
Einführung in Markov-Ketten:
Haben Sie sich jemals gefragt, wie Google Webseiten einstuft? Wenn Sie Ihre Recherchen durchgeführt haben, müssen Sie wissen, dass der PageRank-Algorithmus verwendet wird, der auf der Idee von Markov-Ketten basiert. Dieser Artikel über die Einführung in Markov-Ketten hilft Ihnen dabei, die Grundidee hinter Markov-Ketten zu verstehen und zu verstehen, wie sie als Lösung für reale Probleme modelliert werden können.
Hier ist eine Liste der Themen, die behandelt werden in diesem Blog:
- Was ist eine Markov-Kette?
- Was ist die Markov-Eigenschaft?
- Markov-Ketten anhand eines Beispiels verstehen
- Was ist eine Übergangsmatrix?
- Markov-Kette in Python
- Markov-Kettenanwendungen
Um detaillierte Informationen zu Data Science und maschinellem Lernen mit Python zu erhalten, können Sie sich live anmelden von Edureka mit 24/7 Support und lebenslangem Zugriff.
Was ist eine Markov-Kette?
Andrey Markov führte die Markov-Ketten erstmals im Jahr 1906 ein. Er erklärte Markov-Ketten wie folgt:
Ein stochastischer Prozess, der Zufallsvariablen enthält und abhängig von bestimmten Annahmen und bestimmten Wahrscheinlichkeitsregeln von einem Zustand in einen anderen übergeht.
Diese zufällig Variablen wechseln von einem Zustand zum anderen, basierend auf einer wichtigen mathematischen Eigenschaft namens Markov Eigentum.
Dies bringt uns zu der Frage:
Was ist die Markov-Eigenschaft?
Die diskrete Zeit-Markov-Eigenschaft besagt, dass die berechnete Wahrscheinlichkeit eines zufälligen Prozesses, der in den nächstmöglichen Zustand übergeht, nur vom aktuellen Zustand und der aktuellen Zeit abhängt und unabhängig von der Reihe von Zuständen ist, die ihm vorausgingen.
Die Tatsache, dass die nächstmögliche Aktion / der nächstmögliche Zustand eines zufälligen Prozesses nicht von der Folge vorheriger Zustände abhängt, macht Markov-Ketten zu einem speicherlosen Prozess, der ausschließlich vom aktuellen Zustand / der aktuellen Aktion einer Variablen abhängt.
Lassen Sie uns dies mathematisch ableiten:
Der Zufallsprozess sei {Xm, m = 0,1,2, ⋯}.
Dieser Prozess ist nur dann eine Markov-Kette, wenn,
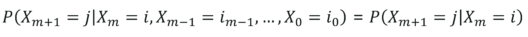
Markov-Kette - Einführung in Markov-Ketten - Edureka
für alle m, j, i, i0, i1, ⋯ im & minus1
Für eine endliche Anzahl von Zuständen, S = {0, 1, 2, ⋯, r}, wird dies eine endliche Markov-Kette genannt.
P (Xm + 1 = j | Xm = i) repräsentiert hier die Übergangswahrscheinlichkeiten für den Übergang von einem Zustand in den anderen. Hier gehen wir davon aus, dass die Übergangswahrscheinlichkeiten zeitunabhängig sind.
Dies bedeutet, dass P (Xm + 1 = j | Xm = i) nicht vom Wert von 'm' abhängt. Daher können wir zusammenfassen,
Markov-Kettenformel - Einführung in Markov-Ketten - Edureka
Diese Gleichung repräsentiert also die Markov-Kette.
Lassen Sie uns nun anhand eines Beispiels verstehen, was genau Markov-Ketten sind.
Markov-Kettenbeispiel
Bevor ich Ihnen ein Beispiel gebe, definieren wir, was ein Markov-Modell ist:
Was ist ein Markov-Modell?
Ein Markov-Modell ist ein stochastisches Modell, das Zufallsvariablen so modelliert, dass die Variablen der Markov-Eigenschaft folgen.
Lassen Sie uns nun anhand eines einfachen Beispiels verstehen, wie ein Markov-Modell funktioniert.
Wie bereits erwähnt, werden Markov-Ketten in Anwendungen zur Texterzeugung und automatischen Vervollständigung verwendet. In diesem Beispiel sehen wir uns einen (zufälligen) Beispielsatz an und sehen, wie er mithilfe von Markov-Ketten modelliert werden kann.
