
'
Die rasche Erweiterung digitaler Daten durch Computer, Mobilgeräte, Videos, soziale Medien, digitale Sensoren usw. in Verbindung mit bedeutenden Durchbrüchen bei kostengünstigerer Verarbeitungsleistung, Open-Source-Datenbankanwendungen und größerer Bandbreite hat in der gesamten Geschäftswelt ein massives Interesse geweckt aufstrebendes Gebiet der Big Data-Wissenschaft und Analytik.
Big Data in großen unstrukturierten Volumina sind zu groß, um mit herkömmlichen Methoden verwaltet und analysiert zu werden. Die schiere Menge und Geschwindigkeit der heutigen Daten macht das Erfassen, Filtern, Speichern und Analysieren zu einer echten Herausforderung. Um dies zu bewältigen, werden regelmäßig neue Produkte entwickelt, die neue Fähigkeiten und Fachkenntnisse erfordern. Es besteht ein wachsender Bedarf an Personen, die neue Infrastrukturen, Plattformen und Prozesse in das Unternehmen integrieren können, sowie an Personen, die neue Analysen und Algorithmen erstellen können, mit denen enorme Informationen von großem geschäftlichem Wert erstellt werden können. Weitere Informationen finden Sie in unserem Blogbeitrag unter
Relevanz der Datenwissenschaft in verschiedenen Branchen:
Data Science & Analytics ist branchenübergreifend anwendbar:
- E-Commerce - Personalisierungs- und Empfehlungs-Engines, die den Umsatz steigern.
- Werbung - Sehr zielgerichtete Anzeigenlieferung in Echtzeit an Verbraucher.
- Medien & Unterhaltung - Kundenspezifische Inhaltsentwicklung, die die Benutzerinteraktion maximiert.
- Sozialen Medien - Erhöhte „Klebrigkeit“ der Website, Benutzerwachstum und die Fähigkeit, schnelllebige Trends auf der Grundlage der Verbraucherstimmung zu verfolgen.
- Finanzdienstleistungen –Optimierte Kreditvergabepraktiken, die Risiko und Betrug minimieren.
- Pharma / Bioinformatik - Verbesserte Wirkstoffentdeckung, wirksamere Behandlung bedrohlicher Krankheiten, gentechnische Verbesserungen.
- Gesundheitspflege - Bessere Bewertung von Gesundheitspatienten hinsichtlich Gesundheitsrisiken sowie Antizipation und frühzeitige Prävention von Krankheiten.
- Kraft / Energie - Smart Grid Intelligence, Nutzungseffizienz, Energieeinsparungen und Reduzierung von Ausfallzeiten.
- Informationssicherheit - Deutlich verbesserte Diebstahlerkennung und Überwachung wertvoller Unternehmensinformationen und Vermögenswerte.
Schlüsselkompetenzen von Data Science-Fachleuten:
Data Science Domain erfordert Fachleute, die:
- Versteht Datenanalyse und Entscheidungswissenschaft
- Sind mit IT vertraut
- Haben Sie starken Geschäftssinn
- Besitzen Sie die Fähigkeit, effektiv mit Entscheidungsträgern zu kommunizieren
Weiterlesen: Kernkompetenzen, die erforderlich sind, um ein Data Scientist zu sein.
wie man Sets in Java benutzt
Gemeinsame Technologien im Zusammenhang mit der datenwissenschaftlichen Praxis:
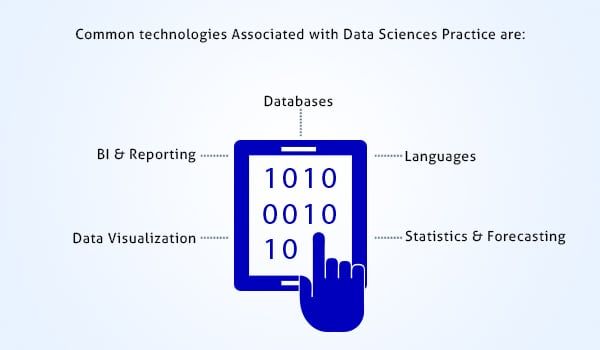
- Datenbanken
Oracle, SQL Server, Teradata
Cassandra, Hadoop, MapReduce, HBase
Aster, Greenplum, Netezza
- Sprachen
Ajax, C ++, CSS, HTML5, Java, JavaScript, Perl, Python, Scala
Bienenstock, Schwein, Lucene, Mahout, Solr
- Statistik & Prognose
Angoss, MATLAB, R, SAS, SPSS
ARCH, GARCH, SVAR, VAR, VEC, GAUSS
- Datenvisualisierung
QlikView, Spotfire, Tableau, yWorks, R.
- BI & Reporting
BusinessObjects, Cognos, MicroStrategy
Was ist Cassandra?
- Apache Cassandra ist ein Open Source-System zur Verwaltung verteilter Datenbanken, das für die Verarbeitung großer Datenmengen auf vielen Commodity-Servern entwickelt wurde.
- Cassandra bietet hohe Verfügbarkeit ohne Single Point of Failure.
- Cassandra bietet robuste Unterstützung für Cluster, die sich über mehrere Rechenzentren erstrecken. Die asynchrone Replikation ohne Master ermöglicht Operationen mit geringer Latenz für alle Clients.
Weitere Informationen finden Sie in unserem Blogbeitrag auf der .
Wie nutzt Data Science Cassandra?
