
Die logistische Regression in Python ist eine prädiktive Analysetechnik. Es wird auch beim maschinellen Lernen für binäre Klassifizierungsprobleme verwendet. In diesem Blog werden wir die folgenden Themen behandeln, um die logistische Regression in Python zu verstehen:
- Was ist Regression?
- Logistische Regression in Python
- Logistische Regression vs. lineare Regression
- Anwendungsfälle
- Demonstration
Sie können dieses ausführliche Tutorial zur logistischen Regression in Python auch mit einer Demonstration zum besseren Verständnis lesen oder die Anleitung durchgehen logistische Regression zu meistern.
Was ist Regression?
Die Analyse ist eine leistungsstarke statistische Analysetechnik. EIN abhängig Eine Variable von unserem Interesse wird verwendet, um die Werte anderer vorherzusagen unabhängige Variablen in einem Datensatz.
Wir stoßen die ganze Zeit auf intuitive Weise auf Regression. Wie die Vorhersage des Wetters anhand des Datensatzes der Wetterbedingungen in der Vergangenheit.
Es werden viele Techniken verwendet, um das Ergebnis zu analysieren und vorherzusagen, aber der Schwerpunkt liegt hauptsächlich auf Beziehung zwischen abhängiger Variable und einer oder mehreren unabhängigen Variablen.
Die Analyse sagt das Ergebnis in einer binären Variablen voraus, die nur zwei mögliche Ergebnisse hat.
Logistische Regression in Python
Es ist eine Technik zum Analysieren eines Datensatzes, der eine abhängige Variable und eine oder mehrere unabhängige Variablen enthält, um das Ergebnis in einer binären Variablen vorherzusagen, was bedeutet, dass es nur zwei Ergebnisse hat.
Die abhängige Variable ist kategorisch in der Natur. Die abhängige Variable wird auch als bezeichnet Zielvariable und die unabhängigen Variablen heißen die Prädiktoren .
Die logistische Regression ist ein Sonderfall der linearen Regression, bei dem wir das Ergebnis nur in einer kategorialen Variablen vorhersagen. Es sagt die Wahrscheinlichkeit des Ereignisses mithilfe der Protokollfunktion voraus.
Wir nehmen das Sigmoidfunktion / Kurve den kategorialen Wert vorherzusagen. Der Schwellenwert entscheidet über das Ergebnis (Gewinn / Verlust).
Lineare Regressionsgleichung: y = β0 + β1X1 + β2X2…. + βnXn
- Y steht für die abhängige Variable, die vorhergesagt werden muss.
- β0 ist der Y-Achsenabschnitt, der im Grunde der Punkt auf der Linie ist, der die y-Achse berührt.
- β1 ist die Steigung der Linie (die Steigung kann abhängig von der Beziehung zwischen der abhängigen Variablen und der unabhängigen Variablen negativ oder positiv sein.)
- X stellt hier die unabhängige Variable dar, die verwendet wird, um unseren resultierenden abhängigen Wert vorherzusagen.
Sigmoidfunktion: p = 1/1 + e-Y
Wenden Sie die Sigmoidfunktion auf die lineare Regressionsgleichung an.
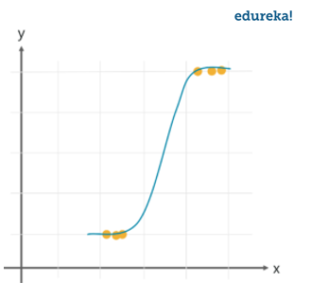
Logistische Regressionsgleichung: p = 1/1 + e- (β0 + β1X1 + β2X2…. + βnXn)
Schauen wir uns verschiedene Arten der logistischen Regression an.
Arten der logistischen Regression
Wirf Double in Java auf int
- Binäre logistische Regression - Es gibt nur zwei mögliche Ergebnisse. Beispiel - ja oder nein
- Multinomiale logistische Regression - Es gibt drei oder mehr nominelle Kategorien. Beispiel: Katze, Hund, Elefant.
- Ordinale logistische Regression - Es gibt drei oder mehr Ordnungskategorien, Ordnungszahl bedeutet, dass die Kategorien in einer Reihenfolge angeordnet sind. Beispiel - Benutzerbewertungen (1-5).
Lineare vs. logistische Regression
Während lineare Regression haben kann unendlich mögliche Werte, logistische Regression hat definitive Ergebnisse .