Markov-Kettenbeispiel - Einführung in Markov-Ketten - Edureka
Der obige Satz ist unser Beispiel. Ich weiß, dass er nicht viel Sinn macht (er muss nicht). Es ist ein Satz, der zufällige Wörter enthält, wobei:
Schlüssel bezeichnen die eindeutigen Wörter im Satz, d. h. 5 Schlüssel (eins, zwei, Hagel, glücklich, edureka)
Token bezeichnen die Gesamtzahl von Wörtern, d. h. 8 Token.
In Zukunft müssen wir die Häufigkeit des Auftretens dieser Wörter verstehen. Das folgende Diagramm zeigt jedes Wort zusammen mit einer Zahl, die die Häufigkeit dieses Wortes angibt.
Schlüssel und Frequenzen - Einführung in Markov-Ketten - Edureka
Die linke Spalte hier bezeichnet also die Tasten und die rechte Spalte bezeichnet die Frequenzen.
Aus der obigen Tabelle können wir schließen, dass der Schlüssel „edureka“ viermal so häufig vorkommt wie jeder andere Schlüssel. Es ist wichtig, auf solche Informationen zu schließen, da dies uns helfen kann, vorherzusagen, welches Wort zu einem bestimmten Zeitpunkt vorkommen könnte. Wenn ich das nächste Wort im Beispielsatz erraten würde, würde ich mich für „edureka“ entscheiden, da es die höchste Wahrscheinlichkeit des Auftretens aufweist.
In Bezug auf die Wahrscheinlichkeit ist eine weitere Maßnahme, die Sie kennen müssen, die gewichtete Verteilungen.
In unserem Fall beträgt die gewichtete Verteilung für „edureka“ 50% (4/8), da die Häufigkeit 4 von insgesamt 8 Token beträgt. Die restlichen Schlüssel (eins, zwei, Hagel, glücklich) haben alle eine 1/8-Chance (& asymp 13%).
Nachdem wir die gewichtete Verteilung verstanden haben und eine Vorstellung davon haben, wie bestimmte Wörter häufiger vorkommen als andere, können wir mit dem nächsten Teil fortfahren.
Markov-Ketten verstehen - Einführung in Markov-Ketten - Edureka
In der obigen Abbildung habe ich zwei zusätzliche Wörter hinzugefügt, die den Anfang und das Ende des Satzes bezeichnen. Sie werden im folgenden Abschnitt verstehen, warum ich dies getan habe.
Weisen wir nun auch diesen Tasten die Frequenz zu:
Aktualisierte Schlüssel und Frequenzen - Einführung in Markov-Ketten - Edureka
Erstellen wir nun ein Markov-Modell. Wie bereits erwähnt, wird ein Markov-Modell verwendet, um Zufallsvariablen in einem bestimmten Zustand so zu modellieren, dass die zukünftigen Zustände dieser Variablen ausschließlich von ihrem aktuellen Zustand und nicht von ihren vergangenen Zuständen abhängen.
Grundsätzlich müssen wir in einem Markov-Modell nur den aktuellen Zustand berücksichtigen, um den nächsten Zustand vorherzusagen.
In der folgenden Abbildung können Sie sehen, wie jedes Token in unserem Satz zu einem anderen führt. Dies zeigt, dass der zukünftige Status (nächstes Token) auf dem aktuellen Status (aktuelles Token) basiert. Dies ist also die grundlegendste Regel im Markov-Modell.
Das folgende Diagramm zeigt, dass es Token-Paare gibt, bei denen jedes Token im Paar zum anderen im selben Paar führt.
Markov-Kettenpaare - Einführung in Markov-Ketten - Edureka
Im folgenden Diagramm habe ich eine strukturelle Darstellung erstellt, die jeden Schlüssel mit einem Array von möglichen Token zeigt, mit denen er gekoppelt werden kann.
Eine Reihe von Markov-Kettenpaaren - Einführung in Markov-Ketten - Edureka
Um dieses Beispiel zusammenzufassen, stellen Sie sich ein Szenario vor, in dem Sie einen Satz bilden müssen, indem Sie das Array von Schlüsseln und Token verwenden, das wir im obigen Beispiel gesehen haben. Bevor wir dieses Beispiel durchgehen, ist ein weiterer wichtiger Punkt, dass wir zwei anfängliche Maßnahmen angeben müssen:
Eine anfängliche Wahrscheinlichkeitsverteilung (d. H. Der Startzustand zum Zeitpunkt = 0, (Starttaste))
Eine Übergangswahrscheinlichkeit für den Sprung von einem Zustand in einen anderen (in diesem Fall die Wahrscheinlichkeit für den Übergang von einem Token zum anderen)
php.mysql_fetch_array
Wir haben die gewichtete Verteilung am Anfang selbst definiert, haben also die Wahrscheinlichkeiten und den Anfangszustand. Fahren wir nun mit dem Beispiel fort.
