
Struktur eines Java-Programms
Apache HBase ist eine verteilte, nicht relationale Open-Source-Datenbank, die dem Bigtable von Google nachempfunden und in Java geschrieben ist. Es bietet ähnliche Funktionen wie Bigtable auf Hadoop und HDFS (Hadoop Distributed Filesystem), d. H. Es bietet eine fehlertolerante Möglichkeit zum Speichern großer Mengen spärlicher Daten, die in vielen Big-Data-Anwendungsfällen üblich sind. HBase wird für den Echtzeit-Lese- / Schreibzugriff auf Big Data verwendet.
Die HBase-Speicherarchitektur umfasst zahlreiche Komponenten. Schauen wir uns die Funktionen dieser Komponenten an und wissen, wie Daten geschrieben werden.
HFiles:
HFiles bildet das niedrige Niveau der HBase-Architektur. HFiles sind Speicherdateien, die erstellt wurden, um die Daten von HBase schnell und effizient zu speichern.
HMaster:
Der HMaster ist dafür verantwortlich, die Regionen jedem HRegionServer zuzuweisen, wenn HBase gestartet wird. Es ist für die Verwaltung aller Zeilen, Tabellen und deren Koordinierungsaktivitäten verantwortlich. Der Hmaster hat auch die Details der Metadaten.
Komponenten von HBase:
HBase hat folgende Komponenten:
- Tabelle - Enthält Regionen
- Region - Bereich der zusammen gespeicherten Zeilen
- Regionsserver - Bedient eine oder mehrere Regionen
- Master Server - Daemon ist für die Verwaltung des HBase-Clusters verantwortlich
Die HBase speichert Daten direkt im HDFS und ist in hohem Maße auf die Hochverfügbarkeit und Fehlertoleranz von HDFS angewiesen.
HBase-Speicherarchitektur:
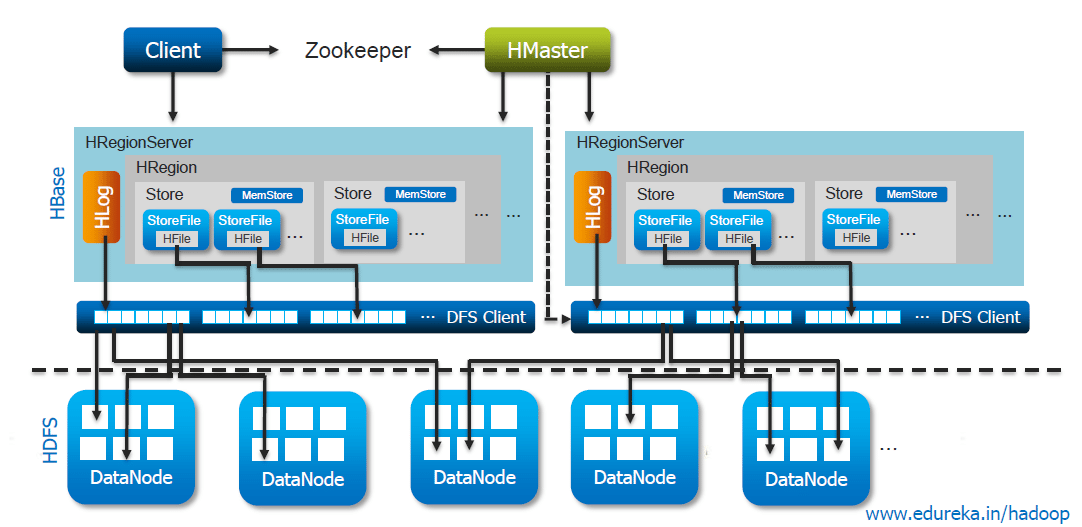
Der allgemeine Ablauf besteht darin, dass ein Client zuerst den Zookeeper kontaktiert, um einen bestimmten Zeilenschlüssel zu finden. Dazu wird der Servername von Zookeeper abgerufen. Mit diesen Informationen kann es nun diesen Server abfragen, um den Server zu erhalten, der die Metatabelle enthält. Beide Details werden zwischengespeichert und nur einmal nachgeschlagen. Zuletzt kann es den Metaserver abfragen und den Server abrufen, der die Zeile enthält, nach der der Client sucht.
Sobald bekannt ist, in welcher Region sich die Zeile befindet, werden diese Informationen ebenfalls zwischengespeichert und der HRegionServer direkt kontaktiert. Im Laufe der Zeit verfügt der Client über vollständige Informationen darüber, woher Zeilen abgerufen werden können, ohne dass der Metaserver erneut abgefragt werden muss. Wenn die HRegion geöffnet wird, wird für jede HColumnFamily für jede Tabelle eine Store-Instanz eingerichtet. Daten werden geschrieben, wenn der Client eine Anfrage an den HRegionServer sendet, der die Details für die übereinstimmende HRegion-Instanz bereitstellt. Der erste Schritt besteht darin, dass wir entscheiden müssen, ob die Daten zuerst in das von der HLog-Klasse dargestellte 'Write-Ahead-Log' (WAL) geschrieben werden sollen. Die Entscheidung basiert auf dem vom Kunden gesetzten Flag.
Sobald die Daten in die WAL geschrieben wurden, werden sie im MemStore abgelegt. Gleichzeitig wird der Memstore überprüft, ob er voll ist, und in diesem Fall wird ein Flush auf die Festplatte angefordert. Dann werden die Daten in die HFile geschrieben.
Hast du eine Frage an uns? Erwähnen Sie sie im Kommentarbereich und wir werden uns bei Ihnen melden.
zusammenhängende Posts
Einblicke in die HBase-Architektur