
In diesem Blog werden wir die Datenanalyse mit Pandas in Python diskutieren.Heute, ist eine heiße Fähigkeit in der Branche, die PHP im Jahr 2017 und C # im Jahr 2018 in Bezug auf die allgemeine Beliebtheit und Verwendung übertroffen hat.Bevor man über Pandas spricht, muss man das Konzept der Numpy-Arrays verstehen. Warum? Denn Pandas ist eine Open-Source-Softwarebibliothek, die darauf aufbaut . In diesem Python Pandas Tutorial werde ich Sie durch die folgenden Themen führen, die als Grundlagen für die kommenden Blogs dienen:
Lass uns anfangen. :-)
Was ist Python Pandas?
Pandas wird zur Datenmanipulation, -analyse und -bereinigung verwendet. Python-Pandas eignen sich gut für verschiedene Arten von Daten, z.
- Tabellarische Daten mit heterogen typisierten Spalten
- Geordnete und ungeordnete Zeitreihendaten
- Beliebige Matrixdaten mit Zeilen- und Spaltenbeschriftungen
- Unbeschriftete Daten
- Jede andere Form von Beobachtungs- oder statistischen Datensätzen
Wie installiere ich Pandas?
Um Python Pandas zu installieren, gehen Sie zu Ihrer Befehlszeile / Ihrem Terminal und geben Sie 'pip install pandas' ein. Wenn Sie anaconda auf Ihrem System installiert haben, geben Sie einfach 'conda install pandas' ein. Gehen Sie nach Abschluss der Installation zu Ihrer IDE (Jupyter, PyCharm usw.) und importieren Sie sie einfach, indem Sie Folgendes eingeben: 'Pandas als pd importieren'
Schauen wir uns im Python-Pandas-Tutorial einige seiner Vorgänge an:
Python Pandas Operationen
Mit Python-Pandas können Sie viele Operationen mit Serien, Datenrahmen, fehlenden Daten, Gruppieren nach usw. ausführen. Einige der häufigsten Operationen zur Datenmanipulation sind nachfolgend aufgeführt:
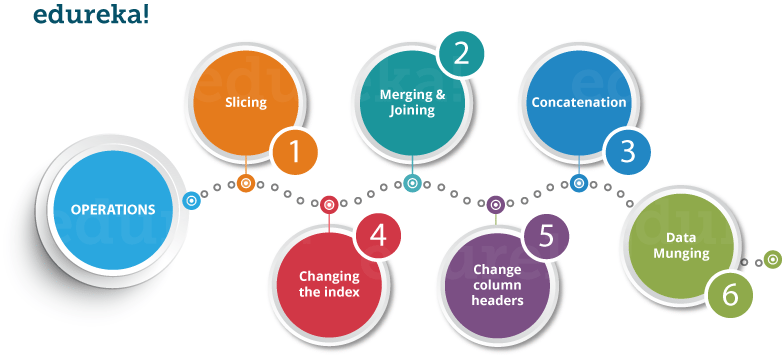
Lassen Sie uns nun alle diese Operationen einzeln verstehen.
Schneiden des Datenrahmens
Um Slicing für Daten durchzuführen, benötigen Sie einen Datenrahmen. Keine Sorge, der Datenrahmen ist eine zweidimensionale Datenstruktur und ein am häufigsten verwendetes Pandas-Objekt. Lassen Sie uns zunächst einen Datenrahmen erstellen.
Informationen zur Implementierung in PyCharm finden Sie im folgenden Code::
Pandas importieren als pd XYZ_web = {'Tag': [1,2,3,4,5,6], 'Besucher': [1000, 700,6000,1000,400,350], 'Bounce_Rate': [20,20, 23,15,10,34]} df = pd.DataFrame (XYZ_web) print (df)Ausgabe ::
Bounce_Rate Day Besucher 0 20 1 1000 1 20 2 700 2 23 3 6000 3 15 4 1000 4 10 5 400 5 34 6 350
Der obige Code konvertiert ein Wörterbuch zusammen mit dem Index links in einen Pandas-Datenrahmen. Lassen Sie uns nun eine bestimmte Spalte aus diesem Datenrahmen herausschneiden. Siehe das Bild unten:
Java-Code von binär zu dezimal
print (df.head (2))
Ausgabe:
Bounce_Rate Day Besucher 0 20 1 1000 1 20 2 700
Wenn Sie die letzten beiden Zeilen der Daten möchten, geben Sie den folgenden Befehl ein:
print (df.tail (2))
Ausgabe:
Bounce_Rate Day Besucher 4 10 5 400 5 34 6 350
Lassen Sie uns als Nächstes im Python Pandas-Tutorial das Zusammenführen und Verbinden durchführen.