Der erste Token lautet also [Start].
Als nächstes haben wir nur ein mögliches Token, d. H. [Eins]
Derzeit enthält der Satz nur ein Wort, d. H. 'Eins'.
Von diesem Token ist das nächste mögliche Token [edureka]
Der Satz wird auf „ein Edureka“ aktualisiert.
Von [edureka] können wir zu einem der folgenden Token wechseln [zwei, Hagel, glücklich, Ende]
Es besteht eine 25% ige Wahrscheinlichkeit, dass „zwei“ ausgewählt werden. Dies würde möglicherweise zur Bildung des ursprünglichen Satzes führen (ein Edureka, zwei Edureka, Hagel, Edureka, Happy Edureka). Wenn jedoch 'Ende' ausgewählt wird, stoppt der Prozess und wir generieren am Ende einen neuen Satz, d. H. 'Ein Edureka'.
Gönnen Sie sich einen Klaps auf den Rücken, weil Sie gerade ein Markov-Modell gebaut und einen Testfall durchlaufen haben. Um das obige Beispiel zusammenzufassen, haben wir grundsätzlich den gegenwärtigen Zustand (gegenwärtiges Wort) verwendet, um den nächsten Zustand (nächstes Wort) zu bestimmen. Und genau das ist ein Markov-Prozess.
Es ist ein stochastischer Prozess, bei dem Zufallsvariablen von einem Zustand in den anderen übergehen, so dass der zukünftige Zustand einer Variablen nur vom gegenwärtigen Zustand abhängt.
Fahren wir mit dem nächsten Schritt fort und zeichnen Sie das Markov-Modell für dieses Beispiel.
Zustandsübergangsdiagramm - Einführung in Markov-Ketten - Edureka
Die obige Abbildung ist als Zustandsübergangsdiagramm bekannt. Wir werden im folgenden Abschnitt mehr darüber sprechen. Denken Sie vorerst daran, dass dieses Diagramm die Übergänge und die Wahrscheinlichkeit von einem Zustand in einen anderen zeigt.
Beachten Sie, dass jedes Oval in der Abbildung einen Schlüssel darstellt und die Pfeile auf die möglichen Schlüssel gerichtet sind, die ihm folgen können. Auch die Gewichte auf den Pfeilen bezeichnen die Wahrscheinlichkeit oder die gewichtete Verteilung des Übergangs von / zu den jeweiligen Zuständen.
Das war also alles darüber, wie das Markov-Modell funktioniert. Versuchen wir nun, einige wichtige Terminologien im Markov-Prozess zu verstehen.
Was ist eine Übergangswahrscheinlichkeitsmatrix?
Im obigen Abschnitt haben wir die Arbeitsweise eines Markov-Modells anhand eines einfachen Beispiels erläutert. Lassen Sie uns nun die mathematischen Terminologien in einem Markov-Prozess verstehen.
In einem Markov-Prozess verwenden wir eine Matrix, um die Übergangswahrscheinlichkeiten von einem Zustand in einen anderen darzustellen. Diese Matrix wird als Übergangs- oder Wahrscheinlichkeitsmatrix bezeichnet. Es wird normalerweise mit P. bezeichnet.
Übergangsmatrix - Einführung in Markov-Ketten - Edureka
Beachten Sie, dass pij & ge0 und 'i' für alle Werte Folgendes sind:
Übergangsmatrixformel - Einführung in Markov-Ketten - Edureka
Lassen Sie mich das erklären. Unter der Annahme, dass unser aktueller Zustand 'i' ist, muss der nächste oder bevorstehende Zustand einer der potenziellen Zustände sein. Daher müssen wir, während wir die Summe aller Werte von k nehmen, einen erhalten.
Was ist ein Zustandsübergangsdiagramm?
Ein Markov-Modell wird durch ein Zustandsübergangsdiagramm dargestellt. Das Diagramm zeigt die Übergänge zwischen den verschiedenen Zuständen in einer Markov-Kette. Lassen Sie uns die Übergangsmatrix und die Zustandsübergangsmatrix anhand eines Beispiels verstehen.
