
Mit dem Fortschritt im maschinellen Lernen, hat eine Hauptstraße genommen. Deep Learning gilt als die fortschrittlichste Technologie zur Lösung komplexer Probleme, bei denen große Datenmengen verwendet werden. Dieser Blog über neuronale Netze führt Sie in die Grundkonzepte neuronaler Netze ein und erklärt, wie sie komplexe datengesteuerte Probleme lösen können.
Um detaillierte Kenntnisse über künstliche Intelligenz und tiefes Lernen zu erhalten, können Sie sich live anmelden von Edureka mit 24/7 Support und lebenslangem Zugriff.
wie man einen jframe erstellt
Hier ist eine Liste von Themen, die hier behandelt werden Blog:
- Was ist ein neuronales Netzwerk?
- Was ist Deep Learning?
- Unterschied zwischen AI, ML und DL
- Notwendigkeit für tiefes Lernen
- Deep Learning-Anwendungsfall
- Wie funktionieren neuronale Netze?
- Neuronales Netz mit Beispiel erklärt
Einfache Definition eines neuronalen Netzes
Modelliert in Übereinstimmung mit dem menschlichen Gehirn, a Das neuronale Netzwerk wurde entwickelt, um die Funktionalität eines menschlichen Gehirns nachzuahmen . Das menschliche Gehirn ist ein neuronales Netzwerk, das aus mehreren Neuronen besteht. Ebenso besteht ein künstliches neuronales Netzwerk (ANN) aus mehreren Perzeptronen (wird später erläutert).
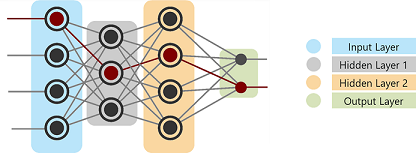
Ein neuronales Netzwerk besteht aus drei wichtigen Schichten:
- Eingabeebene: Wie der Name schon sagt, akzeptiert diese Ebene alle vom Programmierer bereitgestellten Eingaben.
- Versteckte Ebene: Zwischen der Eingabe- und der Ausgabeebene befindet sich eine Reihe von Ebenen, die als versteckte Ebenen bezeichnet werden. In dieser Schicht werden Berechnungen durchgeführt, die zur Ausgabe führen.
- Ausgabeschicht: Die Eingaben durchlaufen eine Reihe von Transformationen über die verborgene Schicht, was schließlich zu der Ausgabe führt, die über diese geliefert wird Schicht.
Bevor wir uns eingehend mit der Funktionsweise eines neuronalen Netzwerks befassen, sollten wir verstehen, was Deep Learning ist.
Was ist tiefes Lernen?
Deep Learning ist ein fortgeschrittenes Gebiet des maschinellen Lernens, das die Konzepte neuronaler Netze verwendet, um hoch rechnerische Anwendungsfälle zu lösen, bei denen mehrdimensionale Daten analysiert werden. Es automatisiert den Prozess der Merkmalsextraktion und stellt sicher, dass nur minimale menschliche Eingriffe erforderlich sind.
Was genau ist Deep Learning?
Deep Learning ist ein fortgeschrittener Teilbereich des maschinellen Lernens, der Algorithmen verwendet, die von der Struktur und Funktion des Gehirns inspiriert sind und als künstliche neuronale Netze bezeichnet werden.
Unterschied zwischen AI, ML und DL (Künstliche Intelligenz vs. Maschinelles Lernen vs. Deep Learning)
Die Leute neigen oft dazu, das zu denken , , und Tiefes Lernen sind die gleichen, da sie gemeinsame Anwendungen haben. Zum Beispiel ist Siri eine Anwendung von KI, maschinellem Lernen und tiefem Lernen.
Wie hängen diese Technologien zusammen?
- Künstliche Intelligenz ist die Wissenschaft, Maschinen dazu zu bringen, das Verhalten von Menschen nachzuahmen.
- Maschinelles Lernen ist eine Teilmenge der künstlichen Intelligenz (KI), die sich darauf konzentriert, Maschinen dazu zu bringen, Entscheidungen zu treffen, indem sie ihnen Daten zuführen.
- Tiefes Lernen ist eine Teilmenge des maschinellen Lernens, die das Konzept neuronaler Netze verwendet, um komplexe Probleme zu lösen.
Zusammenfassend sind KI, Maschinelles Lernen und Deep Learning miteinander verbundene Felder. Maschinelles Lernen und tiefes Lernen unterstützen die künstliche Intelligenz, indem sie eine Reihe von Algorithmen und neuronalen Netzen zur Lösung bereitstellen datengetriebene Probleme.
Nachdem Sie mit den Grundlagen vertraut sind, wollen wir verstehen, was zu Deep Learning geführt hat.