Die lineare Regression wird verwendet, wenn die Antwortvariable kontinuierlicher Natur ist, die logistische Regression wird jedoch verwendet, wenn die Antwortvariable kategorischer Natur ist.
Die Vorhersage eines Schuldners in einer Bank anhand der Transaktionsdetails in der Vergangenheit ist ein Beispiel für eine logistische Regression, während eine kontinuierliche Ausgabe wie ein Börsenwert ein Beispiel für eine lineare Regression ist.
Anwendungsfälle
Im Folgenden sind die Anwendungsfälle aufgeführt, in denen wir die logistische Regression verwenden können.
Wettervorhersage
Wettervorhersagen sind das Ergebnis einer logischen Regression. Hier analysieren wir die Daten der vorherigen Wetterberichte und sagen das mögliche Ergebnis für einen bestimmten Tag voraus. Eine logische Regression würde jedoch nur kategoriale Daten vorhersagen, beispielsweise ob es regnen wird oder nicht.
Krankheit bestimmen
Wir könnenverwendenlogische Regression mit Hilfe der Krankengeschichte des Patienten, um vorherzusagen, ob die Krankheit in jedem Fall positiv oder negativ ist.
Nehmen wir einen Beispieldatensatz, um ein Vorhersagemodell unter Verwendung der logistischen Regression zu erstellen.
Demo
Wir werden ein Vorhersagemodell erstellenmitlogische Regression in Python mit Hilfevonein Datensatz,in diesemWir werden die folgenden Schritte behandeln, um eine logische Regression zu erreichen.
Daten sammeln
Der allererste Schritt zur Implementierung der logistischen Regression ist die Erfassung der Daten. Wir werden die CSV-Datei mit dem Datensatz mithilfe der Pandas in die Programme laden. Wir verwenden die NBA-Daten zum Erstellen des Vorhersagemodells, um die Möglichkeit eines Heim- oder Auswärtsspiels vorherzusagen, indem wir die Beziehung zwischen den relevanten Daten analysieren.
Pandas als pd importieren numpy als np importieren seaborn als sns importieren matplotlib.pyplot als plt importieren df = pd.read_csv (r'C: UsersMohammadWaseemDocumentsdata.csv ') print (df.head (5))
Sie erhalten alle Daten zur einfacheren Analyse in einem lesbaren Format. Anschließend können Sie die abhängigen und unabhängigen Variablen für Ihr Modell ermitteln.
Daten analysieren
Der Datensatz wird analysiert, um die Beziehung zwischen den Variablen zu bestimmen. Durch Erstellen verschiedener Diagramme, um die Beziehung zwischen den Variablen zu überprüfen.
sns.countplot ('Home', hue = 'WINorLOSS', data = df) plt.show ()
konvertiere Binär in Integer Java
Oben ist die Beziehung zwischen dem Gewinn / Verlust-Prozentsatz in Bezug auf das Heim- / Auswärtsspiel. S.imilarWir können das Diagramm der Beziehung zwischen anderen relevanten Einträgen in den Daten zeichnen.
Daten-Wrangling
Der Datensatz wird entsprechend der Zielvariablen geändert. Wir werden alle Nullwerte und auch die Zeichenfolgenwerte aus dem DataFrame entfernen.
print (df.isnull (). sum ())
Wir werden nach allen irrelevanten Daten wie Nullwerten und den Werten suchen, die beim Erstellen des Vorhersagemodells nicht benötigt werden. Wenn das von uns verwendete NBA-Dataset keine Nullwerte enthält, werden wir mit der Aufteilung der Daten fortfahren.
Daten testen und trainieren
Für die Leistung des Modells werden die Daten in Testdaten und Zugdaten aufgeteilt. Die Daten werden mit dem aufgeteilt train_test_split . Die Daten hier sind im Verhältnis 70:30 aufgeteilt.
Nun zum Modellvorhersage Die logistische Regressionsfunktion wird durch Importieren des logistischen Regressionsmodells in das sklearn-Modul implementiert.
