
Ich habe dieses TensorFlow-Tutorial für Profis und Enthusiasten entwickelt, die daran interessiert sind, den Deep Learning-Algorithmus mit TensorFlow anzuwenden, um verschiedene Probleme zu lösen. TensorFlow ist eine Open-Source-Deep-Learning-Bibliothek, die auf dem Konzept von Datenflussdiagrammen zum Erstellen von Modellen basiert. Sie können damit große neuronale Netze mit vielen Schichten erstellen.Das Erlernen der Verwendung dieser Bibliothek ist ebenfalls ein wesentlicher Bestandteil der .Im Folgenden werden die Themen aufgeführt, die in diesem TensorFlow-Tutorial-Blog behandelt werden:
- Was ist TensorFlow?
- Grundlagen des TensorFlow-Codes
- TensorFlow UseCase
Was sind Tensoren?
Lassen Sie uns in diesem TensorFlow-Tutorial zunächst verstehen, bevor wir über TensorFlow sprechen Was sind Tensoren? . Tensoren sind nichts anderes als de facto für die Darstellung der Daten beim Deep Learning.
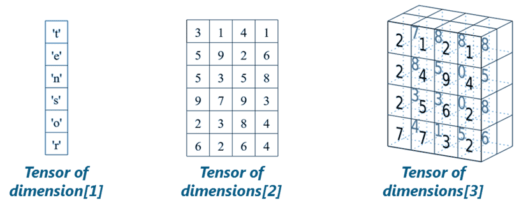 Wie in der Abbildung oben gezeigt, sind Tensoren nur mehrdimensionale Arrays, mit denen Sie Daten mit höheren Dimensionen darstellen können. Im Allgemeinen handelt es sich bei Deep Learning um hochdimensionale Datensätze, bei denen sich Dimensionen auf verschiedene im Datensatz vorhandene Funktionen beziehen. Tatsächlich wurde der Name 'TensorFlow' von den Operationen abgeleitet, die neuronale Netze an Tensoren ausführen. Es ist buchstäblich ein Fluss von Tensoren. Da Sie verstanden haben, was Tensoren sind, lassen Sie uns in diesem TensorFlow-Tutorial fortfahren und verstehen: Was ist TensorFlow?
Wie in der Abbildung oben gezeigt, sind Tensoren nur mehrdimensionale Arrays, mit denen Sie Daten mit höheren Dimensionen darstellen können. Im Allgemeinen handelt es sich bei Deep Learning um hochdimensionale Datensätze, bei denen sich Dimensionen auf verschiedene im Datensatz vorhandene Funktionen beziehen. Tatsächlich wurde der Name 'TensorFlow' von den Operationen abgeleitet, die neuronale Netze an Tensoren ausführen. Es ist buchstäblich ein Fluss von Tensoren. Da Sie verstanden haben, was Tensoren sind, lassen Sie uns in diesem TensorFlow-Tutorial fortfahren und verstehen: Was ist TensorFlow?
Was ist TensorFlow?
TensorFlow ist eine auf Python basierende Bibliothek, die verschiedene Arten von Funktionen für die Implementierung von Deep Learning-Modellen bietet. Wie bereits erwähnt, besteht der Begriff TensorFlow aus zwei Begriffen: Tensor & Flow:
In TensorFlow bezieht sich der Begriff Tensor auf die Darstellung von Daten als mehrdimensionales Array, während sich der Begriff Flow auf die Reihe von Operationen bezieht, die an Tensoren ausgeführt werden, wie im obigen Bild gezeigt.
Jetzt haben wir genug Hintergrundinformationen über TensorFlow behandelt.
Als nächstes werden wir in diesem TensorFlow-Tutorial die Grundlagen des TensorFlow-Codes diskutieren.