Bedarf an tiefem Lernen: Einschränkungen traditioneller Algorithmen und Techniken des maschinellen Lernens
Maschinelles Lernen war ein großer Durchbruch in der technischen Welt. Es führte zur Automatisierung monotoner und zeitaufwändiger Aufgaben, half bei der Lösung komplexer Probleme und traf intelligentere Entscheidungen. Es gab jedoch einige Nachteile beim maschinellen Lernen, die zur Entstehung von Deep Learning führten.
Hier sind einige Einschränkungen des maschinellen Lernens:
- Hochdimensionale Daten können nicht verarbeitet werden: Maschinelles Lernen kann nur kleine Dimensionen von Daten verarbeiten, die einen kleinen Satz von Variablen enthalten. Wenn Sie Daten analysieren möchten, die Hunderte von Variablen enthalten, kann maschinelles Lernen nicht verwendet werden.
- Feature Engineering ist manuell: Stellen Sie sich einen Anwendungsfall vor, in dem Sie 100 Prädiktorvariablen haben und nur die signifikanten eingrenzen müssen. Dazu müssen Sie die Beziehung zwischen den einzelnen Variablen manuell untersuchen und herausfinden, welche für die Vorhersage der Ausgabe wichtig sind. Diese Aufgabe ist für einen Entwickler äußerst mühsam und zeitaufwändig.
- Nicht ideal für die Objekterkennung und Bildverarbeitung: Da für die Objekterkennung hochdimensionale Daten erforderlich sind, kann das maschinelle Lernen nicht zur Verarbeitung von Bilddatensätzen verwendet werden. Es ist nur ideal für Datensätze mit einer begrenzten Anzahl von Merkmalen.
Bevor wir in die Tiefen von kommen Betrachten wir neuronale Netze als einen realen Anwendungsfall, in dem Deep Learning implementiert ist.
Deep Learning-Anwendungsfall / Anwendungen
Wussten Sie, dass PayPal Zahlungen von mehr als 170 Millionen Kunden aus vier Milliarden Transaktionen in Höhe von über 235 Milliarden US-Dollar verarbeitet? Diese enorme Datenmenge wird unter anderem verwendet, um mögliche betrügerische Aktivitäten zu identifizieren.
Mithilfe von Deep Learning-Algorithmen hat PayPal Daten aus der Kaufhistorie seiner Kunden ermittelt und die in den Datenbanken gespeicherten Muster für wahrscheinlichen Betrug überprüft, um vorherzusagen, ob eine bestimmte Transaktion betrügerisch ist oder nicht.
Das Unternehmen setzt seit rund 10 Jahren auf Deep Learning & Machine Learning-Technologie. Zunächst verwendete das Betrugsüberwachungsteam einfache, lineare Modelle. Im Laufe der Jahre wechselte das Unternehmen jedoch zu einer fortschrittlicheren Technologie für maschinelles Lernen namens Deep Learning.
Betrugsrisikomanager und Datenwissenschaftler bei PayPal, Ke Wang, zitiert:
„Was wir an modernerem, fortgeschrittenem maschinellem Lernen genießen, ist die Fähigkeit, viel mehr Daten zu verbrauchen, Schichten und Schichten der Abstraktion zu handhaben und Dinge zu„ sehen “, die eine einfachere Technologie selbst Menschen nicht sehen könnte nicht sehen können. '
Ein einfaches lineares Modell kann etwa 20 Variablen verbrauchen. Mit der Deep Learning-Technologie können jedoch Tausende von Datenpunkten ausgeführt werden. Daher durch Implementierung Mit der Deep Learning-Technologie kann PayPal endlich Millionen von Transaktionen analysieren, um betrügerische Aktivitäten zu identifizieren Aktivität.
Gehen wir nun in die Tiefen eines neuronalen Netzwerks und verstehen, wie sie funktionieren.
c ++ Algorithmus sortieren
Wie funktioniert ein neuronales Netzwerk?
Um neuronale Netze zu verstehen, müssen wir sie zerlegen und die grundlegendste Einheit eines neuronalen Netzes verstehen, d. H. Ein Perceptron.
Was ist ein Perceptron?
Ein Perceptron ist ein einschichtiges neuronales Netzwerk, das zur Klassifizierung linearer Daten verwendet wird. Es hat 4 wichtige Komponenten:
- Eingänge
- Gewichte und Vorspannung
- Summationsfunktion
- Aktivierungs- oder Transformationsfunktion
Die grundlegende Logik hinter einem Perceptron lautet wie folgt:
Die von der Eingabeebene empfangenen Eingaben (x) werden mit ihren zugewiesenen Gewichten w multipliziert. Die multiplizierten Werte werden dann addiert, um die gewichtete Summe zu bilden. Die gewichtete Summe der Eingaben und ihre jeweiligen Gewichte werden dann auf eine relevante Aktivierungsfunktion angewendet. Die Aktivierungsfunktion ordnet den Eingang dem jeweiligen Ausgang zu.
Gewichte und Verzerrungen beim tiefen Lernen
Warum müssen wir jedem Eingang Gewichte zuweisen?
