
In diesem Beitrag werde ich darüber sprechen Apache Pig Installation unter Linux . Beginnen wir mit der grundlegenden Definition von Apache Pig und Pig Latin.
Apache Pig ist ein Tool / eine Plattform zum Erstellen und Ausführen des mit Hadoop verwendeten Map Reduce-Programms. Es ist ein Tool / eine Plattform zur Analyse großer Datenmengen. Sie können sagen, Apache Pig ist eine Abstraktion über MapReduce. Programmierer, die nicht so gut mit Java umgehen können, hatten Probleme mit der Arbeit an Hadoop, hauptsächlich beim Schreiben von MapReduce-Jobs.Es ist also ein wichtiges Thema, das man lernen und beherrschen muss .Apache Pig hat eine eigene Sprache Schwein Latein Das ist ein Segen für arme Programmierer.
Eine grundlegende Einführung in Pig Latin hilft Ihnen dabei, besser zu verstehen:
Die in der Apache Pig-Plattform verwendete übergeordnete Verfahrenssprache wird aufgerufen Schwein Latein . Apache Pig bietet 'Pig Latin', eine relativ einfachere Sprache, die über verteilte Datensätze im Hadoop File System (HDFS) ausgeführt werden kann. In Apache Pig müssen Sie Pig-Skripte in der lateinischen Sprache Pig schreiben, die beim Ausführen des Pig-Skripts in den MapReduce-Job konvertiert wird. Apache Pig verfügt über verschiedene Operatoren, mit denen Aufgaben wie Lesen, Schreiben und Verarbeiten der Daten ausgeführt werden. Weitere Informationen zu Apache Pig-Betreibern finden Sie in unserem Blog. “ Operatoren in Apache Pig: Teil 1 - Vergleichsoperatoren ”.
Nachdem Sie sich mit Apache Pig vertraut gemacht haben, beginnen wir mit der Installation von Apache Pig unter Linux.
Apache Pig Installation unter Linux:
Im Folgenden finden Sie die Schritte zur Installation von Apache Pig unter Linux (Ubuntu / Centos / Windows mit Linux VM). Ich verwende Ubuntu 16.04 im folgenden Setup.
Schritt 1: Herunterladen Schwein Teer Datei.
So erstellen Sie ein Objektarray in Java
Befehl: wget http://www-us.apache.org/dist/pig/pig-0.16.0/pig-0.16.0.tar.gz
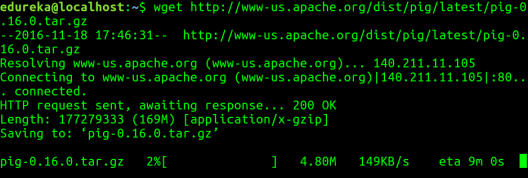
Schritt 2: Extrahieren Sie die Teer Datei mit dem Befehl tar. Im folgenden Befehl tar x bedeutet, eine Archivdatei zu extrahieren, mit bedeutet, ein Archiv durch gzip zu filtern, f bedeutet Dateiname einer Archivdatei.
Befehl: tar -xzf pig-0.16.0.tar.gz
Befehl: ls
Schritt 3: Bearbeiten Sie die “ .bashrc Datei, um die Umgebungsvariablen von Apache Pig zu aktualisieren. Wir stellen es so ein, dass wir von jedem Verzeichnis aus auf pig zugreifen können. Wir müssen nicht zum pig-Verzeichnis gehen, um pig-Befehle auszuführen. Wenn eine andere Anwendung nach Pig sucht, wird sie den Pfad von Apache Pig aus dieser Datei kennenlernen.
Befehl: sudo gedit .bashrc
Fügen Sie am Ende der Datei Folgendes hinzu:
# Setze PIG_HOME
export PIG_HOME = / home / edureka / pig-0.16.0
export PATH = $ PATH: /home/edureka/pig-0.16.0/bin
export PIG_CLASSPATH = $ HADOOP_CONF_DIR
Stellen Sie außerdem sicher, dass auch der Hadoop-Pfad festgelegt ist.
Was ist Salesforce Service Cloud?
Führen Sie den folgenden Befehl aus, damit die Änderungen im selben Terminal aktualisiert werden.
Befehl: Quelle .bashrc
Schritt 4: Überprüfen Sie die Schweineversion. Hiermit wird getestet, ob Apache Pig korrekt installiert wurde. Falls Sie die Apache Pig-Version nicht erhalten, müssen Sie überprüfen, ob Sie die obigen Schritte korrekt ausgeführt haben.
Befehl: Schweineversion
Schritt 5 ::Überprüfen Sie die Schweinehilfe, um alle Schweinebefehlsoptionen anzuzeigen.
Befehl: Schwein-Hilfe
c ++ gehe zur Zeile
Schritt 6 ::Führen Sie Pig aus, um die Grunzschale zu starten. Die Grunt-Shell wird zum Ausführen von Pig Latin-Skripten verwendet.
Befehl: Schwein
Wenn Sie das obige Bild richtig betrachten, verfügt Apache Pig über zwei Modi, in denen es ausgeführt werden kann. Standardmäßig wird der MapReduce-Modus ausgewählt. Der andere Modus, in dem Sie Pig ausführen können, ist der lokale Modus. Lassen Sie mich Ihnen mehr darüber erzählen.
Ausführungsmodi in Apache Pig:
- MapReduce-Modus - Dies ist der Standardmodus, für den Zugriff auf einen Hadoop-Cluster und eine HDFS-Installation erforderlich ist. Da dies ein Standardmodus ist, muss das Flag -x nicht angegeben werden (Sie können es ausführen Schwein ODER Schwein -x Mapreduce ). Der Ein- und Ausgang in diesem Modus ist in HDFS vorhanden.
- Lokalbetrieb - Beim Zugriff auf einen einzelnen Computer werden alle Dateien unter Verwendung eines lokalen Hosts und Dateisystems installiert und ausgeführt. Hier wird der lokale Modus mit dem Flag '-x' angegeben ( Schwein -x lokal ). Die Ein- und Ausgabe in diesem Modus ist im lokalen Dateisystem vorhanden.
Befehl: Schwein -x lokal
Sie können das folgende Video durchgehen, um die Installation von Apache Pig unter Linux anzusehen:
Apache Pig Installation | Pig Installation unter Linux | Edureka
Nachdem Sie mit der Apache Pig-Installation unter Linux fertig sind, besteht der nächste Schritt darin, einige relationale Pig-Operatoren auf der Pig Grunt-Shell auszuprobieren. Daher der nächste Blog “ Operatoren in Apache Pig: Teil 1 - Vergleichsoperatoren ”Hilft Ihnen, Pig-Operatoren zu beherrschen.
Nachdem Sie Apache Pig unter Linux installiert haben, lesen Sie die von Edureka, einem vertrauenswürdigen Online-Lernunternehmen mit einem Netzwerk von mehr als 250.000 zufriedenen Lernenden auf der ganzen Welt. Der Edureka Big Data Hadoop-Zertifizierungskurs hilft Lernenden, Experten für HDFS, Garn, MapReduce, Schwein, Bienenstock, HBase, Oozie, Flume und Sqoop zu werden. Dabei werden Anwendungsfälle in Echtzeit in den Bereichen Einzelhandel, soziale Medien, Luftfahrt, Tourismus und Finanzen verwendet.
Hast du eine Frage an uns? Bitte erwähnen Sie es in den Kommentaren und wir werden uns bei Ihnen melden.