Cassandra ist eine verteilte Datenbank für Dienste mit geringer Latenz und hohem Durchsatz, die Echtzeit-Workloads mit Hunderten von Updates pro Sekunde und Zehntausenden von Lesevorgängen pro Sekunde verarbeiten.
Kassandra Anwendungsfall - PROS:
PROS ist ein Big-Data-Softwareunternehmen mit präskriptiven Analysen in seiner Software, die es seinen Kunden ermöglichen, ihre Daten zu analysieren und Einblicke und Anleitungen zur Optimierung ihres Preis-, Verkaufs- und Ertragsmanagements zu erhalten.
Sie verfügen über einen Echtzeitdienst, der die Verfügbarkeit von Fluggesellschaften berechnet und dabei die Daten zur Ertragskontrolle und die Lagerbestände dynamisch berücksichtigt, die sich viele hundert Mal pro Sekunde ändern können.
Dieser Dienst wird mehrere tausend Mal pro Sekunde abgefragt, was zu Zehntausenden von Datensuchen führt. Ihre Backend-Speicherschicht für diesen Service ist Cassandra.
Für ihre Echtzeitlösung erkannte PROS einen Bedarf an:
- Ein verteilter Cache, der hoch verfügbar ist.
- Leicht skalierbar.
- Mit einer Architektur ohne Meister.
- Mit nahezu Echtzeit-Datenreplikation auch über Rechenzentren hinweg.
- Das kann Lese- und Schreibvorgänge in Echtzeit verarbeiten.
PROS bewertete Cassandra gegen Oracle Berkeley DB, Oracle Coherence, Terracotta, Voldemort und Redis. Apache Cassandra führte ganz leicht die Liste an.
PROS und Cassandra
- PROS verwendet Cassandra als verteilte Datenbank für Dienste mit geringer Latenz und hohem Durchsatz, die Echtzeit-Workloads mit Hunderten von Aktualisierungen pro Sekunde und Zehntausenden von Lesevorgängen pro Sekunde verarbeiten.
- Zum Beispiel verfügen sie über einen Echtzeitdienst, der die Verfügbarkeit von Fluggesellschaften dynamisch berechnet und dabei Daten zur Umsatzkontrolle und Lagerbestände berücksichtigt, die sich viele hundert Mal pro Sekunde ändern können. Dieser Dienst wird mehrere tausend Mal pro Sekunde abgefragt, was zu Zehntausenden von Daten-Lookups führt. Ihre Backend-Speicherschicht für diesen Service ist Cassandra. Einige ihrer SaaS-Angebote verwenden Cassandra als Backend-Store, um eine Kombination aus Echtzeit- und Hadoop-basierten Batch-Workloads zu verwalten.
- Wenn sie über Hadoop und Cassandra sprechen, nehmen sie die Daten aus Cassandra und legen sie in Hadoop ab. Anschließend führen sie Batch- und Analytics-Daten aus, und dann geht das zurück in Cassandra. Dies wird durch die Hadoop-Integration von Cassandra erreicht.
- Die Hadoop-Jobs ziehen Daten aus Cassandra heraus, wenden auftragsspezifische Transformationen oder Analysen an und übertragen Daten zurück in Cassandra. Sie verwenden für diese Integration nicht die Datastax (offizielle Cassandra Maintainer) Enterprise Edition, sondern nur die Open-Source-Hadoop-Installation mit Cassandra.
Datenmodellierung mit Cassandra:
Wenn Sie versuchen, einen Schlüsselwertspeicher durch etwas zu ersetzen, das für die Echtzeitreplikation und Datenverteilung besser geeignet ist, zeigen Untersuchungen zu Dynamo, dem CAP-Theorem und dem eventuellen Konsistenzmodell, dass Cassandra recht gut zu diesem Modell passt. Wenn man mehr über Datenmodellierungsfunktionen erfährt, gehen wir schrittweise zur Zerlegung von Daten über.
Wenn man aus einem relationalen Datenbankhintergrund mit starker ACID-Semantik stammt, muss man sich die Zeit nehmen, um das mögliche Konsistenzmodell zu verstehen.
Verstehe Cassandras Architektur sehr gut und was sie unter der Haube macht. Mit Cassandra 2.0 erhalten Sie einfache Transaktionen und Trigger, die jedoch nicht mit den herkömmlichen Datenbanktransaktionen identisch sind, mit denen Sie möglicherweise vertraut sind. Beispielsweise sind keine Fremdschlüsseleinschränkungen verfügbar - diese müssen von der eigenen Anwendung behandelt werden. Es ist ein Muss, die Anwendungsfälle und Datenzugriffsmuster vor dem Modellieren von Daten mit Cassandra klar zu verstehen und die gesamte verfügbare Dokumentation zu lesen.
Fazit:
Apache Cassandra entwickelt sich schnell weiter und wir lernen und verstehen seine Fähigkeiten - insbesondere auf der Seite der Datenmodellierung. Wir sehen es als verteilte NoSQL-Datenbank der Wahl für unsere Big Data-Dienste und -Lösungen.
Wie konvertiere ich Dezimal in Binär in Python
Edureka bietet eine umfassende für diejenigen, die Datenwissenschaftler werden möchten. Der Kurs umfasst eine Reihe von Hadoop-, R- und maschinellen Lerntechniken, die die gesamte Data Science-Studie umfassen. Edureka bietet auch Das hilft Ihnen, NoSQL-Datenbanken zu beherrschen. Dieser Kurs soll Wissen und Fähigkeiten vermitteln, um ein erfolgreicher Cassandra-Experte zu werden.