Sobald eine Eingangsvariable dem Netzwerk zugeführt wird, wird ein zufällig ausgewählter Wert als Gewicht dieser Eingabe zugewiesen. Das Gewicht jedes Eingabedatenpunkts gibt an, wie wichtig diese Eingabe für die Vorhersage des Ergebnisses ist.
Mit dem Bias-Parameter hingegen können Sie die Aktivierungsfunktionskurve so einstellen, dass eine präzise Ausgabe erzielt wird.
Summationsfunktion
Sobald den Eingaben ein gewisses Gewicht zugewiesen wurde, wird das Produkt der jeweiligen Eingabe und des Gewichts genommen. Durch Hinzufügen all dieser Produkte erhalten wir die gewichtete Summe. Dies erfolgt durch die Summationsfunktion.
Aktivierungsfunktion
Das Hauptziel der Aktivierungsfunktionen besteht darin, die gewichtete Summe der Ausgabe zuzuordnen. Aktivierungsfunktionen wie tanh, ReLU, Sigmoid usw. sind Beispiele für Transformationsfunktionen.
Um mehr über die Funktionen von Perceptrons zu erfahren, können Sie dies durchgehen Blog.
Bevor wir Zum Abschluss dieses Blogs nehmen wir ein einfaches Beispiel, um zu verstehen, wie ein neuronales Netzwerk funktioniert.
Mit einem Beispiel erläuterte neuronale Netze
Stellen Sie sich ein Szenario vor, in dem Sie ein künstliches neuronales Netzwerk (ANN) erstellen möchten, das Bilder in zwei Klassen klassifiziert:
- Klasse A: Enthält Bilder von nicht erkrankten Blättern
- Klasse B: Enthält Bilder von kranken Blättern
Wie schafft man ein neuronales Netzwerk, das die Blätter in kranke und nicht kranke Pflanzen unterteilt?
Der Prozess beginnt immer mit der Verarbeitung und Transformation der Eingabe, so dass sie leicht verarbeitet werden kann. In unserem Fall wird jedes Blattbild abhängig von der Größe des Bildes in Pixel zerlegt.
Wenn das Bild beispielsweise aus 30 mal 30 Pixeln besteht, beträgt die Gesamtzahl der Pixel 900. Diese Pixel werden als Matrizen dargestellt, die dann in die Eingangsschicht des Neuronalen Netzwerks eingespeist werden.
Genau wie unser Gehirn Neuronen hat, die beim Aufbau und der Verbindung von Gedanken helfen, hat ein ANN Perzeptrone, die Eingaben akzeptieren und verarbeiten, indem sie sie von der Eingabeebene an die verborgene und schließlich an die Ausgabeschicht weiterleiten.
Wenn die Eingabe von der Eingabeebene an die verborgene Ebene übergeben wird, wird jeder Eingabe eine anfängliche zufällige Gewichtung zugewiesen. Die Eingaben werden dann mit ihren entsprechenden Gewichten multipliziert und ihre Summe wird als Eingabe an die nächste verborgene Schicht gesendet.
Hier wird jedem Perzeptron ein numerischer Wert namens Bias zugewiesen, der der Gewichtung jeder Eingabe zugeordnet ist. Ferner wird jedes Perzeptron durch eine Aktivierung oder eine Transformationsfunktion geleitet, die bestimmt, ob ein bestimmtes Perzeptron aktiviert wird oder nicht.
Ein aktiviertes Perzeptron wird verwendet, um Daten an die nächste Schicht zu übertragen. Auf diese Weise werden die Daten durch das neuronale Netzwerk weitergegeben (Forward Propagation), bis die Perzeptrone die Ausgangsschicht erreichen.
Auf der Ausgabeschicht wird eine Wahrscheinlichkeit abgeleitet, die entscheidet, ob die Daten zur Klasse A oder zur Klasse B gehören.
Klingt einfach, oder? Nun, das Konzept hinter Neuronalen Netzen basiert ausschließlich auf der Funktionsweise des menschlichen Gehirns. Sie benötigen fundierte Kenntnisse verschiedener mathematischer Konzepte und Algorithmen. Hier ist eine Liste von Blogs, mit denen Sie beginnen können:
- Was ist Deep Learning? Erste Schritte mit Deep Learning
- Deep Learning mit Python: Leitfaden für Anfänger zum Deep Learning
Wenn Sie diesen Blog relevant fanden, lesen Sie die von Edureka, einem vertrauenswürdigen Online-Lernunternehmen mit einem Netzwerk von mehr als 250.000 zufriedenen Lernenden auf der ganzen Welt. Der Edureka Deep Learning mit TensorFlow-Zertifizierungstraining hilft den Lernenden, Experten für das Training und die Optimierung grundlegender und faltungsbedingter neuronaler Netze zu werden. Dabei werden Echtzeitprojekte und -aufgaben sowie Konzepte wie die SoftMax-Funktion, Auto-Encoder-Neuronale Netze und die eingeschränkte Boltzmann-Maschine (RBM) verwendet.