Zusammenführen & Beitreten
Beim Zusammenführen können Sie zwei Datenrahmen zu einem einzigen Datenrahmen zusammenführen. Sie können auch entscheiden, welche Spalten Sie gemeinsam verwenden möchten. Lassen Sie mich das praktisch umsetzen. Zuerst erstelle ich drei Datenrahmen mit einigen Schlüssel-Wert-Paaren und füge dann die Datenrahmen zusammen. Beachten Sie den folgenden Code:
HPI IND_GDP Int_Rate 0 80 50 2 1 90 45 1 2 70 45 2 3 60 67 3
Ausgabe:
Pandas importieren als pd df1 = pd.DataFrame ({'HPI': [80,90,70,60], 'Int_Rate': [2,1,2,3], 'IND_GDP': [50,45,45, 67]}, index = [2001, 2002, 2003, 2004]) df2 = pd.DataFrame ({'HPI': [80,90,70,60], 'Int_Rate': [2,1,2,3] , 'IND_GDP': [50,45,45,67]}, index = [2005, 2006, 2007, 2008]) zusammengeführt = pd.merge (df1, df2) print (zusammengeführt)Wie Sie oben sehen können, wurden die beiden Datenrahmen zu einem einzigen Datenrahmen zusammengeführt. Jetzt können Sie auch die Spalte angeben, die Sie gemeinsam erstellen möchten. Zum Beispiel möchte ich, dass die Spalte „HPI“ gemeinsam ist, und für alles andere möchte ich separate Spalten. Lassen Sie mich das praktisch umsetzen:
df1 = pd.DataFrame ({'HPI': [80,90,70,60], 'Int_Rate': [2,1,2,3], 'IND_GDP': [50,45,45,67]}, index = [2001, 2002, 2003, 2004]) df2 = pd.DataFrame ({'HPI': [80,90,70,60], 'Int_Rate': [2,1,2,3], 'IND_GDP' : [50,45,45,67]}, index = [2005, 2006,2007,2008]) zusammengeführt = pd.merge (df1, df2, on = 'HPI') print (zusammengeführt)Ausgabe:
IND_GDP Int_Rate Low_Tier_HPI Arbeitslosigkeit 2001 50 2 50,0 1,0 2002 45 1 NaN NaN 2003 45 2 45,0 3,0 2004 67 3 67,0 5,0 2004 67 3 34,0 6,0
Lassen Sie uns als nächstes verstehen Beitritt in Python Pandas Tutorial. Es ist eine weitere bequeme Methode, zwei unterschiedlich indizierte Datenrahmen zu einem einzigen Ergebnisdatenrahmen zu kombinieren. Dies ist der Operation 'Zusammenführen' ziemlich ähnlich, außer dass sich die Verknüpfungsoperation auf dem 'Index' anstelle der 'Spalten' befindet. Lassen Sie es uns praktisch umsetzen.
df1 = pd.DataFrame ({'Int_Rate': [2,1,2,3], 'IND_GDP': [50,45,45,67]}, index = [2001, 2002,2003,2004]) df2 = pd.DataFrame ({'Low_Tier_HPI': [50,45,67,34], 'Arbeitslosigkeit': [1,3,5,6]}, index = [2001, 2003,2004,2004]) join = df1. join (df2) print (verbunden)Ausgabe:
IND_GDP Int_Rate Low_Tier_HPI Arbeitslosigkeit 2001 50 2 50,0 1,0 2002 45 1 NaN NaN 2003 45 2 45,0 3,0 2004 67 3 67,0 5,0 2004 67 3 34,0 6,0
Wie Sie in der obigen Ausgabe sehen können, ist im Jahr 2002 (Index) den Spalten „low_tier_HPI“ und „Arbeitslosigkeit“ kein Wert zugeordnet, daher wurde NaN (Not a Number) gedruckt. Später im Jahr 2004 sind beide Werte verfügbar, daher wurden die entsprechenden Werte gedruckt.
Sie können diese Aufzeichnung des Python Pandas-Tutorials durchgehen, in der unser Kursleiter die Themen anhand von Beispielen ausführlich erläutert hat, die Ihnen helfen, dieses Konzept besser zu verstehen.
Python für die Datenanalyse | Python Pandas Tutorial | Python-Training | Edureka
Lassen Sie uns im Python-Pandas-Tutorial verstehen, wie zwei Datendatenrahmen verkettet werden.
