
Web Scraping ist ein effektiver Weg, um Daten von den Webseiten zu sammeln. Es ist ein effektives Werkzeug in geworden . Mit verschiedenen Bibliotheken vorhanden für Web Scraping wie wird die Arbeit eines Datenwissenschaftlers optimal. Scrapy ist ein leistungsstarkes Webframework zum Extrahieren, Verarbeiten und Speichern von Daten. In diesem Scrapy-Tutorial erfahren Sie, wie wir einen Webcrawler erstellen können. Die folgenden Themen werden in diesem Blog behandelt:
- Was ist Scrapy?
- Was ist ein Webcrawler?
- Wie installiere ich Scrapy?
- Starten Sie Ihr erstes Scrapy-Projekt
- Machen Sie Ihre erste Spinne
- Daten extrahieren
- Speichern der extrahierten Daten
Was ist Scrapy?
Scrapy ist ein kostenloses Open-Source-Webcrawling-Framework, das in Python geschrieben wurde. Es wurde ursprünglich entwickelt, um durchzuführen , kann aber auch zum Extrahieren von Daten mithilfe von APIs verwendet werden. Es wird von Scrapinghub Ltd. gepflegt.
Scrapy ist ein Komplettpaket zum Herunterladen der Webseiten, Verarbeiten und Speichern der Daten auf der .
Fibonacci c ++ Rekursion
Es ist wie ein Kraftpaket, wenn es um Web-Scraping mit mehreren Möglichkeiten zum Scrapen einer Website geht. Scrapy erledigt größere Aufgaben mühelos und kratzt mehrere Seiten oder eine Gruppe von URLs in weniger als einer Minute. Es wird ein Twister verwendet, der asynchron arbeitet, um Parallelität zu erreichen.
Es bietet Spinnenverträge, mit denen wir sowohl generische als auch Deep Crawler erstellen können. Scrapy bietet auch Element-Pipelines zum Erstellen von Funktionen in einer Spinne, die verschiedene Vorgänge ausführen können, z. B. das Ersetzen von Werten in Daten usw.
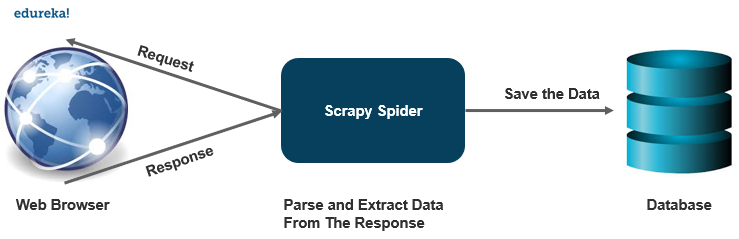
Was ist ein Web-Crawler?
Ein Webcrawler ist ein Programm, das automatisch nach Dokumenten im Web sucht. Sie sind hauptsächlich für sich wiederholende Aktionen zum automatisierten Durchsuchen programmiert.
Wie es funktioniert?
Ein Webcrawler ist einem Bibliothekar ziemlich ähnlich. Es sucht nach den Informationen im Web, kategorisiert die Informationen und indiziert und katalogisiert die Informationen für die gecrawlten Informationen, die entsprechend abgerufen und gespeichert werden sollen.
Die Operationen, die vom Crawler ausgeführt werden, werden zuvor erstellt. Anschließend führt der Crawler alle Operationen automatisch aus, wodurch ein Index erstellt wird. Auf diese Indizes kann von einer Ausgabesoftware zugegriffen werden.
Schauen wir uns verschiedene Anwendungen an, für die ein Webcrawler verwendet werden kann:
Preisvergleichsportale suchen nach bestimmten Produktdetails, um mithilfe eines Webcrawlers einen Preisvergleich auf verschiedenen Plattformen durchzuführen.
Ein Webcrawler spielt im Bereich Data Mining eine sehr wichtige Rolle für das Abrufen von Informationen.
Datenanalysetools verwenden Webcrawler, um die Daten auch für Seitenaufrufe, eingehende und ausgehende Links zu berechnen.
Crawler dienen auch als Informationsdrehkreuze, um Daten wie Nachrichtenportale zu sammeln.
Wie installiere ich Scrapy?
Um Scrapy auf Ihrem System zu installieren, wird empfohlen, es auf einer dedizierten virtuellen Umgebung zu installieren. Die Installation funktioniert ziemlich ähnlich wie jedes andere Paket in Python, wenn Sie verwenden conda Verwenden Sie zum Installieren von Scrapy den folgenden Befehl:
conda install -c conda-forge kratzig
Sie können auch die Pip-Umgebung verwenden, um Scrapy zu installieren.
Pip installieren Scrapy
Abhängig von Ihrem Betriebssystem kann es einige Kompilierungsabhängigkeiten geben. Scrapy ist in reinem Python geschrieben und kann von einigen Python-Paketen abhängen, wie:
lxml - Es ist ein effizienter XML- und HTML-Parser.