Das Modell wird dann mit der Anpassungsfunktion auf den Zug gesetzt. Danach wird die Vorhersage unter Verwendung der Vorhersagefunktion durchgeführt.
aus sklearn.model_selection import train_test_split aus sklearn.linear_model import LogisticRegression aus sklearn.metrics import klassifikationsbericht aus sklearn.metrics import verwirren_matrix, Genauigkeit_score x = df.drop ('Home', Achse = 1) y = df ['Home'] x_train, x_test, y_train, y_test = train_test_split (x, y, test_size = 0,33, random_state = 1) logmodel = LogisticRegression () logmodel.fit (x_train, y_train) Vorhersagen = logmodel.predict (x_test) print (Klassifizierungsbericht (y_test, Vorhersagen)) print (Verwirrungsmatrix (y_test, Vorhersagen)) print (Genauigkeitscore (y_test, Vorhersagen))
Klassifizierungsbericht:
Der Klassifizierungsbericht zeigt die Präzision , Rückruf, F1 und Support Punkte für das Modell.
Präzision Punktzahl bedeutet das Niveau, bis zu dem die vom Modell gemachte Vorhersage präzise ist. Die Präzision für ein Heimspiel ist 0,62 und für das auswärtsspiel ist 0,58 .
Erinnern ist der Betrag, bis zu dem das Modell das Ergebnis vorhersagen kann. Rückruf für ein Heimspiel ist 0,57 und für ein auswärtsspiel ist 0,64 . F1- und Support-Scores sind die Datenmenge, die für die Vorhersagen getestet wurde. Im NBA-Datensatz sind die für das Heimspiel getesteten Daten 1662 und für das auswärtsspiel ist 1586 .
Verwirrung Matrix:
Die Verwirrungsmatrix ist eine Tabelle, die die Leistung eines Vorhersagemodells beschreibt. Eine Verwirrungsmatrix enthält die tatsächlichen Werte und vorhergesagten Werte. Wir können diese Werte verwenden, um die Genauigkeitsbewertung des Modells zu berechnen.
Verwirrungsmatrix-Heatmap:
Zeichnen wir eine Heatmap der Verwirrungsmatrix mit seaborn und um das von uns erstellte Vorhersagemodell zu visualisieren. Um eine Heatmap zu zeichnen, ist die folgende Syntax erforderlich.
sns.heatmap (pd.DataFrame (verwirrungsmatrix (y_test, Vorhersagen))) plt.show ()
Wenn wir uns die Heatmap ansehen, können wir Folgendes schließen:
- Von allen Vorhersagen sagte der Klassifikator insgesamt 1730 Mal Ja voraus, von denen 1012 tatsächlich Ja waren.
- Von allen Vorhersagen sagte der Klassifikator insgesamt 1518 Mal Nein voraus, von denen 944 tatsächlich Nein waren.
Mit dieser Analyse der Verwirrungsmatrix können wir den Genauigkeitswert für unser Vorhersagemodell schließen.
Genauigkeitsbewertung:
Der Genauigkeitswert ist der Prozentsatz der Genauigkeit der vom Modell gemachten Vorhersagen. Für unser Modell beträgt der Genauigkeitswert 0,60, was sehr genau ist. Aber je höher die Genauigkeit, desto effizienter ist Ihr Vorhersagemodell. Sie müssen immer eine höhere Genauigkeit für ein besseres Vorhersagemodell anstreben.
Durch Befolgen der oben beschriebenen Schritte haben wir die Möglichkeit eines Heim- / Auswärtsspiels unter Verwendung des NBA-Datensatzes vorhergesagt. Nach der Analyse des Klassifizierungsberichts können wir die Möglichkeit eines Heim- / Auswärtsspiels annehmen.
In diesem Blog haben wir die logistische Regression in Python-Konzepten diskutiert, wie sie sich vom linearen Ansatz unterscheidet. Außerdem haben wir eine Demonstration mit dem NBA-Datensatz behandelt. Für mehr Einblick und Übung können Sie ein Dataset Ihrer Wahl verwenden und die beschriebenen Schritte ausführen, um die logistische Regression in Python zu implementieren.
Schauen Sie sich auch die verschiedenen Data-Science-Blogs auf der edureka-Plattform an, um den Data Scientist in Ihnen zu beherrschen.
Wenn Sie Python lernen und eine Karriere in der Datenwissenschaft aufbauen möchten, schauen Sie sich unser interaktives Live-Online an Hier finden Sie rund um die Uhr Unterstützung, die Sie während Ihrer gesamten Lernphase begleitet.
Hast du eine Frage? Bitte erwähnen Sie es in den Kommentaren und wir werden uns bei Ihnen melden.