TensorFlow Tutorial: Code-Grundlagen
Grundsätzlich umfasst der gesamte Prozess des Schreibens eines TensorFlow-Programms zwei Schritte:
- Erstellen eines Computergraphen
- Ausführen eines Computergraphen
Lassen Sie mich Ihnen die beiden oben genannten Schritte nacheinander erklären:
1. Erstellen eines Computergraphen
So, Was ist ein Rechengraph? Nun, ein Berechnungsgraph ist eine Reihe von TensorFlow-Operationen, die als Knoten im Graph angeordnet sind. Jeder Knoten nimmt 0 oder mehr Tensoren als Eingabe und erzeugt einen Tensor als Ausgabe. Lassen Sie mich ein Beispiel für einen einfachen Rechengraphen geben, der aus drei Knoten besteht - zu , b & c Wie nachfolgend dargestellt:
Erklärung des obigen Berechnungsgraphen:
Konstante Knotenwerden verwendet, um konstante Werte zu speichern, da keine Eingabe erforderlich ist, die gespeicherten Werte jedoch als Ausgabe erzeugt werden. Im obigen Beispiel sind a und b konstante Knoten mit den Werten 5 bzw. 6.
- Der Knoten c repräsentiert die Operation des Multiplizierens des konstanten Knotens a mit b. Daher führt das Ausführen des Knotens c zur Multiplikation des konstanten Knotens a & b.
Grundsätzlich kann man sich einen Rechengraphen als alternative Methode zur Konzeption mathematischer Berechnungen vorstellen, die in einem TensorFlow-Programm stattfinden. Die Operationen, die verschiedenen Knoten eines Computergraphen zugewiesen sind, können parallel ausgeführt werden, wodurch eine bessere Rechenleistung erzielt wird.
Hier beschreiben wir nur die Berechnung, sie berechnet nichts, sie enthält keine Werte, sie definiert nur die in Ihrem Code angegebenen Operationen.
Was ist Vektor in Java
2. Ausführen eines Computergraphen
Nehmen wir das vorherige Beispiel eines Rechengraphen und verstehen, wie es ausgeführt wird. Es folgt der Code aus dem vorherigen Beispiel:
Beispiel 1:
Tensorflow als tf importieren # Ein Diagramm erstellen a = tf.constant (5.0) b = tf.constant (6.0) c = a * b
Um nun die Ausgabe von Knoten c zu erhalten, müssen wir den Berechnungsgraphen innerhalb von a ausführen Session . Die Sitzung platziert die Diagrammoperationen auf Geräten wie CPUs oder GPUs und stellt Methoden zu deren Ausführung bereit.
Eine Sitzung kapselt die Steuerung und den Status der TensorFlow-Laufzeit, d. H. Sie speichert die Informationen über die Reihenfolge, in der alle Operationen ausgeführt werden, und leitet das Ergebnis der bereits berechneten Operation an die nächste Operation in der Pipeline weiter. Lassen Sie mich Ihnen zeigen, wie Sie das obige Berechnungsdiagramm innerhalb einer Sitzung ausführen (Erläuterung jeder Codezeile wurde als Kommentar hinzugefügt):
# Erstellen Sie das Sitzungsobjekt sess = tf.Session () # Führen Sie das Diagramm innerhalb einer Sitzung aus und speichern Sie die Ausgabe in einer Variablen output_c = sess.run (c) #Drucken Sie die Ausgabe von Knoten c print (output_c) # Schließen Sie die Sitzung an einige Ressourcen freigeben sess.close ()
Ausgabe: 30Hier ging es also nur um die Sitzung und das Ausführen eines Rechengraphen. Lassen Sie uns nun über Variablen und Platzhalter sprechen, die wir beim Erstellen eines Deep-Learning-Modells mit TensorFlow ausführlich verwenden werden.
Konstanten, Platzhalter und Variablen
In TensorFlow werden Konstanten, Platzhalter und Variablen verwendet, um verschiedene Parameter eines Deep-Learning-Modells darzustellen. Da ich Konstanten bereits früher besprochen habe, werde ich mit Platzhaltern beginnen.
Platzhalter:
Mit einer TensorFlow-Konstante können Sie einen Wert speichern. Was ist, wenn Ihre Knoten während des Laufs Eingaben vornehmen sollen? Für diese Art von Funktionalität werden Platzhalter verwendet, mit denen Ihr Diagramm externe Eingaben als Parameter verwenden kann. Grundsätzlich ist ein Platzhalter ein Versprechen, später oder zur Laufzeit einen Wert bereitzustellen. Lassen Sie mich ein Beispiel geben, um die Dinge einfacher zu machen:
Tensorflow als tf importieren # Platzhalter erstellen a = tf. Platzhalter (tf.float32) b = tf. Platzhalter (tf.float32) # Zuweisen der Multiplikationsoperation w.r.t. a & ampamp b an Knoten mul mul = a * b # Sitzungsobjekt erstellen sess = tf.Session () # Ausführen von mul durch Übergeben der Werte [1, 3] [2, 4] für a bzw. b output = sess.run ( mul, {a: [1,3], b: [2, 4]}) print ('Multiplizieren von ab:', Ausgabe) Ausgabe: [2. 12.]Punkte, an die man sich erinnern sollte Platzhalter:
- Platzhalter werden nicht initialisiert und enthalten keine Daten.
