
ist eines der am häufigsten verwendeten Frameworks für den Umgang mit und die Arbeit mit Big Data AND Python ist eine der am häufigsten verwendeten Programmiersprachen für Datenanalyse, maschinelles Lernen und vieles mehr. Warum also nicht zusammen verwenden? Das ist wo Funken mit Python auch bekannt als PySpark kommt indasBild.
Bei einem Durchschnittsgehalt von 110.000 USD pro Jahr für einen Apache Spark-Entwickler besteht kein Zweifel daran, dass Spark in der Branche häufig eingesetzt wird. Durches istPython wird von Rich verwendetdasMehrheit der Data Scientists und Analytics-Experten heute. Die Integration von Python in Spark war ein großes Geschenk für die Community. Spark wurde in der Scala-Sprache entwickelt, die Java sehr ähnlich ist. Es kompiliert den Programmcode in Bytecode für die JVM für die Funken-Big-Data-Verarbeitung. Um Spark mit Python zu unterstützen, hat die Apache Spark-Community PySpark veröffentlicht.Seitdem ist aufgrund der Vielzahl von Vorteilen, die sich aus der Kombination des Besten aus beiden Welten ergeben, als eine der gefragtesten Fähigkeiten in der gesamten Branche bekannt.In diesem Spark with Python-Blog werde ich die folgenden Themen behandeln.
Einführung in Apache Spark
Apache Spark ist ein Open-Source-Cluster-Computing-Framework für Echtzeitverarbeitung entwickelt von der Apache Software Foundation. Spark bietet eine Schnittstelle zum impliziten Programmieren ganzer Cluster Datenparallelität und Fehlertoleranz.
Im Folgenden sind einige der Funktionen von Apache Spark aufgeführt, die einen Vorteil gegenüber anderen Frameworks bieten:
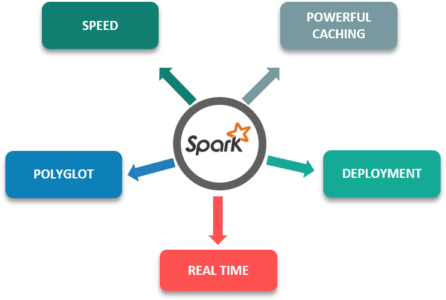
- Geschwindigkeit: Es ist 100-mal schneller als herkömmliche Datenverarbeitungs-Frameworks in großem Maßstab.
- Leistungsstarkes Caching: Die einfache Programmierschicht bietet leistungsstarke Caching- und Festplattenpersistenzfunktionen.
- Einsatz: Kann über Mesos, Hadoop über Yarn oder den eigenen Cluster-Manager von Spark bereitgestellt werden.
- Echtzeit: EchtzeitBerechnung und geringe Latenz aufgrund von In-Memory-Berechnungen.
- Polyglot: Es ist eines der wichtigstenEigenschaftendieses Frameworks, wie es in Scala, Java, Python und R programmiert werden kann.
Warum sich für Python entscheiden?
Obwohl Spark in Scala entworfen wurdeDas macht es fast zehnmal schneller als Python, aber Scala ist nur dann schneller, wenn das Die Anzahl der verwendeten Kerne ist geringer . Da die meisten Analysen und Prozesse heutzutage eine große Anzahl von Kernen erfordern, ist der Leistungsvorteil von Scala nicht so groß.
Für Programmierer ist Python vergleichsweise einfacher lernen wegen seiner Syntax und Standardbibliotheken. Darüber hinaus ist es ein dynamisch getippte Sprache, Dies bedeutet, dass RDDs Objekte mehrerer Typen enthalten können.
Obwohl Scala hat SparkMLlib hat es nicht genügend Bibliotheken und Tools für maschinelles Lernen und NLP Zwecke. Darüber hinaus fehlt Scala die Datenvisualisierung.
PySpark Training | Apache Spark mit Python | Edureka
Abonniere unseren Youtube-Kanal, um neue Updates zu erhalten ..!
