
Spark MLlib ist die Komponente für maschinelles Lernen von Apache Spark.Eine der Hauptattraktionen von Spark ist die Fähigkeit, Berechnungen massiv zu skalieren, und genau das benötigen Sie für Algorithmen für maschinelles Lernen. Die Einschränkung besteht jedoch darin, dass nicht alle Algorithmen für maschinelles Lernen effektiv parallelisiert werden können. Jeder Algorithmus hat seine eigenen Herausforderungen für die Parallelisierung, egal ob es sich um Aufgabenparallelität oder Datenparallelität handelt.
Trotzdem wird Spark zur De-facto-Plattform für die Erstellung von Algorithmen und Anwendungen für maschinelles Lernen.Nun, Sie können die überprüfen kuratiert von Branchenexperten, bevor der Blog fortgesetzt wird.Die Entwickler, die an der Spark MLlib arbeiten, implementieren immer mehr Maschinenalgorithmen skalierbar und präzise im Spark-Framework. In diesem Blog lernen wir die Konzepte des maschinellen Lernens, Spark MLlib, seine Dienstprogramme, Algorithmen und einen vollständigen Anwendungsfall des Movie Recommendation System kennen.
Die folgenden Themen werden in diesem Blog behandelt:
- Was ist maschinelles Lernen?
- Spark MLlib Übersicht
- Spark MLlib Tools
- MLlib-Algorithmen
- Anwendungsfall - Filmempfehlungssystem
Was ist maschinelles Lernen?
Das maschinelle Lernen, das aus dem Studium der Mustererkennung und der Theorie des rechnergestützten Lernens in der künstlichen Intelligenz hervorgegangen ist, untersucht das Studium und die Konstruktion von Algorithmen, die aus Daten lernen und Vorhersagen treffen können. Solche Algorithmen werden nach streng statischen Programmanweisungen überwunden, indem datengesteuerte Vorhersagen oder Entscheidungen getroffen werden durch Erstellen eines Modells aus Beispieleingaben.
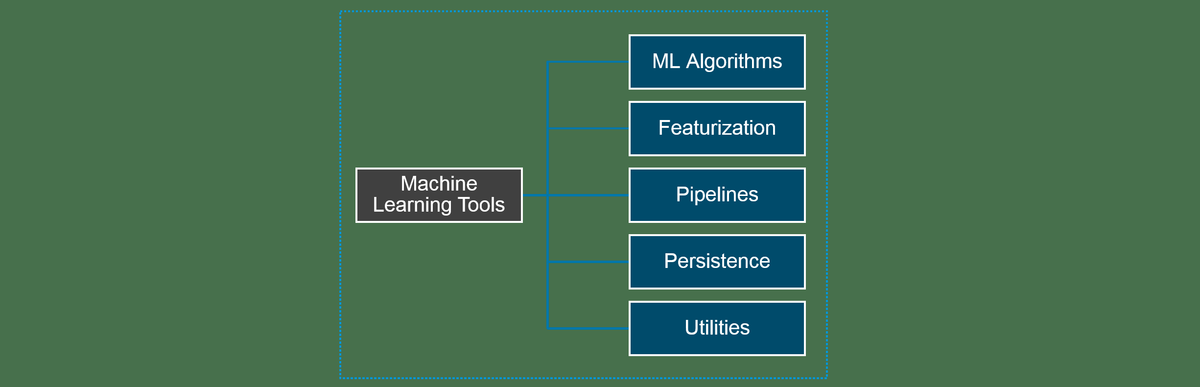 Zahl: Werkzeuge für maschinelles Lernen
Zahl: Werkzeuge für maschinelles Lernen
Maschinelles Lernen ist eng mit der Computerstatistik verbunden, die sich auch auf die Vorhersage mithilfe von Computern konzentriert. Es ist eng mit der mathematischen Optimierung verbunden, die dem Feld Methoden, Theorie und Anwendungsbereiche liefert. Im Bereich der Datenanalyse ist maschinelles Lernen eine Methode zur Entwicklung komplexer Modelle und Algorithmen, die sich für eine Vorhersage eignen, die im kommerziellen Einsatz als Predictive Analytics bezeichnet wird.