- Man muss dem Platzhalter Eingaben oder Feeds bereitstellen, die zur Laufzeit berücksichtigt werden.
- Das Ausführen eines Platzhalters ohne Eingabe erzeugt einen Fehler.
Lassen Sie uns jetzt weitermachen und verstehen - Was sind Variablen?
Variablen
Beim Deep Learning werden Platzhalter verwendet, um beliebige Eingaben in Ihr Modell oder Diagramm zu übernehmen. Abgesehen von der Eingabe müssen Sie das Diagramm auch so ändern, dass neue Ausgaben w.r.t. gleiche Eingänge. Dafür verwenden Sie Variablen. Kurz gesagt, mit einer Variablen können Sie dem Diagramm solche Parameter oder Knoten hinzufügen, die trainierbar sind, d. H. Der Wert kann über einen bestimmten Zeitraum geändert werden. Variablen werden definiert, indem ihr Anfangswert und Typ wie unten gezeigt angegeben werden:
var = tf.Variable ([0.4], dtype = tf.float32)
Hinweis:
- Falls Sie den Datentyp nicht explizit angegeben haben, leitet TensorFlow den Typ der Konstanten / Variablen aus dem initialisierten Wert ab.
- TensorFlow hat viele seiner eigenen Datentypen wie tf.float32 , tf.int32 usw. Sie können sich auf alle beziehen Hier .
Konstanten werden beim Aufruf initialisiert tf.konstant und ihr Wert kann sich nie ändern. Im Gegenteil, Variablen werden beim Aufruf nicht initialisiert tf.Variable . Um alle Variablen in einem TensorFlow-Programm zu initialisieren, müssen Sie Muss Rufen Sie explizit eine spezielle Operation auf, wie unten gezeigt:
init = tf.global_variables_initializer () sess.run (init)
Denken Sie immer daran, dass eine Variable initialisiert werden muss, bevor ein Diagramm zum ersten Mal verwendet wird.
Hinweis: TensorFlow-Variablen sind speicherinterne Puffer, die Tensoren enthalten. Im Gegensatz zu normalen Tensoren, die nur beim Ausführen eines Diagramms instanziiert und anschließend sofort gelöscht werden, überleben Variablen mehrere Ausführungen eines Diagramms.
Nachdem wir uns nun mit den Grundlagen von TensorFlow vertraut gemacht haben, wollen wir verstehen, wie ein lineares Regressionsmodell mit TensorFlow implementiert wird.
Lineares Regressionsmodell mit TensorFlow
Das lineare Regressionsmodell wird verwendet, um den unbekannten Wert einer Variablen (abhängige Variable) aus dem bekannten Wert einer anderen Variablen (unabhängige Variable) unter Verwendung der linearen Regressionsgleichung wie folgt vorherzusagen:
Zum Erstellen eines linearen Modells benötigen Sie daher:
- Abhängige oder Ausgabevariable (Y)
- Steigungsvariable (w)
- Y - Achsenabschnitt oder Vorspannung (b)
- Unabhängige oder Eingangsvariable (X)
Beginnen wir also mit der Erstellung eines linearen Modells mit TensorFlow:
ist eine Beziehung in Java
Kopieren Sie den Code, indem Sie auf die unten angegebene Schaltfläche klicken:
# Erstellen einer Variablen für die Parametersteigung (W) mit einem Anfangswert von 0,4 W = tf.Variable ([. 4], tf.float32) #Erstellen einer Variablen für eine Parametervorspannung (b) mit einem Anfangswert von -0,4 b = tf.Variable ( [-0.4], tf.float32) # Platzhalter für die Bereitstellung einer Eingabe oder einer unabhängigen Variablen erstellen, bezeichnet mit xx = tf.placeholder (tf.float32) # Gleichung der linearen Regression linear_model = W * x + b # Initialisierung aller Variablen sess = tf.Session () init = tf.global_variables_initializer () sess.run (init) # Regressionsmodell ausführen, um die Ausgabe wrt zu berechnen zu angegebenen x-Werten drucken (sess.run (linear_model {x: [1, 2, 3, 4]}))Ausgabe:
[0. 0.40000001 0.80000007 1.20000005]
Der oben angegebene Code stellt nur die Grundidee hinter der Implementierung des Regressionsmodells dar, d. H. Wie Sie der Gleichung der Regressionslinie folgen, um eine Ausgabe mit RT zu erhalten. eine Reihe von Eingabewerten. In diesem Modell müssen jedoch noch zwei weitere Dinge hinzugefügt werden, um es zu einem vollständigen Regressionsmodell zu machen:
- Zunächst müssen wir einen Mechanismus bereitstellen, mit dem sich unser Modell basierend auf bestimmten Eingaben und entsprechenden Ausgaben automatisch trainieren kann.
