
Im Die Leistung eines Modells basiert auf seinen Vorhersagen und der Verallgemeinerung auf unsichtbare, unabhängige Daten. Eine Möglichkeit, die Genauigkeit eines Modells zu messen, besteht darin, die Verzerrung und Varianz im Modell zu berücksichtigen. In diesem Artikel erfahren Sie, wie die Bias-Varianz eine wichtige Rolle bei der Bestimmung der Authentizität des Modells spielt. Die folgenden Themen werden in diesem Artikel behandelt:
- Irreduzibler Fehler
- Was ist Bias beim maschinellen Lernen?
- Varianz in einem maschinellen Lernmodell?
- Wie wirkt es sich auf das Modell des maschinellen Lernens aus?
- Bias-Varianz-Kompromiss
- Gesamtfehler
Irreduzibler Fehler
Jedes Modell in wird basierend auf dem Vorhersagefehler in einem neuen unabhängigen, unsichtbaren Datensatz bewertet. Fehler ist nichts anderes als der Unterschied zwischen der tatsächlichen Ausgabe und der vorhergesagten Ausgabe. Um den Fehler zu berechnen, addieren wir den reduzierbaren und den nicht reduzierbaren Fehler a.k. eine Bias-Varianz-Zerlegung.
Irreversibler Fehler ist nichts anderes als der Fehler, der unabhängig von keinem reduziert werden kann die Sie im Modell verwenden. Dies wird durch ungewöhnliche Variablen verursacht, die einen direkten Einfluss auf die Ausgabevariable haben. Um Ihr Modell effizienter zu gestalten, bleibt uns der reduzierbare Fehler, den wir um jeden Preis optimieren müssen.
Ein reduzierbarer Fehler besteht aus zwei Komponenten: Bias und Varianz Das Vorhandensein von Verzerrung und Varianz beeinflusst die Genauigkeit des Modells auf verschiedene Weise Überanpassung, Unteranpassung , usw.Lassen Sie uns einen Blick auf Voreingenommenheit und Varianz werfen, um zu verstehen, wie mit dem reduzierbaren Fehler in umgegangen werden soll .
Was ist Bias beim maschinellen Lernen?
Bias ist im Grunde, wie weit wir den Wert vom tatsächlichen Wert vorhergesagt haben. Wir sagen, dass die Verzerrung zu hoch ist, wenn die durchschnittlichen Vorhersagen weit von den tatsächlichen Werten entfernt sind.
Eine hohe Vorspannung führt dazu, dass der Algorithmus ein dominantes Muster oder eine dominante Beziehung zwischen den Eingangs- und Ausgangsvariablen übersieht. Wenn die Verzerrung zu hoch ist, wird angenommen, dass das Modell recht einfach ist und die Komplexität des Datensatzes zur Bestimmung der Beziehung und damit nicht ergründet.Unteranpassung verursachen.
Varianz in einem maschinellen Lernmodell?
Auf einem unabhängigen, unsichtbaren Datensatz oder einem Validierungssatz. Wenn ein Modell nicht so gut funktioniert wie mit dem trainierten Datensatz, besteht die Möglichkeit, dass das Modell eine Varianz aufweist. Grundsätzlich wird angegeben, wie stark die vorhergesagten Werte von den tatsächlichen Werten gestreut sind.
Eine hohe Varianz in einem Datensatz bedeutet, dass das Modell mit viel Rauschen und irrelevanten Daten trainiert hat. Dies führt zu einer Überanpassung des Modells. Wenn ein Modell eine hohe Varianz aufweist, wird es sehr flexibel und macht falsche Vorhersagen für neue Datenpunkte. Weil es sich auf die Datenpunkte des Trainingssatzes eingestellt hat.
Versuchen wir auch, das Konzept der Bias-Varianz mathematisch zu verstehen. Lassen Sie die Variable, die wir als Y vorhersagen, und die anderen unabhängigen Variablen X sein. Nehmen wir nun an, dass es eine Beziehung zwischen den beiden Variablen gibt, so dass:
Was ist Ereignis in Javascript
Y = f (X) + e
In der obigen Gleichung hier ist ist der geschätzte Fehler mit einem Mittelwert 0. Wenn wir einen Klassifikator mit Algorithmen wie erstellen lineare Regression , usw. Der erwartete quadratische Fehler am Punkt x ist:
err (x) = Bias2+ Varianz + irreduzibler Fehler
Lassen Sie uns auch verstehen, wie sich die Bias-Varianz auf a auswirkt Maschinelles Lernen Leistung des Modells.
wie man double in java in int ändert
Wie wirkt es sich auf das Modell des maschinellen Lernens aus?
Wir können die Beziehung zwischen Bias-Varianz in vier unten aufgeführte Kategorien einteilen:
- Hohe Varianz - hohe Vorspannung - Das Modell ist inkonsistent und im Durchschnitt auch ungenau
- Geringe Varianz - hohe Vorspannung - Modelle sind konsistent, aber im Durchschnitt niedrig
- Hohe Varianz - niedrige Vorspannung - Etwas genau, aber im Durchschnitt inkonsistent
- Geringe Varianz - geringe Vorspannung - Dies ist das ideale Szenario. Das Modell ist im Durchschnitt konsistent und genau.