Einrichten von Spark mit Python (PySpark)
Ich hoffe ihr wisst wie .Sobald Sie es getan haben entpackt die Funkenfeile, Eingerichtet und fügte den Pfad zu hinzu .bashrc Datei müssen Sie eingebenQuelle .bashrc
export SPARK_HOME = /usr/lib/hadoop/spark-2.1.0-bin-hadoop2.7 export PATH = $ PATH: /usr/lib/hadoop/spark-2.1.0-bin-hadoop2.7/binUm die pyspark-Shell zu öffnen, müssen Sie den Befehl eingeben./bin/pyspark
Funke in der Industrie
Apache Spark wegen seiner erstaunlichen Funktionen wie In-Memory-Verarbeitung , mehrsprachig und schnelle Abwicklung werden von vielen Unternehmen auf der ganzen Welt für verschiedene Zwecke in verschiedenen Branchen eingesetzt:
Yahoo verwendet Apache Spark für seine maschinellen Lernfunktionen, um seine Nachrichten, Webseiten und auch für Zielwerbung zu personalisieren. Sie verwenden Spark mit Python, um herauszufinden, welche Art von Nachrichten - Benutzer sind daran interessiert, die Nachrichten zu lesen und zu kategorisieren, um herauszufinden, welche Art von Benutzern daran interessiert wären, jede Kategorie von Nachrichten zu lesen.
TripAdvisor nutzt Apache Spark, um Millionen von Reisenden zu beraten, indem Hunderte von Websites verglichen werden, um die besten Hotelpreise für ihre Kunden zu finden. Die Zeit, die zum Lesen und Verarbeiten der Bewertungen der Hotels in einem lesbaren Format benötigt wird, wird mithilfe von Apache Spark ermittelt.
Eine der weltweit größten E-Commerce-Plattformen Alibaba führt einige der größten Apache Spark-Jobs der Welt aus, um Hunderte von Petabyte Daten auf seiner E-Commerce-Plattform zu analysieren.
PySpark SparkContext und Datenfluss
Wenn Sie über Spark mit Python sprechen, wird die Arbeit mit RDDs durch die Bibliothek Py4j ermöglicht. PySpark Shell verknüpft die Python-API mit dem Spark-Core und initialisiert den Spark-Kontext. Spark-Kontext ist das Herz jeder Funkenanwendung.
- Der Spark-Kontext richtet interne Dienste ein und stellt eine Verbindung zu einer Spark-Ausführungsumgebung her.
- Das sparkcontext-Objekt im Treiberprogramm koordiniert den gesamten verteilten Prozess und ermöglicht die Ressourcenzuweisung.
- Cluster-Manager stellen Executoren, die JVM-Prozesse sind, Logik zur Verfügung.
- Das SparkContext-Objekt sendet die Anwendung an die Ausführenden.
- SparkContext führt Aufgaben in jedem Executor aus.
Festlegen des Klassenpfads für Java
PySpark KDD Anwendungsfall
Schauen wir uns nun einen Anwendungsfall von an KDD'99 Cup (Internationaler Wettbewerb für Knowledge Discovery- und Data Mining-Tools).Hier nehmen wir einen Bruchteil des Datensatzes, da der ursprüngliche Datensatz zu groß ist
import urllib f = urllib.urlretrieve ('http://kdd.ics.uci.edu/databases/kddcup99/kddcup.data_10_percent.gz', 'kddcup.data_10_percent.gz') RDD ERSTELLEN:
Jetzt können wir diese Datei verwenden, um Erstellen Sie unsere RDD .
data_file = './kddcup.data_10_percent.gz' raw_data = sc.textFile (data_file)
FILTERUNG:
Angenommen, wir möchten zählen, wie viele normal sind. Interaktionen, die wir in unserem Datensatz haben. Wir können Filter unsere raw_data RDD wie folgt.
normal_raw_data = raw_data.filter (Lambda x: 'normal' in x)
ANZAHL:
Jetzt können wir Anzahl Wie viele Elemente haben wir in der neuen RDD.
ab Zeit Importzeit t0 = Zeit () normal_count = normal_raw_data.count () tt = Zeit () - t0 print 'Es gibt {}' normale 'Interaktionen'.format (normal_count) print' Zählung abgeschlossen in {} Sekunden'.format (rund (tt, 3)) Ausgabe:
Es gibt 97278 'normale' Interaktionen. Die Zählung wurde in 5,951 Sekunden abgeschlossen
KARTIERUNG:
In diesemFallWir möchten unsere Datendatei als CSV-formatierte Datei lesen. Wir können dies tun, indem wir wie folgt eine Lambda-Funktion auf jedes Element in der RDD anwenden. Hier werden wir die verwenden map () und take () Transformation.