- Das zweite, was wir brauchen, ist die Validierung unseres trainierten Modells durch Vergleichen seiner Ausgabe mit der gewünschten oder Zielausgabe basierend auf einem gegebenen Satz von x-Werten.
Lassen Sie uns nun verstehen, wie ich die oben genannten Funktionen in meinen Code für das Regressionsmodell integrieren kann.
Verlustfunktion - Modellvalidierung
Eine Verlustfunktion misst, wie weit die aktuelle Ausgabe des Modells von der gewünschten oder Zielausgabe entfernt ist. Ich verwende eine am häufigsten verwendete Verlustfunktion für mein lineares Regressionsmodell, die als Summe der quadratischen Fehler oder SSE bezeichnet wird. SSE berechnet w.r.t. Modellausgabe (dargestellt durch linear_model) und gewünschte oder Zielausgabe (y) als:
y = tf.placeholder (tf.float32) error = linear_model - y squared_errors = tf.square (error) loss = tf.reduce_sum (squared_errors) print (sess.run (loss, {x: [1,2,3,4) ], y: [2, 4, 6, 8]}) Ausgabe: 90,24Wie Sie sehen, erzielen wir einen hohen Verlustwert. Daher müssen wir unsere Gewichte (W) und Vorspannung (b) anpassen, um den Fehler zu reduzieren, den wir erhalten.
tf.train API - Training des Modells
TensorFlow bietet Optimierer das ändert langsam jede Variable, um die Verlustfunktion oder den Fehler zu minimieren. Der einfachste Optimierer ist Gradientenabstieg . Es modifiziert jede Variable entsprechend der Größe der Verlustableitung in Bezug auf diese Variable.
#Erstellen einer Instanz des Gradientenabstiegsoptimierers optimizer = tf.train.GradientDescentOptimizer (0.01) train = optimizer.minimize (Verlust) für i im Bereich (1000): sess.run (train, {x: [1, 2, 3, 4], y: [2, 4, 6, 8]}) print (sess.run ([W, b]))Ausgabe: [Array ([1.99999964], dtype = float32), Array ([9.86305167e-07], dtype = float32)]
Auf diese Weise erstellen Sie mit TensorFlow ein lineares Modell und trainieren es, um die gewünschte Ausgabe zu erhalten.
Nachdem Sie nun über Deep Learning Bescheid wissen, lesen Sie die von Edureka, einem vertrauenswürdigen Online-Lernunternehmen mit einem Netzwerk von mehr als 250.000 zufriedenen Lernenden auf der ganzen Welt. Der Edureka Deep Learning mit TensorFlow-Zertifizierungstraining hilft den Lernenden, Experten für das Training und die Optimierung grundlegender und faltungsbedingter neuronaler Netze zu werden, indem sie Echtzeitprojekte und -aufgaben zusammen mit Konzepten wie der SoftMax-Funktion, Auto-Encoder-Neuronalen Netzen und der eingeschränkten Boltzmann-Maschine (RBM) verwenden.
Hast du eine Frage an uns? Bitte erwähnen Sie es in den Kommentaren und wir werden uns bei Ihnen melden.