Es gibt drei Kategorien von maschinellen Lernaufgaben:
- Überwachtes Lernen : Beim überwachten Lernen haben Sie Eingabevariablen (x) und eine Ausgabevariable (Y) und verwenden einen Algorithmus, um die Zuordnungsfunktion von der Eingabe zur Ausgabe zu lernen.
- Unbeaufsichtigtes Lernen : Unüberwachtes Lernen ist eine Art maschinelles Lernalgorithmus, mit dem Rückschlüsse aus Datensätzen gezogen werden, die aus Eingabedaten ohne gekennzeichnete Antworten bestehen.
- Verstärkungslernen : Ein Computerprogramm interagiert mit einer dynamischen Umgebung, in der es ein bestimmtes Ziel erreichen muss (z. B. ein Fahrzeug fahren oder ein Spiel gegen einen Gegner spielen). Das Programm erhält Feedback zu Belohnungen und Bestrafungen, wenn es durch seinen Problembereich navigiert.Dieses Konzept wird als verstärkendes Lernen bezeichnet.
Spark MLlib Übersicht
Spark MLlib wird verwendet, um maschinelles Lernen in Apache Spark durchzuführen. MLlib besteht aus gängigen Algorithmen und Dienstprogrammen.
MLlib Übersicht:
- spark.mllib enthält die ursprüngliche API, die auf RDDs basiert. Es befindet sich derzeit im Wartungsmodus.
- spark.ml bietet eine API auf höherer Ebene, die auf DataFrames für basiertBau von ML-Pipelines. spark.ml ist derzeit die primäre maschinelle Lern-API für Spark.
Spark MLlib Tools
Spark MLlib bietet die folgenden Tools:
- ML-Algorithmen: ML-Algorithmen bilden den Kern von MLlib. Dazu gehören gängige Lernalgorithmen wie Klassifizierung, Regression, Clustering und kollaborative Filterung.
- Featurization: Die Ausstattung umfasst die Extraktion, Transformation, Reduzierung der Dimensionalität und Auswahl von Merkmalen.
- Pipelines: Pipelines bieten Tools zum Erstellen, Bewerten und Optimieren von ML-Pipelines.
- Beharrlichkeit: Persistenz hilft beim Speichern und Laden von Algorithmen, Modellen und Pipelines.
- Dienstprogramme: Dienstprogrammefür lineare Algebra, Statistik und Datenverarbeitung.
MLlib-Algorithmen
Die gängigen Algorithmen und Dienstprogramme in Spark MLlib sind:
- Grundlegende Statistik
- Regression
- Einstufung
- Empfehlungssystem
- Clustering
- Reduzierung der Dimensionalität
- Feature-Extraktion
- Optimierung
Lassen Sie uns einige davon im Detail betrachten.
Grundlegende Statistik
Grundlegende Statistik beinhaltet die grundlegendsten Techniken des maschinellen Lernens. Diese schließen ein:
- Zusammengefasste Statistiken : Beispiele sind Mittelwert, Varianz, Anzahl, max, min und numNonZeros.
- Korrelationen : Spearman und Pearson sind einige Möglichkeiten, um eine Korrelation zu finden.
- Geschichtete Stichprobe : Dazu gehören sampleBykey und sampleByKeyExact.
- Hypothesentest : Der Pearson-Chi-Quadrat-Test ist ein Beispiel für das Testen von Hypothesen.
- Zufällige Datengenerierung : RandomRDDs, Normal und Poisson werden verwendet, um zufällige Daten zu generieren.
Regression
Regression Die Analyse ist ein statistischer Prozess zur Schätzung der Beziehungen zwischen Variablen. Es enthält viele Techniken zum Modellieren und Analysieren mehrerer Variablen, wenn der Schwerpunkt auf der Beziehung zwischen einer abhängigen Variablen und einer oder mehreren unabhängigen Variablen liegt. Insbesondere hilft die Regressionsanalyse zu verstehen, wie sich der typische Wert der abhängigen Variablen ändert, wenn eine der unabhängigen Variablen variiert wird, während die anderen unabhängigen Variablen festgehalten werden.
