
Hive ist ein Data Warehouse-System für Hadoop, das eine einfache Zusammenfassung von Daten, Ad-hoc-Abfragen und die Analyse großer Datenmengen ermöglicht, die in Hadoop-kompatiblen Dateisystemen gespeichert sind. Hive strukturiert Daten in gut verstandene Datenbankkonzepte wie Tabellen, Zeilen, Spalten und Partitionen. Es unterstützt primitive Typen wie Integer, Floats, Doubles und Strings. Hive unterstützt auch assoziative Arrays, Listen, Strukturen und Serialize und Deserialized API wird zum Verschieben von Daten in und aus Tabellen verwendet.
Schauen wir uns die Hive-Datenmodelle im Detail an
konvertiere binär in int java
Hive-Datenmodelle:
Die Hive-Datenmodelle enthalten die folgenden Komponenten:
- Datenbanken
- Tabellen
- Partitionen
- Eimer oder Cluster
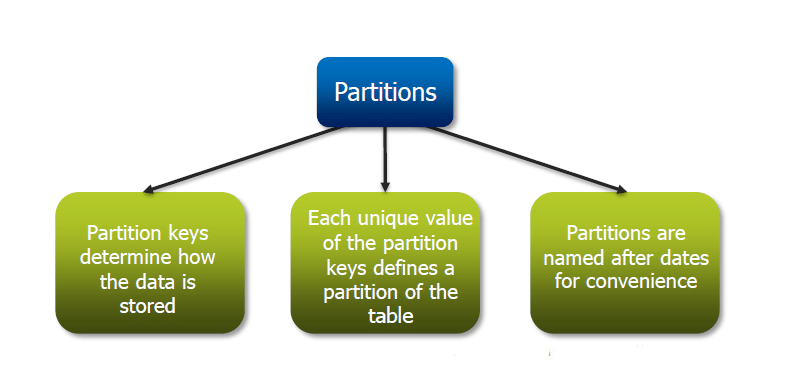
Partitionen:
Partition bedeutet, eine Tabelle basierend auf dem Wert einer Partitionsspalte wie „Daten“ in grobkörnige Teile zu unterteilen. Dies macht es schneller, Abfragen für Datenscheiben durchzuführen
PHP konvertiert Objekt in Array
Was ist die Funktion der Partition? Die Partitionstasten bestimmen, wie Daten gespeichert werden. Hier definiert jeder eindeutige Wert des Partitionsschlüssels eine Partition der Tabelle. Die Partitionen sind der Einfachheit halber nach Datumsangaben benannt. Es ähnelt dem Block Splitting in HDFS.
Eimer:
Buckets geben den Daten, die für effiziente Abfragen verwendet werden können, zusätzliche Struktur. Ein Join aus zwei Tabellen, die sich in denselben Spalten befinden, einschließlich der Join-Spalte, kann als Map-Side-Join implementiert werden. Das Bucketing nach verwendeter ID bedeutet, dass wir eine benutzerbasierte Abfrage schnell auswerten können, indem wir sie anhand einer zufälligen Stichprobe der gesamten Benutzermenge ausführen.
Hast du eine Frage an uns? Bitte erwähnen Sie sie in den Kommentaren und wir werden uns bei Ihnen melden.
Unterschied zwischen Geräten und erweitert
Zusammenhängende Posts: