens - Edureka
XGBoost konzentriert sich auf Rechengeschwindigkeit und Modelleffizienz. Die Hauptfunktionen von XGBoost sind:
Parallel dazu werden Entscheidungsbäume erstellt.
Implementierung verteilter Rechenmethoden zur Bewertung großer und komplexer Modelle.
Verwenden von Out-of-Core-Computing zum Analysieren großer Datenmengen.
Implementierung der Cache-Optimierung, um Ressourcen optimal zu nutzen.
Das waren also diesedie verschiedenen Arten von Boosting Machine Learning-Algorithmen. Um die Sache interessant zu machen, werden wir im folgenden Abschnitt eine Demo ausführen, um zu sehen, wie Boosting-Algorithmen in Python implementiert werden können.
Verbesserung des maschinellen Lernens in Python
Ein kurzer Haftungsausschluss: Ich verwende Python, um diese Demo auszuführen. Wenn Sie Python nicht kennen, können Sie die folgenden Blogs durchgehen:
Jetzt ist es Zeit, sich die Hände schmutzig zu machen und mit dem Codieren zu beginnen.
Problemstellung: Untersuchung eines Pilzdatensatzes und Erstellung eines Modells für maschinelles Lernen, mit dem ein Pilz durch Analyse seiner Merkmale als giftig oder nicht giftig eingestuft werden kann.
Datensatzbeschreibung: Dieser Datensatz enthält eine detaillierte Beschreibung hypothetischer Proben gemäß 23 Arten von Kiemenpilzen. Jede Art wird entweder als Speisepilz oder als nicht essbarer (giftiger) Pilz klassifiziert.
Logik: Erstellen eines Modells für maschinelles Lernen mithilfe eines der Boosting-Algorithmen, um vorherzusagen, ob ein Pilz essbar ist oder nicht.
Schritt 1: Importieren Sie die erforderlichen Pakete
aus sklearn.ensemble importieren AdaBoostClassifier aus sklearn.preprocessing importieren LabelEncoder aus sklearn.tree importieren DecisionTreeClassifier importieren Pandas als pd # Importiere train_test_split Funktion aus sklearn.model_selection importiere train_test_split #Importiere scikit-learn Metrikmodul für Genauigkeitsberechnung aus
Schritt 2: Importieren Sie den Datensatz
# In den Datendatensatz laden = pd.read_csv ('C: //Users//NeelTemp//Desktop//mushroomsdataset.csv')Schritt 3: Datenverarbeitung
#Definieren Sie die Spaltennamen dataset.columns = ['Ziel', 'Kappenform', 'Kappenoberfläche', 'Kappenfarbe', 'blaue Flecken', 'Geruch', 'Kiemenansatz', 'Kiemenabstand ',' Kiemengröße ',' Kiemenfarbe ',' Stielform ',' Stielwurzel ',' Stieloberfläche über dem Ring ',' Stieloberfläche unter dem Ring ',' Stielfarbe ' -über dem Ring ',' Stielfarbe unter dem Ring ',' Schleiertyp ',' Schleierfarbe ',' Ringnummer ',' Ringtyp ',' Sporendruckfarbe ',' Population ',' Habitat '] für Label in Dataset.Spalten: Dataset [Label] = LabelEncoder (). Fit (Dataset [Label]). Transformation (Dataset [Label]) # Informationen zum Datensatzdruck anzeigen (Dataset.info ( )) Int64Index: 8124 Einträge, 6074 bis 686 Datenspalten (insgesamt 23 Spalten): Ziel 8124 nicht null int32 Kappenform 8124 nicht null int32 Kappenoberfläche 8124 nicht null int32 Kappenfarbe 8124 nicht null int32 blaue Flecken 8124 Nicht-Null-Int32-Geruch 8124 Nicht-Null-Int32-Kiemenaufsatz 8124 Nicht-Null-Int32-Kiemenabstand 8124 Nicht-Null-Int32-Kiemengröße 8124 Nicht-Null-Int32-Kiemenfarbe 8124 Nicht-Null-Int32-Stielform 8124 Nicht-Null-Int32 Stalk-Root 8124 nicht null int32 Stieloberfläche über dem Ring 8124 nicht null int32 Stieloberfläche unter dem Ring 8124 nicht null int32 Stielfarbe über dem Ring 8124 nicht null int32 Stielfarbe unter dem Ring 8124 nicht null int32 Schleier- Typ 8124 nicht null int32 Schleierfarbe 8124 nicht null int32 Ringnummer 8124 nicht null int32 Ringtyp 8124 nicht null int32 Sporendruckfarbe 8124 nicht null int32 Population 8124 nicht null int32 Lebensraum 8124 nicht null int32 dtypes: int32 (23) Speichernutzung: 793,4 KB
Schritt 4: Datenspleißen
X = Dataset.drop (['Ziel'], Achse = 1) Y = Datensatz ['Ziel'] X_train, X_test, Y_train, Y_test = train_test_split (X, Y, Testgröße = 0,3)
Schritt 5: Erstellen Sie das Modell
model = DecisionTreeClassifier (Kriterium = 'Entropie', max_depth = 1) AdaBoost = AdaBoostClassifier (base_estimator = model, n_estimators = 400, learning_rate = 1)
Im obigen Code-Snippet haben wir den AdaBoost-Algorithmus implementiert. Die Funktion 'AdaBoostClassifier' akzeptiert drei wichtige Parameter:
Dropdown-Menü in AngularJs
- base_estimator: Der Basisschätzer (schwacher Lernender) ist standardmäßig Entscheidungsbäume
- n_estimator: Dieses Feld gibt die Anzahl der zu verwendenden Basislerner an.
- learning_rate: Dieses Feld gibt die Lernrate an, die wir auf den Standardwert gesetzt haben, d. h. 1.
# Passen Sie das Modell mit Trainingsdaten an. Boostmodel = AdaBoost.fit (X_train, Y_train)
Schritt 6: Modellbewertung
#Bewerten Sie die Genauigkeit des Modells. Y_pred = boostmodel.predict (X_test) Vorhersagen = Metriken. Genauigkeitsbewertung (Y_test, y_pred) #Berechnen der Genauigkeit in Prozent Druck ('Die Genauigkeit ist:', Vorhersagen * 100, '%') Die Genauigkeit ist: 100,0%Wir haben eine Genauigkeit von 100% erhalten, was perfekt ist!
Damit sind wir am Ende dieses Boosting Machine Learning-Blogs angelangt. Wenn Sie mehr über maschinelles Lernen erfahren möchten, können Sie diese Blogs lesen:
Wenn Sie sich für einen vollständigen Kurs über künstliche Intelligenz und maschinelles Lernen anmelden möchten, hat Edureka einen speziell kuratierten Kurs Dadurch beherrschen Sie Techniken wie überwachtes Lernen, unbeaufsichtigtes Lernen und Verarbeitung natürlicher Sprachen. Es umfasst Schulungen zu den neuesten Fortschritten und technischen Ansätzen im Bereich künstliche Intelligenz und maschinelles Lernen wie Deep Learning, grafische Modelle und Reinforcement Learning.