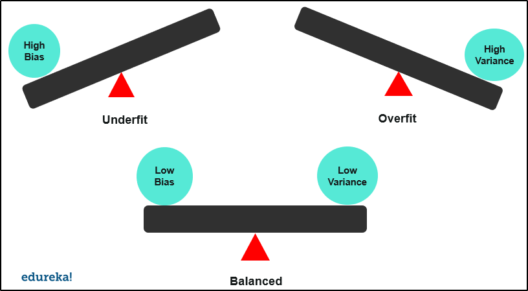
Obwohl das Erkennen von Verzerrung und Varianz in einem Modell ziemlich offensichtlich ist. Ein Modell mit hoher Varianz weist einen geringen Trainingsfehler und einen hohen Validierungsfehler auf. Und im Fall einer hohen Vorspannung weist das Modell einen hohen Trainingsfehler auf, und der Validierungsfehler ist der gleiche wie der Trainingsfehler.
Während das Erkennen einfach erscheint, besteht die eigentliche Aufgabe darin, es auf ein Minimum zu reduzieren. In diesem Fall können wir Folgendes tun:
- Fügen Sie weitere Eingabefunktionen hinzu
- Mehr Komplexität durch Einführung von Polynommerkmalen
- Regularisierungsdauer verringern
- Weitere Trainingsdaten erhalten
Nachdem wir nun wissen, was Verzerrung und Varianz sind und wie sie sich auf unser Modell auswirken, werfen wir einen Blick auf einen Kompromiss zwischen Verzerrung und Varianz.
Bias-Varianz-Kompromiss
Das richtige Gleichgewicht zwischen Bias und Varianz des Modells zu finden, wird als Bias-Varianz-Kompromiss bezeichnet. Dies ist im Grunde eine Möglichkeit, um sicherzustellen, dass das Modell in keinem Fall über- oder unterangepasst ist.
Wenn das Modell zu einfach ist und nur sehr wenige Parameter aufweist, leidet es unter einer hohen Vorspannung und einer geringen Varianz. Wenn das Modell andererseits eine große Anzahl von Parametern aufweist, weist es eine hohe Varianz und eine geringe Vorspannung auf. Dieser Kompromiss sollte zu einem perfekt ausgewogenen Verhältnis zwischen beiden führen. Im Idealfall ist eine geringe Verzerrung und geringe Varianz das Ziel für jedes Modell des maschinellen Lernens.
Gesamtfehler
In jedem Modell des maschinellen Lernens dient ein gutes Gleichgewicht zwischen Verzerrung und Varianz als perfektes Szenario hinsichtlich der Vorhersagegenauigkeit und der Vermeidung von Über- und Unteranpassung insgesamt. Ein optimales Gleichgewicht zwischen Bias und Varianz in Bezug auf die Komplexität des Algorithmus stellt sicher, dass das Modell niemals über- oder unterangepasst wird.
Der mittlere quadratische Fehler in einem statistischen Modell wird als die Summe aus quadratischer Abweichung und Varianz und Varianz des Fehlers betrachtet. All dies kann in einen Gesamtfehler eingefügt werden, bei dem es in einem Modell zu Verzerrungen, Varianz und irreduziblen Fehlern kommt.
Lassen Sie uns verstehen, wie wir den Gesamtfehler mithilfe einer praktischen Implementierung reduzieren können.
Wir haben eine erstellt linearer Regressionsklassifikator in dem Lineare Regression beim maschinellen Lernen Artikel über Edureka unter Verwendung des Diabetes-Datensatzes im Datensatzmodul von Scikit lernen Bibliothek.
Als wir den mittleren quadratischen Fehler des Klassifikators bewerteten, erhielten wir einen Gesamtfehler um 2500.
Um den Gesamtfehler zu reduzieren, haben wir dem Klassifikator mehr Daten zugeführt, und im Gegenzug wurde der mittlere quadratische Fehler auf 2000 reduziert.
Es ist eine einfache Implementierung zur Reduzierung des Gesamtfehlers, indem dem Modell mehr Trainingsdaten zugeführt werden. In ähnlicher Weise können wir andere Techniken anwenden, um den Fehler zu reduzieren und ein Gleichgewicht zwischen Verzerrung und Varianz für ein effizientes Modell des maschinellen Lernens aufrechtzuerhalten.
Dies bringt uns zum Ende dieses Artikels, wo wir Bias-Varianz in Mach gelernt habenine Lernen mit seiner Implementierung und Anwendungsfall. Ich hoffe, Sie sind mit allem klar, was Ihnen in diesem Tutorial mitgeteilt wurde.
Wenn Sie diesen Artikel zum Thema „Bias-Varianz beim maschinellen Lernen“ relevant fanden, lesen Sie die Ein vertrauenswürdiges Online-Lernunternehmen mit einem Netzwerk von mehr als 250.000 zufriedenen Lernenden auf der ganzen Welt.
Wir sind hier, um Ihnen bei jedem Schritt auf Ihrer Reise zu helfen und einen Lehrplan zu erstellen, der für Studenten und Fachleute konzipiert ist, die eine sein möchten . Der Kurs soll Ihnen einen Vorsprung in die Python-Programmierung verschaffen und Sie sowohl für Kern- als auch für fortgeschrittene Python-Konzepte sowie für verschiedene Konzepte schulen mögen , , usw.
Wenn Sie auf Fragen stoßen, können Sie diese gerne im Kommentarbereich von „Bias-Varianz beim maschinellen Lernen“ stellen. Unser Team beantwortet diese gerne.
mysql_fetch_array php