Die Regressionsanalyse wird häufig für Vorhersagen und Prognosen verwendet, wobei sich ihre Verwendung erheblich mit dem Bereich des maschinellen Lernens überschneidet. Die Regressionsanalyse wird auch verwendet, um zu verstehen, welche der unabhängigen Variablen mit der abhängigen Variablen zusammenhängen, und um die Formen dieser Beziehungen zu untersuchen. Unter eingeschränkten Umständen kann eine Regressionsanalyse verwendet werden, um auf kausale Beziehungen zwischen den unabhängigen und abhängigen Variablen zu schließen.
Einstufung
Einstufung ist das Problem der Identifizierung, zu welcher einer Reihe von Kategorien (Teilpopulationen) eine neue Beobachtung gehört, auf der Grundlage eines Trainingssatzes von Daten, die Beobachtungen (oder Instanzen) enthalten, deren Kategoriemitgliedschaft bekannt ist. Es ist ein Beispiel für die Mustererkennung.
Hier wäre ein Beispiel das Zuweisen einer bestimmten E-Mail in 'Spam' - oder 'Nicht-Spam' -Klassen oder das Zuweisen einer Diagnose zu einem bestimmten Patienten, wie durch die beobachteten Merkmale des Patienten (Geschlecht, Blutdruck, Vorhandensein oder Fehlen bestimmter Symptome) beschrieben. usw.).
Empfehlungssystem
ZU Empfehlungssystem ist eine Unterklasse von Informationsfiltersystemen, die versuchen, die „Bewertung“ oder „Präferenz“ vorherzusagen, die ein Benutzer einem Artikel geben würde. Empfehlungssysteme sind in den letzten Jahren immer beliebter geworden und werden in einer Vielzahl von Bereichen eingesetzt, darunter Filme, Musik, Nachrichten, Bücher, Forschungsartikel, Suchanfragen, soziale Tags und Produkte im Allgemeinen.
Empfehlungssysteme erstellen normalerweise eine Liste von Empfehlungen auf zwei Arten - durch kollaborative und inhaltsbasierte Filterung oder durch persönlichkeitsbasierten Ansatz.
- Kollaboratives Filtern Ansätze zum Erstellen eines Modells aus dem Verhalten eines Benutzers in der Vergangenheit (zuvor gekaufte oder ausgewählte Artikel und / oder numerische Bewertungen dieser Artikel) sowie ähnliche Entscheidungen anderer Benutzer. Dieses Modell wird dann verwendet, um Elemente (oder Bewertungen für Elemente) vorherzusagen, an denen der Benutzer möglicherweise interessiert ist.
- Inhaltsbasierte Filterung Ansätze verwenden eine Reihe diskreter Eigenschaften eines Elements, um zusätzliche Elemente mit ähnlichen Eigenschaften zu empfehlen.
Darüber hinaus werden diese Ansätze häufig als hybride Empfehlungssysteme kombiniert.
Clustering
Clustering ist die Aufgabe, eine Gruppe von Objekten so zu gruppieren, dass Objekte in derselben Gruppe (Cluster genannt) einander (in gewissem Sinne) ähnlicher sind als Objekte in anderen Gruppen (Clustern). Daher ist es die Hauptaufgabe des explorativen Data Mining und eine gängige Technik für die statistische Datenanalyse, die in vielen Bereichen eingesetzt wird, darunter maschinelles Lernen, Mustererkennung, Bildanalyse, Informationsabruf, Bioinformatik, Datenkomprimierung und Computergrafik.
Reduzierung der Dimensionalität
Reduzierung der Dimensionalität ist der Prozess des Reduzierens der Anzahl der betrachteten Zufallsvariablen durch Erhalten eines Satzes von Hauptvariablen. Es kann in Merkmalsauswahl und Merkmalsextraktion unterteilt werden.
- Merkmalsauswahl: Die Feature-Auswahl findet eine Teilmenge der ursprünglichen Variablen (auch Features oder Attribute genannt).