aus pprint import pprint csv_data = raw_data.map (Lambda x: x.split (',')) t0 = time () head_rows = csv_data.take (5) tt = time () - t0 print 'Analyse in {} Sekunden abgeschlossen '.format (round (tt, 3)) pprint (head_rows [0]) Ausgabe:
Die Analyse wurde in 1,715 Sekunden abgeschlossen [u'0 ', u'tcp', u'http ', u'SF', u'181 ', u'5450', u'0 ', u'0' ,. . u'normal. ']
SPLITTING:
Jetzt möchten wir jedes Element in der RDD als Schlüssel-Wert-Paar haben, wobei der Schlüssel das Tag ist (z. normal ) und der Wert ist die gesamte Liste der Elemente, die die Zeile in der CSV-formatierten Datei darstellen. Wir könnten wie folgt vorgehen. Hier verwenden wir die line.split () und map ().
def parse_interaction (line): elems = line.split (',') tag = elems [41] return (tag, elems) key_csv_data = raw_data.map (parse_interaction) head_rows = key_csv_data.take (5) pprint (head_rows [0] )Ausgabe: (u'normal. ', [u'0', u'tcp ', u'http', u'SF ', u'181', u'5450 ', u'0', u'0 ', u' 0,00 ', u'1,00', .... U'normal. '])
DIE SAMMLUNGSAKTION:
Hier werden wir die Aktion collect () verwenden. Es werden alle Elemente von RDD in den Speicher gebracht. Aus diesem Grund muss es bei der Arbeit mit großen RDDs mit Vorsicht verwendet werden.
t0 = time () all_raw_data = raw_data.collect () tt = time () - t0 'Im {} Sekunden'-Format gesammelte Daten drucken (rund (tt, 3)) Ausgabe:
Datenerfassung in 17.927 Sekunden
Das dauerte natürlich länger als jede andere Aktion, die wir zuvor durchgeführt haben. Jeder Spark-Worker-Knoten, der ein Fragment der RDD enthält, muss koordiniert werden, um seinen Teil abzurufen und dann alles zusammen zu reduzieren.
Als letztes Beispiel, das alle vorherigen kombiniert, möchten wir alle sammelnnormalInteraktionen als Schlüssel-Wert-Paare.
# Daten aus Datei abrufen data_file = './kddcup.data_10_percent.gz' raw_data = sc.textFile (data_file) # in Schlüssel-Wert-Paare analysieren key_csv_data = raw_data.map (parse_interaction) # normale Schlüsselinteraktionen filtern normal_key_interactions = key_csv_data.filter ( lambda x: x [0] == 'normal.') # sammle alle t0 = time () all_normal = normal_key_interactions.collect () tt = time () - t0 normal_count = len (all_normal) print 'In {} Sekunden gesammelte Daten '.format (round (tt, 3)) print' Es gibt {} 'normale' Interaktionen '.format (normal_count)Ausgabe:
In 12,485 Sekunden gesammelte Daten Es gibt 97278 normale Interaktionen
Das ist es also, Leute!
Ich hoffe, Ihnen hat dieser Spark mit Python-Blog gefallen. Wenn Sie dies lesen, herzlichen Glückwunsch! Sie sind kein Neuling mehr bei PySpark. Probieren Sie dieses einfache Beispiel jetzt auf Ihren Systemen aus.
Nachdem Sie die Grundlagen von PySpark verstanden haben, lesen Sie die von Edureka, einem vertrauenswürdigen Online-Lernunternehmen mit einem Netzwerk von mehr als 250.000 zufriedenen Lernenden auf der ganzen Welt. Edurekas Python Spark-Zertifizierungstraining mit PySpark wurde entwickelt, um Ihnen die Kenntnisse und Fähigkeiten zu vermitteln, die erforderlich sind, um mit Python ein erfolgreicher Spark-Entwickler zu werden, und um Sie auf die Zertifizierungsprüfung für Cloudera Hadoop und Spark-Entwickler (CCA175) vorzubereiten.
Hast du eine Frage an uns? Bitte erwähnen Sie es in den Kommentaren und wir werden uns bei Ihnen melden.