Beispiel für eine Übergangsmatrix
Betrachten Sie eine Markov-Kette mit drei Zuständen 1, 2 und 3 und den folgenden Wahrscheinlichkeiten:
Beispiel für eine Übergangsmatrix - Einführung in Markov-Ketten - Edureka
Beispiel für ein Zustandsübergangsdiagramm - Einführung in Markov-Ketten - Edureka
Das obige Diagramm zeigt das Zustandsübergangsdiagramm für die Markov-Kette. Hier sind 1,2 und 3 die drei möglichen Zustände, und die Pfeile, die von einem Zustand zu den anderen Zuständen zeigen, repräsentieren die Übergangswahrscheinlichkeiten pij. Wenn pij = 0 ist, bedeutet dies, dass es keinen Übergang zwischen dem Zustand 'i' und dem Zustand 'j' gibt.
Jetzt wo wir Kennen Sie die Mathematik und die Logik hinter Markov-Ketten, führen Sie eine einfache Demo durch und verstehen Sie, wo Markov-Ketten verwendet werden können.
Markov-Kette in Python
Um diese Demo auszuführen, verwende ich Python. Wenn Sie Python nicht kennen, können Sie die folgenden Blogs durchgehen:
Beginnen wir jetzt mit dem Codieren!
Markov Chain Text Generator
Problemstellung: Anwenden der Markov-Eigenschaft und Erstellen eines Markov-Modells, mit dem Textsimulationen generiert werden können, indem der Donald Trump-Sprachdatensatz untersucht wird.
Datensatzbeschreibung: Die Textdatei enthält eine Liste der Reden, die Donald Trump 2016 gehalten hat.
Logik: Wenden Sie die Markov-Eigenschaft an, um Donalds Trumps Rede zu generieren, indem Sie jedes in der Rede verwendete Wort berücksichtigen und für jedes Wort ein Wörterbuch mit Wörtern erstellen, die als Nächstes verwendet werden.
Schritt 1: Importieren Sie die erforderlichen Pakete
importiere numpy als np
Schritt 2: Lesen Sie den Datensatz
trump = open ('C: //Users//NeelTemp//Desktop//demos//speeches.txt', encoding = 'utf8'). read () #display the data print (trump) SPEECH 1 ... Danke dich so sehr. Das ist so nett. Ist er nicht ein toller Kerl? Er bekommt keine faire Presse, er bekommt sie nicht. Es ist einfach nicht fair. Und ich muss Ihnen sagen, dass ich hier und sehr stark hier bin, weil ich großen Respekt vor Steve King habe und ebenso großen Respekt vor Citizens United, David und allen und einen enormen Respekt vor der Tea Party. Auch die Leute von Iowa. Sie haben etwas gemeinsam. Hart arbeitende Leute....Schritt 3: Teilen Sie den Datensatz in einzelne Wörter auf
corpus = trump.split () # Zeigt den Korpusdruck (Corpus) 'mächtig', 'aber', 'nicht', 'mächtig', 'wie', 'wir', 'Iran', 'hat', 'an. gesät ',' Terror ', ...
Erstellen Sie als Nächstes eine Funktion, die die verschiedenen Wortpaare in den Reden generiert. Um Platz zu sparen, verwenden wir ein Generatorobjekt.
Schritt 4: Erstellen von Paaren zu Schlüsseln und den folgenden Wörtern
def make_pairs (Korpus): für i im Bereich (len (Korpus) - 1): Ausbeute (Korpus [i], Korpus [i + 1]) Paare = make_pairs (Korpus)
Als nächstes initialisieren wir ein leeres Wörterbuch, um die Wortpaare zu speichern.
Wenn das erste Wort im Paar bereits ein Schlüssel im Wörterbuch ist, fügen Sie einfach das nächste potenzielle Wort an die Liste der Wörter an, die auf das Wort folgen. Wenn das Wort jedoch kein Schlüssel ist, erstellen Sie einen neuen Eintrag im Wörterbuch und weisen Sie den Schlüssel dem ersten Wort im Paar zu.
Schritt 5: Anhängen des Wörterbuchs
word_dict = {} für word_1, word_2 paarweise: wenn word_1 in word_dict.keys (): word_dict [word_1] .append (word_2) else: word_dict [word_1] = [word_2]Als nächstes wählen wir zufällig ein Wort aus dem Korpus aus, das die Markov-Kette startet.
