
Python, das Ende der 1980er Jahre von Guido van Rossum entwickelt wurde, ist eine universelle Programmiersprache auf hoher Ebene, die Wert auf Lesbarkeit des Codes und einfache Syntax legt. Schauen wir uns an, wie Python mit Big Data zurechtkommt!
Python für Big Data
In der Regel war die einfache Syntax und die schrittweise Lernkurve von Python einer der beliebtesten Gründe für die Verwendung in Big Data. Es wäre interessant zu wissen, dass Praktikanten in Organisationen aktiv daran arbeiten, neuen Mitarbeitern die Sprache beizubringen. Um detaillierte Informationen zu Python und seinen verschiedenen Anwendungen zu erhalten, können Sie sich live anmelden mit 24/7 Support und lebenslangem Zugriff.
AppNexus, einer der treuen Benutzer von Python,'' Wir konnten ein Framework erstellen, mit dem wir Daten aus all diesen unterschiedlichen Datenquellen einfach abrufen und modellieren können. Anstatt dass jeder seine Zeit damit verbringt, Datenbank-Connector-Code zu schreiben, können sie eine einfache Konfiguration verwenden und schnell loslegen. “
Anschließend können Unternehmen mit Python Code schneller von der Entwicklung in die Produktion verschieben, da derselbe Code, der als Prototyp erstellt wurde, in die Produktion verschoben werden kann.
Wir alle wissen, dass Hadoop eine wichtige Technologie ist, die als Big eine enorme Popularität erlangt hatDatenlösung, aberWussten Sie, dass Python zum Schreiben verwendet wird?HadoopsMapReduce-Programme und -Anwendungen für den Zugriff auf die HDFS-API für Hadoop mit PyDoop-Paketen?
wie man einen Screenshot in Selen macht
Schauen wir uns PyDoop an, ein Anwendungspaket, das eine Python-API für MapReduce und HDFS von Hadoop bereitstellt. PyDoop ist möglicherweise eine der wichtigsten Verbindungen zwischen Python und Big Data und bietet mehrere Vorteile gegenüber den in Hadoop integrierten Lösungen für die Python-Programmierung, zu denen auch Hadoop Streaming gehört.
Der größte Vorteil von PyDoop ist die HDFS-API. Auf diese Weise können Sie eine Verbindung zu einer HDFS-Installation herstellen, Dateien lesen und schreiben sowie Informationen zu Dateien, Verzeichnissen und globalen Dateisystemeigenschaften abrufen.
Mit der MapReduce-API von PyDoop können viele komplexe Probleme mit minimalem Programmieraufwand gelöst werden. Erweiterte MapReduce-Konzepte wie 'Zähler' und 'Datensatzleser' können mit PyDoop in Python implementiert werden.
Python-Trends heute
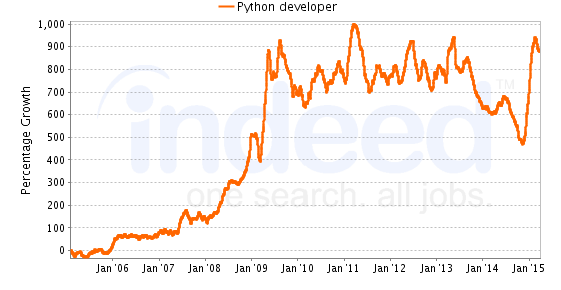
Gemäß den Jobtrends auf Indeed.com nimmt die Kombination von Python und R mit Big Data stetig zu. Bei vielen Unternehmen, die nach Big Data-Analysen suchen, scheint Python-Training ein Muss in Ihrem Lebenslauf zu sein. Python ist bei einigen der drei mit Abstand am gefragtesten 27.000 Arbeitsplätze im Bereich Big Data (Quelle - Info-Welt). Python for Big Data Training qualifiziert Sie automatisch für diese Jobs.
Was ist Sqoop in Hadoop
Wenn Sie das Python-Training absolvieren, können Sie innerhalb kurzer Zeit hochbezahlte Jobs finden. Mit vielen weiteren JobsGroße Daten,Das Python-Training macht Sie zum idealen Kandidaten.
Trotz seiner Einfachheit ist Python äußerst leistungsfähig, um komplexe und schwierige Datenanalyseprobleme in praktisch jeder Domäne zu lösen. Python ist plattformunabhängig und kann daher in die meisten vorhandenen IT-Umgebungen integriert werden. Python hat hohe Fähigkeiten fürGroße DatenManipulationsaufgaben und seine natürliche Stärke als Skriptsprache machen es sehr anpassungsfähig für datenorientierte Anwendungen. Kein Wunder, dass Unternehmen aller Größen und Branchen unterschiedliche Python-Funktionen verwenden, um ihre Daten zu verwaltenGroße DatenAnforderungen. Da Unternehmen weiterhin die Macht von Python für nutzenGroße DatenBei der Verarbeitung hilft Ihnen das Python-Training dabei, Ihre Fähigkeiten zu verbessernGroße DatenAnalytik.
Hast du eine Frage an uns? Erwähnen Sie sie im Kommentarbereich und wir werden uns bei Ihnen melden.
Zusammenhängende Posts:
def __init__ python