- Feature-Extraktion: Dies transformiert die Daten im hochdimensionalen Raum in einen Raum mit weniger Dimensionen. Die Datentransformation kann linear sein, wie bei der Hauptkomponentenanalyse (PCA), es gibt jedoch auch viele nichtlineare Techniken zur Reduzierung der Dimensionalität.
Feature-Extraktion
Feature-Extraktion geht von einem anfänglichen Satz gemessener Daten aus und erstellt abgeleitete Werte (Merkmale), die informativ und nicht redundant sein sollen. Dies erleichtert die nachfolgenden Lern- und Verallgemeinerungsschritte und führt in einigen Fällen zu besseren menschlichen Interpretationen. Dies hängt mit der Verringerung der Dimensionalität zusammen.
Optimierung
Optimierung ist die Auswahl der BestenElement (in Bezug auf ein Kriterium) aus einer Reihe verfügbarer Alternativen.
Im einfachsten Fall besteht ein Optimierungsproblem darin, eine reale Funktion zu maximieren oder zu minimieren, indem systematisch Eingabewerte aus einem zulässigen Satz ausgewählt und der Wert der Funktion berechnet werden. Die Verallgemeinerung der Optimierungstheorie und -techniken auf andere Formulierungen umfasst einen großen Bereich der angewandten Mathematik. Im Allgemeinen umfasst die Optimierung das Finden der „besten verfügbaren“ Werte einer Zielfunktion bei einer definierten Domäne (oder Eingabe).einschließlich einer Vielzahl verschiedener Arten von Zielfunktionen und verschiedener Arten von Domänen.
Anwendungsfall - Filmempfehlungssystem
Problemstellung: So erstellen Sie ein Filmempfehlungssystem, das Filme basierend auf den Vorlieben eines Benutzers mit Apache Spark empfiehlt.
Unsere Anforderungen:
Lassen Sie uns also die Anforderungen für den Aufbau unseres Filmempfehlungssystems bewerten:
- Verarbeiten Sie große Datenmengen
- Eingabe aus mehreren Quellen
- Einfach zu verwenden
- Schnelle Abwicklung
Wie wir beurteilen könnenFür unsere Anforderungen benötigen wir das beste Big Data-Tool, um große Datenmengen in kurzer Zeit verarbeiten zu können. Daher Apache Spark ist das perfekte Tool zur Implementierung unseres Filmempfehlungssystems.
Schauen wir uns nun das Flussdiagramm für unser System an.
Wie wir sehen können, wird im Folgenden Streaming von Spark Streaming verwendet. Wir können in Echtzeit streamen oder Daten von Hadoop HDFS lesen.
Datensatz abrufen:
Für unser Filmempfehlungssystem können wir Benutzerbewertungen von vielen beliebten Websites wie IMDB, Rotten Tomatoes und Times Movie Ratings erhalten. Dieser Datensatz ist in vielen Formaten verfügbar, z. B. in CSV-Dateien oder Textdateien. A.nd Datenbanken. Wir können die Daten entweder live von den Websites streamen oder herunterladen und darin speichernunser lokales Dateisystem oder HDFS.
Datensatz:
Die folgende Abbildung zeigt, wie wir Datensätze von beliebten Websites sammeln können.
Sobald wir die Daten in Spark gestreamt haben, sieht es ungefähr so aus.
Maschinelles Lernen:
Das gesamte Empfehlungssystem basiert auf dem Algorithmus für maschinelles Lernen Wechselnde kleinste Quadrate . Hierbei handelt es sich bei ALS um eine Art Regressionsanalyse, bei der die Regression verwendet wird, um eine Linie zwischen den Datenpunkten so zu zeichnen, dass die Summe der Quadrate der Entfernung von jedem Datenpunkt minimiert wird. Somit wird diese Zeile dann verwendet, um die Werte der Funktion vorherzusagen, wo sie den Wert der unabhängigen Variablen erfüllt.
Die blaue Linie im Diagramm ist die am besten passende Regressionslinie. Für diese Linie ist der Wert der Dimension D minimal. Alle anderen roten Linien sind immer weiter vom gesamten Datensatz entfernt.