Schritt 6: Erstellen Sie das Markov-Modell
# wähle zufällig das erste Wort aus first_word = np.random.choice (Korpus) #Wähle das erste Wort als großgeschriebenes Wort aus, damit das ausgewählte Wort nicht zwischen einem Satz entnommen wird, während first_word.islower (): #Start die Kette von die ausgewählte Wortkette = [first_word] #Initialisieren Sie die Anzahl der stimulierten Wörter n_words = 20
Nach dem ersten Wort wird jedes Wort in der Kette zufällig aus der Liste der Wörter ausgewählt, die diesem bestimmten Wort in Trumps Live-Reden gefolgt sind. Dies wird im folgenden Codeausschnitt gezeigt:
für i im Bereich (n_words): chain.append (np.random.choice (word_dict [chain [-1]]))
Schritt 7: Vorhersagen
Lassen Sie uns abschließend den stimulierten Text anzeigen.
#Join gibt die Kette als Zeichenfolgendruck zurück ('' .join (Kette)) Die Anzahl der unglaublichen Personen. Und Hillary Clinton hat unsere Leute und einen so tollen Job. Und wir werden Obama nicht schlagenDas ist also der generierte Text, den ich erhalten habe, als ich Trumps Rede betrachtet habe. Es macht vielleicht nicht viel Sinn, aber es ist gut genug, um zu verstehen, wie Markov-Ketten verwendet werden können, um automatisch Texte zu generieren.
Schauen wir uns nun einige weitere Anwendungen an von Markov-Ketten und wie sie zur Lösung realer Probleme verwendet werden.
Markov-Kettenanwendungen
Hier ist eine Liste realer Anwendungen von Markov-Ketten:
Google PageRank: Das gesamte Web kann als Markov-Modell betrachtet werden, wobei jede Webseite ein Zustand sein kann und die Links oder Verweise zwischen diesen Seiten als Übergänge mit Wahrscheinlichkeiten betrachtet werden können. Unabhängig davon, auf welcher Webseite Sie mit dem Surfen beginnen, ist die Chance, zu einer bestimmten Webseite zu gelangen, beispielsweise X, eine feste Wahrscheinlichkeit.
Eingabe der Wortvorhersage: Es ist bekannt, dass Markov-Ketten zur Vorhersage kommender Wörter verwendet werden. Sie können auch zur automatischen Vervollständigung und für Vorschläge verwendet werden.
Subreddit-Simulation: Sicherlich sind Sie auf Reddit gestoßen und hatten eine Interaktion mit einem ihrer Threads oder Subreddits. Reddit verwendet einen Subreddit-Simulator, der eine große Datenmenge verbraucht, die alle Kommentare und Diskussionen enthält, die in den Gruppen geführt werden. Mithilfe von Markov-Ketten erzeugt der Simulator Wort-zu-Wort-Wahrscheinlichkeiten, um Kommentare und Themen zu erstellen.
Textgenerator: Markov-Ketten werden am häufigsten verwendet, um Dummy-Texte zu generieren oder große Aufsätze zu erstellen und Reden zu kompilieren. Es wird auch in den Namensgeneratoren verwendet, die Sie im Web sehen.
Jetzt, da Sie wissen, wie Sie ein reales Problem mithilfe von Markov-Ketten lösen können, sind Sie sicher neugierig, mehr zu erfahren. Hier ist eine Liste von Blogs, die Ihnen den Einstieg in andere statistische Konzepte erleichtern:
Damit sind wir am Ende dieses Blogs zur Einführung in Markov-Ketten angelangt. Wenn Sie Fragen zu diesem Thema haben, hinterlassen Sie bitte unten einen Kommentar. Wir werden uns dann bei Ihnen melden.
Weitere Blogs zu den Trendtechnologien finden Sie hier.
Wenn Sie nach einer strukturierten Online-Schulung in Data Science suchen, ist edureka! hat eine speziell kuratierte Programm, mit dem Sie Fachwissen in den Bereichen Statistik, Daten-Wrangling, explorative Datenanalyse, Algorithmen für maschinelles Lernen wie K-Means-Clustering, Entscheidungsbäume, Random Forest und Naive Bayes erwerben können. Sie lernen auch die Konzepte von Zeitreihen, Text Mining und eine Einführung in Deep Learning. Neue Chargen für diesen Kurs beginnen bald !!