Verkettung
Die Verkettung klebt die Datenrahmen grundsätzlich zusammen. Sie können die Dimension auswählen, auf der Sie verketten möchten. Verwenden Sie dazu einfach 'pd.concat' und übergeben Sie die Liste der Datenrahmen, um sie miteinander zu verketten. Betrachten Sie das folgende Beispiel.
df1 = pd.DataFrame ({'HPI': [80,90,70,60], 'Int_Rate': [2,1,2,3], 'IND_GDP': [50,45,45,67]}, index = [2001, 2002, 2003, 2004]) df2 = pd.DataFrame ({'HPI': [80,90,70,60], 'Int_Rate': [2,1,2,3], 'IND_GDP' : [50,45,45,67]}, index = [2005, 2006,2007,2008]) concat = pd.concat ([df1, df2]) print (concat)Ausgabe:
HPI IND_GDP Int_Rate 2001 80 50 2 2002 90 45 1 2003 70 45 2 2004 60 67 3 2005 80 50 2 2006 90 45 1 2007 70 45 2 2008 60 67 3
Wie Sie oben sehen können, werden die beiden Datenrahmen in einem einzigen Datenrahmen zusammengeklebt, wobei der Index von 2001 bis 2008 beginnt. Als Nächstes können Sie auch Achse = 1 angeben, um die Spalten zu verbinden, zusammenzuführen oder zu verketten. Beachten Sie den folgenden Code:
df1 = pd.DataFrame ({'HPI': [80,90,70,60], 'Int_Rate': [2,1,2,3], 'IND_GDP': [50,45,45,67]}, index = [2001, 2002, 2003, 2004]) df2 = pd.DataFrame ({'HPI': [80,90,70,60], 'Int_Rate': [2,1,2,3], 'IND_GDP' : [50,45,45,67]}, index = [2005, 2006,2007,2008]) concat = pd.concat ([df1, df2], axis = 1) print (concat)Ausgabe:
HPI IND_GDP Int_Rate HPI IND_GDP Int_Rate 2001 80,0 50,0 2,0 NaN NaN NaN 2002 90,0 45,0 1,0 NaN NaN NaN 2003 70,0 45,0 2,0 NaN NaN NaN 2004 60,0 67,0 3,0 NaN NaN NaN 2005 NaN NaN NaN 80,0 50,0 2,0 2006 NaN NaN NaN 90,0 45,0 NaN NaN 70,0 45,0 2,0 2008 NaN NaN NaN 60,0 67,0 3,0
Wie Sie oben sehen können, fehlen einige Werte. Dies liegt daran, dass die Datenrahmen nicht für alle Indizes Werte hatten, auf denen Sie verketten möchten. Stellen Sie daher sicher, dass alle Informationen korrekt angezeigt werden, wenn Sie die Achse verbinden oder verketten.
Ändern Sie den Index
Als Nächstes erfahren Sie im Tutorial zu Python Pandas, wie Sie die Indexwerte in einem Datenrahmen ändern. Lassen Sie uns beispielsweise einen Datenrahmen mit einigen Schlüsselwertpaaren in einem Wörterbuch erstellen und die Indexwerte ändern. Betrachten Sie das folgende Beispiel:
Mal sehen, wie es tatsächlich passiert:
Pandas importieren als pd df = pd.DataFrame ({'Tag': [1,2,3,4], 'Besucher': [200, 100,230,300], 'Bounce_Rate': [20,45,60,10]}) df.set_index ('Tag', inplace = True) print (df)Ausgabe:
Bounce_Rate Besucher Tag 1 20 200 2 45 100 3 60 230 4 10 300
Wie Sie in der obigen Ausgabe sehen können, wurde der Indexwert in Bezug auf die Spalte 'Tag' geändert.
Ändern Sie die Spaltenüberschriften
Lassen Sie uns nun die Überschriften der Spalte in diesem Python-Pandas-Tutorial ändern. Nehmen wir das gleiche Beispiel, in dem ich die Spaltenüberschrift von 'Besucher' in 'Benutzer' ändern werde. Lassen Sie es mich also praktisch umsetzen.
Pandas importieren als pd df = pd.DataFrame ({'Tag': [1,2,3,4], 'Besucher': [200, 100,230,300], 'Bounce_Rate': [20,45,60,10]}) df = df.rename (Spalten = {'Besucher': 'Benutzer'}) print (df)Ausgabe:
Bounce_Rate Day Benutzer 0 20 1 200 1 45 2 100 2 60 3 230 3 10 4 300
Wie Sie oben sehen, wurde die Spaltenüberschrift 'Besucher' in 'Benutzer' geändert. Lassen Sie uns als nächstes im Python Pandas-Tutorial Datenmunging durchführen.