Paket - Eine HTML / XML-Extraktionsbibliothek, die oben auf lxml geschrieben ist
W3lib - Es ist ein Mehrzweck-Helfer für den Umgang mit URLs und Webseitencodierungen
Twisted - Ein asynchrones Netzwerkframework
Kryptographie - Hilft bei verschiedenen Sicherheitsanforderungen auf Netzwerkebene
Starten Sie Ihr erstes Scrapy-Projekt
Um Ihr erstes Scrapy-Projekt zu starten, gehen Sie zu dem Verzeichnis oder Speicherort, in dem Sie Ihre Dateien speichern möchten, und führen Sie den folgenden Befehl aus
Scrapy Startprojekt Projektname
Nachdem Sie diesen Befehl ausgeführt haben, werden die folgenden Verzeichnisse an diesem Speicherort erstellt.
Projektname/
Scrapy.cfg: Es wird eine Konfigurationsdatei bereitgestellt
Projektname/
__init__.py: Python-Modul des Projekts
items.py: Definitionsdatei für Projektelemente
middlewares.py: Projekt Middlewares-Datei
pipelines.py: Projekt-Pipelines-Datei
settings.py: Projekteinstellungsdatei
Spinnen /
__init__.py: Ein Verzeichnis, in das Sie später Ihre Spinnen legen werden
Machen Sie Ihre erste Spinne
Spinnen sind Klassen, die wir definieren und die Scrapy verwendet, um Informationen aus dem Web zu sammeln. Sie müssen Scrapy.Spider unterordnen und die ersten Anforderungen definieren.
Sie schreiben den Code für Ihre Spinne in eine separate Python-Datei und speichern ihn im Verzeichnis Projektname / Spinnen in Ihrem Projekt.
quote_spider.py
Scrapy-Klasse importieren QuotesSpider (Scrapy.Spider): name = 'quote' def start_request (self): urls = ['http://quotes.toscrape.com/page/1/', http://quotes.toscrape.com / page / 2 /,] für URL in URLs: Yield Scrapy.Request (URL = URL, Rückruf = self.parse) def Analyse (Selbst, Antwort): Seite = Antwort.url.split ('/') [- 2 ] Dateiname = 'Quotes-% s.html'% Seite mit open (Dateiname, 'wb') als f: f.write (response.body) self.log ('gespeicherte Datei% s'% Dateiname)Wie Sie sehen können, haben wir verschiedene Funktionen in unseren Spinnen definiert.
Name: Er identifiziert die Spinne und muss im gesamten Projekt eindeutig sein.
start_requests (): Muss eine Iterable von Anforderungen zurückgeben, mit denen die Spinne zu crawlen beginnt.
parse (): Dies ist eine Methode, die aufgerufen wird, um die bei jeder Anforderung heruntergeladene Antwort zu verarbeiten.
Daten extrahieren
Bisher extrahiert die Spinne keine Daten, sondern speichert nur die gesamte HTML-Datei. Eine Scrapy-Spinne generiert normalerweise viele Wörterbücher, die die aus der Seite extrahierten Daten enthalten. Wir verwenden das Rückgabeschlüsselwort in Python im Rückruf, um die Daten zu extrahieren.
Scrapy-Klasse importieren QuotesSpider (Scrapy.Spider): name = 'quote' start_urls = [http://quotes.toscrape.com/page/1/ ', http://quotes.toscrape.com/page/2/,] def parse (self, response): für Zitat in response.css ('div.quote'): Ausbeute {'text': quote.css (span.text :: text '). get (),' author ': quote .css (small.author::text ') get (),' tags ': quote.css (div.tags a.tag :: text'). getall ()}Wenn Sie diesen Spider ausführen, werden die extrahierten Daten mit dem Protokoll ausgegeben.
Speichern der Daten
Der einfachste Weg, die extrahierten Daten zu speichern, ist die Verwendung von Feed-Exporten. Verwenden Sie den folgenden Befehl, um Ihre Daten zu speichern.
Scrapy Crawl Quotes -o Quotes.json
Dieser Befehl generiert eine quote.json-Datei, die alle in serialisierten Elemente enthält JSON .
Dies bringt uns zum Ende dieses Artikels, wo wir gelernt haben, wie wir einen Webcrawler mit Scrapy in Python erstellen können, um eine Website zu kratzen und die Daten in eine JSON-Datei zu extrahieren. Ich hoffe, Sie sind mit allem klar, was in diesem Tutorial mit Ihnen geteilt wurde.
Wenn Sie diesen Artikel in 'Scrapy Tutorial' relevant fanden, lesen Sie die Ein vertrauenswürdiges Online-Lernunternehmen mit einem Netzwerk von mehr als 250.000 zufriedenen Lernenden auf der ganzen Welt.
Wir sind hier, um Ihnen bei jedem Schritt auf Ihrer Reise zu helfen und einen Lehrplan zu erstellen, der für Studenten und Fachleute konzipiert ist, die eine sein möchten . Der Kurs soll Ihnen einen Vorsprung in die Python-Programmierung verschaffen und Sie sowohl für grundlegende als auch für fortgeschrittene Python-Konzepte sowie für verschiedene Konzepte schulen mögen
Wenn Sie auf Fragen stoßen, können Sie alle Ihre Fragen im Kommentarbereich des „Scrapy Tutorial“ stellen. Unser Team beantwortet diese gerne.