Spark MLlib-Implementierung:
- Wir werden Collaborative Filtering (CF) verwenden, um die Bewertungen für Benutzer für bestimmte Filme basierend auf ihren Bewertungen für andere Filme vorherzusagen.
- Wir arbeiten dies dann mit der Bewertung anderer Benutzer für diesen bestimmten Film zusammen.
- Um die folgenden Ergebnisse aus unserem maschinellen Lernen zu erhalten, müssen wir DataFrame, Dataset und SQL Service von Spark SQL verwenden.
Hier ist der Pseudocode für unser Programm:
wie man hashmap in java implementiert
import org.apache.spark.mllib.recommendation.ALS import org.apache.spark.mllib.recommendation.Rating import org.apache.spark.SparkConf // Importiere andere notwendige Pakete Objekt Movie {def main (args: Array [String] ) {val conf = new SparkConf (). setAppName ('Movie'). setMaster ('local [2]') val sc = new SparkContext (conf) val rawData = sc.textFile ('* Daten aus Film-CSV-Datei lesen * ') //rawData.first () val rawRatings = rawData.map (* Aufteilen von rawData auf Tabulatorbegrenzer *) val reviews = rawRatings.map {* Zuordnungsarray für Benutzer, Film und Bewertung *} // Training des Datenwertmodells = ALS.train (Bewertungen, 50, 5, 0,01) model.userFeatures model.userFeatures.count model.productFeatures.count val prognostiziertRating = * Vorhersage für Benutzer 789 für Film 123 * val userId = * Benutzer 789 * val K = 10 val topKRecs = model.recommendProducts (* Für Benutzer für den bestimmten Wert von K * empfehlen) println (topKRecs.mkString ('')) val movies = sc.textFile ('* Filmlistendaten lesen *') val title = movies.map (line => line.split ('|'). take ( 2)). Map (array => (array (0) .toInt, array (1))). CollectAsMap () val titleRDD = movies.map (line => line.split ('|'). Take (2) ) .map (array => (array (0) .toInt, array (1))). cache () title (123) val moviesForUser = Bewertungen. * Suche nach Benutzer 789 * val sqlContext = * SQL-Kontext erstellen * val moviesRecommended = sqlContext. * Erstellen Sie einen DataFrame für empfohlene Filme. * moviesRecommended.registerTempTable ('moviesRecommendedTable') sqlContext.sql ('Wählen Sie count (*) aus moviesRecommendedTable'). foreach (println) moviesForUser. * Sortieren Sie die Bewertungen für Benutzer 789 * .map (* Ordnen Sie die Bewertung dem Filmtitel zu *). * Drucke die Bewertung aus * val results = moviesForUser.sortBy (-_. Rating) .take (30) .map (Bewertung => (Titel (Bewertung.Produkt), Bewertung.Rating))}}Sobald wir Vorhersagen generiert haben, können wir Spark SQL verwenden, um die Ergebnisse in einem RDBMS-System zu speichern. Darüber hinaus kann dies in einer Webanwendung angezeigt werden.
Ergebnisse:
Zahl: Für Benutzer 77 empfohlene Filme
Hurra! Wir haben daher erfolgreich ein Filmempfehlungssystem mit Apache Spark erstellt. Damit haben wir nur einen der vielen beliebten Algorithmen behandelt, die Spark MLlib zu bieten hat. Wir werden mehr über maschinelles Lernen in den kommenden Blogs zu Data Science-Algorithmen erfahren.
In Zukunft können Sie Apache Spark mit Spark Tutorial und Spark Streaming Tutorial weiter lernenund Fragen zum Spark-Interview.Edureka ist bestrebt, online die bestmögliche Lernerfahrung zu bieten.
Schauen Sie sich unsere an ich Wenn Sie Spark lernen und eine Karriere im Bereich Spark aufbauen und Fachwissen aufbauen möchten, um eine umfassende Datenverarbeitung mit RDD, Spark Streaming, SparkSQL, MLlib, GraphX und Scala mit realen Anwendungsfällen durchzuführen.