Jobtracker und Tasktracker in Hadoop
Daten Munging
In Data Munging können Sie bestimmte Daten in ein anderes Format konvertieren. Wenn Sie beispielsweise eine CSV-Datei haben, können Sie diese auch in HTML oder ein anderes Datenformat konvertieren. Lassen Sie mich dies praktisch umsetzen.
Pandas importieren als pd country = pd.read_csv ('D: UsersAayushiDownloadsworld-bank-JugendarbeitslosigkeitAPI_ILO_country_YU.csv', index_col = 0) country.to_html ('edu.html')Sobald Sie diesen Code ausführen, wird eine HTML-Datei mit dem Namen 'edu.html' erstellt. Sie können den Pfad der Datei direkt kopieren und in Ihren Browser einfügen, der die Daten in einem HTML-Format anzeigt. Siehe folgenden Screenshot:
Schauen wir uns als nächstes im Python Pandas-Tutorial einen Anwendungsfall an, der über die globale Jugendarbeitslosigkeit spricht.
Python Pandas Tutorial: Anwendungsfall zum Analysieren von Daten zur Jugendarbeitslosigkeit
Problemstellung ::Sie erhalten einen Datensatz, der umfasst den Prozentsatz der arbeitslosen Jugendlichen weltweit von 2010 bis 2014. Sie müssen diesen Datensatz verwenden und die Änderung des Prozentsatzes der Jugendlichen für jedes Land von 2010 bis 2011 ermitteln.
Lassen Sie uns zunächst den Datensatz verstehen, der die Spalten als Ländername, Ländercode und das Jahr von 2010 bis 2014 enthält. Bei Verwendung von Pandas verwenden wir jetzt 'pd.read_csv', um die CSV-Dateiformatdatei zu lesen.
Siehe den Screenshot unten:
Lassen Sie uns fortfahren und eine Datenanalyse durchführen, in der wir die prozentuale Veränderung der arbeitslosen Jugend zwischen 2010 und 2011 herausfinden werden. Dann werden wir dasselbe anhand von visualisieren Bibliothek, eine leistungsstarke Bibliothek zur Visualisierung in Python. Es kann in Python-Skripten, Shell, Webanwendungsservern und anderen GUI-Toolkits verwendet werden. Hier können Sie mehr lesen:
Lassen Sie uns nun den Code in PyCharm implementieren:
Pandas als pd importieren matplotlib.pyplot als plt aus matplotlib importieren style style style.use ('fünfunddreißig') country = pd.read_csv ('D: UsersAayushiDownloadsworld-bank-JugendarbeitslosigkeitAPI_ILO_country_YU.csv', index_col = 0) df = country. head (5) df = df.set_index (['Ländercode']) sd = sd.reindex (Spalten = ['2010', '2011']) db = sd.diff (Achse = 1) db.plot (Art = 'bar') plt.show ()Wie Sie oben sehen können, habe ich die Analyse in den oberen 5 Zeilen des Länderdatenrahmens durchgeführt. Als nächstes habe ich einen Indexwert als „Ländercode“ definiert und die Spalte dann auf 2010 und 2011 neu indiziert. Dann haben wir einen weiteren Datenrahmen db, der die Differenz zwischen den beiden Spalten oder die prozentuale Veränderung der arbeitslosen Jugend druckt von 2010 bis 2011. Schließlich habe ich ein Barplot mit der Matplotlib-Bibliothek in Python gezeichnet.
Wenn Sie in der obigen Darstellung zwischen 2010 und 2011 in Afghanistan (AFG) festgestellt haben, ist die Zahl der arbeitslosen Jugendlichen um rd. 0,25%. In Angola (AGO) gibt es dann einen negativen Trend, was bedeutet, dass der Prozentsatz der arbeitslosen Jugendlichen reduziert wurde. Ebenso können Sie verschiedene Datensätze analysieren.
Ich hoffe, mein Blog über 'Python Pandas Tutorial' war für Sie relevant. Um detaillierte Informationen zu Python und seinen verschiedenen Anwendungen zu erhalten, können Sie sich live anmelden von Edureka mit 24/7 Support und lebenslangem Zugriff.
Hast du eine Frage an uns? Bitte erwähnen Sie es im Kommentarbereich dieses Blogs „Python Pandas Tutorial“. Wir werden uns so schnell wie möglich bei Ihnen melden.